 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretability of Blackbox Machine Learning Models through Dataview Extraction and Shadow Model creation
Feb 02, 2020

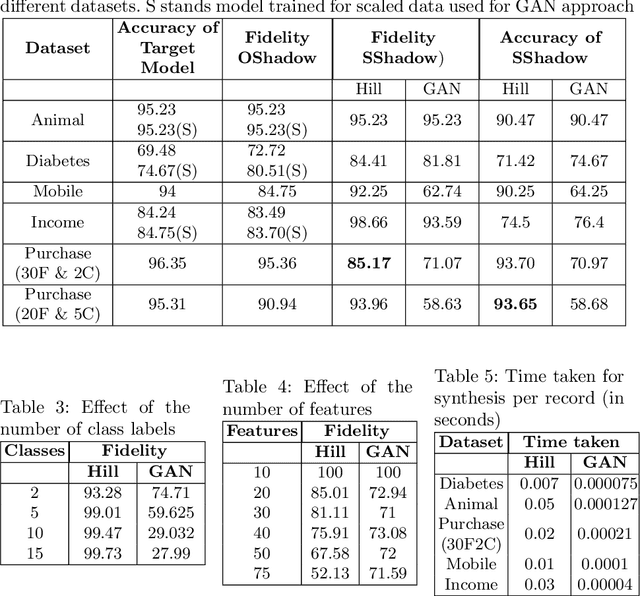

Deep learning models trained using massive amounts of data tend to capture one view of the data and its associated mapping. Different deep learning models built on the same training data may capture different views of the data based on the underlying techniques used. For explaining the decisions arrived by blackbox deep learning models, we argue that it is essential to reproduce that model's view of the training data faithfully. This faithful reproduction can then be used for explanation generation. We investigate two methods for data view extraction: hill-climbing approach and a GAN-driven approach. We then use this synthesized data for creating shadow models for explanation generation: Decision-Tree model and Formal Concept Analysis based model. We evaluate these approaches on a Blackbox model trained on public datasets and show its usefulness in explanation generation.
Learning Latent Beliefs and Performing Epistemic Reasoning for Efficient and Meaningful Dialog Management
Nov 26, 2018
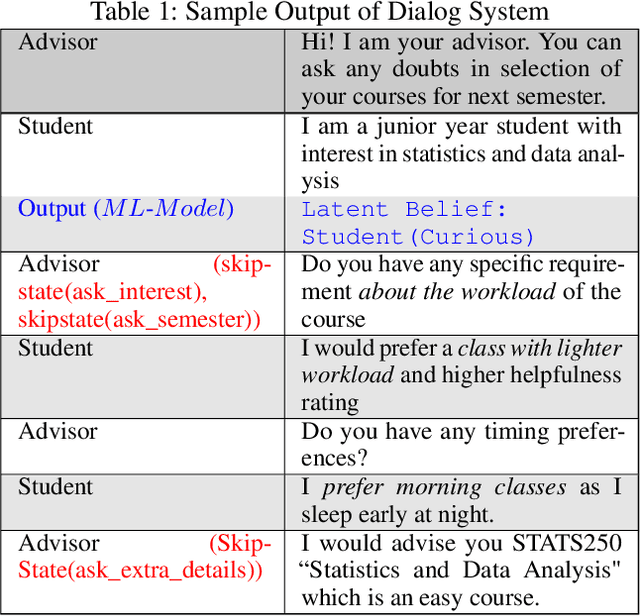
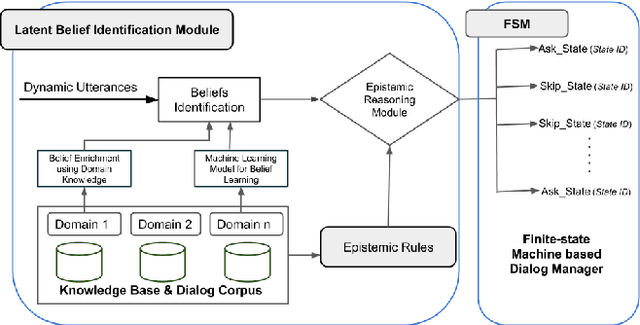

Many dialogue management frameworks allow the system designer to directly define belief rules to implement an efficient dialog policy. Because these rules are directly defined, the components are said to be hand-crafted. As dialogues become more complex, the number of states, transitions, and policy decisions becomes very large. To facilitate the dialog policy design process, we propose an approach to automatically learn belief rules using a supervised machine learning approach. We validate our ideas in Student-Advisor conversation domain, where we extract latent beliefs like student is \textit{curious, confused and neutral}, etc. Further, we also perform epistemic reasoning that helps to tailor the dialog according to student's emotional state and hence improve the overall effectiveness of the dialog system. Our latent belief identification approach shows an accuracy of 87\% and this results in efficient and meaningful dialog management.
Adapting general-purpose speech recognition engine output for domain-specific natural language question answering
Oct 12, 2017


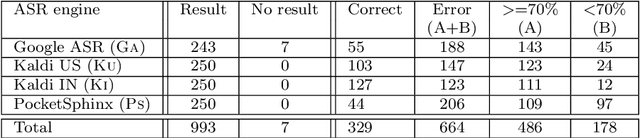
Speech-based natural language question-answering interfaces to enterprise systems are gaining a lot of attention. General-purpose speech engines can be integrated with NLP systems to provide such interfaces. Usually, general-purpose speech engines are trained on large `general' corpus. However, when such engines are used for specific domains, they may not recognize domain-specific words well, and may produce erroneous output. Further, the accent and the environmental conditions in which the speaker speaks a sentence may induce the speech engine to inaccurately recognize certain words. The subsequent natural language question-answering does not produce the requisite results as the question does not accurately represent what the speaker intended. Thus, the speech engine's output may need to be adapted for a domain before further natural language processing is carried out. We present two mechanisms for such an adaptation, one based on evolutionary development and the other based on machine learning, and show how we can repair the speech-output to make the subsequent natural language question-answering better.