 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Few-shot Transfer Learning for Knowledge Base Question Answering with Unanswerable Questions
Jun 20, 2024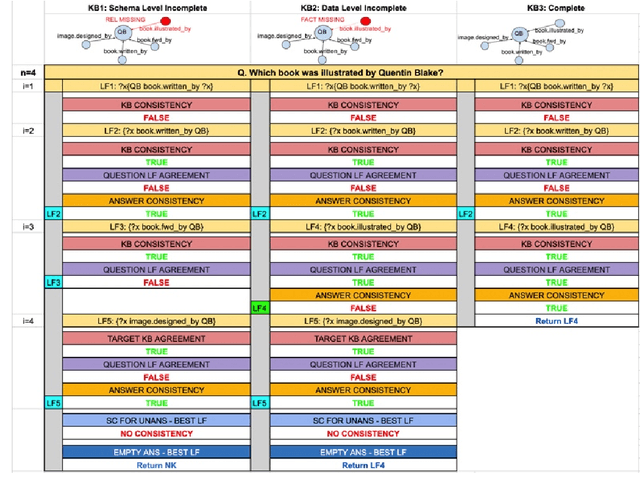


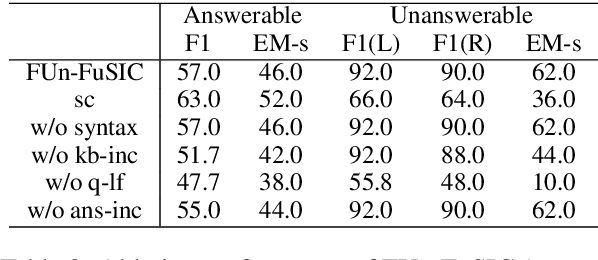
Real-world KBQA applications require models that are (1) robust -- e.g., can differentiate between answerable and unanswerable questions, and (2) low-resource -- do not require large training data. Towards this goal, we propose the novel task of few-shot transfer for KBQA with unanswerable questions. We present FUn-FuSIC that extends the state-of-the-art (SoTA) few-shot transfer model for answerable-only KBQA to handle unanswerability. It iteratively prompts an LLM to generate logical forms for the question by providing feedback using a diverse suite of syntactic, semantic and execution guided checks, and adapts self-consistency to assess confidence of the LLM to decide answerability. Experiments over newly constructed datasets show that FUn-FuSIC outperforms suitable adaptations of the SoTA model for KBQA with unanswerability, and the SoTA model for answerable-only few-shot-transfer KBQA.
RETINAQA : A Knowledge Base Question Answering Model Robust to both Answerable and Unanswerable Questions
Mar 16, 2024



State-of-the-art KBQA models assume answerability of questions. Recent research has shown that while these can be adapted to detect unaswerability with suitable training and thresholding, this comes at the expense of accuracy for answerable questions, and no single model is able to handle all categories of unanswerability. We propose a new model for KBQA named RetinaQA that is robust against unaswerability. It complements KB-traversal based logical form retrieval with sketch-filling based logical form construction. This helps with questions that have valid logical forms but no data paths in the KB leading to an answer. Additionally, it uses discrimination instead of generation to better identify questions that do not have valid logical forms. We demonstrate that RetinaQA significantly outperforms adaptations of state-of-the-art KBQA models across answerable and unanswerable questions, while showing robustness across unanswerability categories. Remarkably, it also establishes a new state-of-the art for answerable KBQA by surpassing existing models
Combining Transfer Learning with In-context Learning using Blackbox LLMs for Zero-shot Knowledge Base Question Answering
Nov 15, 2023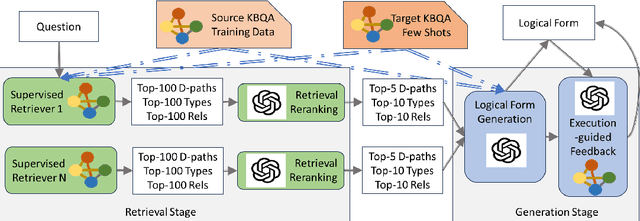

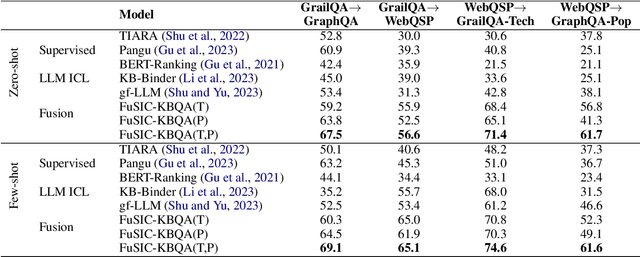
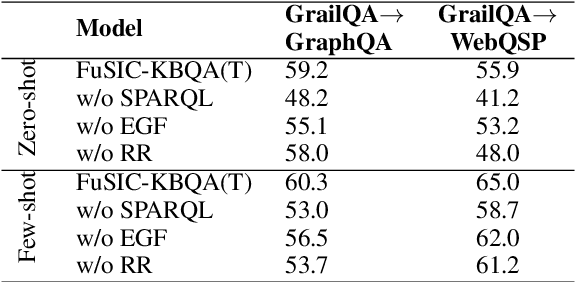
We address the zero-shot transfer learning setting for the knowledge base question answering (KBQA) problem, where a large volume of labeled training data is available for the source domain, but no such labeled examples are available for the target domain. Transfer learning for KBQA makes use of large volumes of unlabeled data in the target in addition to the labeled data in the source. More recently, few-shot in-context learning using Black-box Large Language Models (BLLMs) has been adapted for KBQA without considering any source domain data. In this work, we show how to meaningfully combine these two paradigms for KBQA so that their benefits add up. Specifically, we preserve the two stage retrieve-then-generate pipeline of supervised KBQA and introduce interaction between in-context learning using BLLMs and transfer learning from the source for both stages. In addition, we propose execution-guided self-refinement using BLLMs, decoupled from the transfer setting. With the help of experiments using benchmark datasets GrailQA as the source and WebQSP as the target, we show that the proposed combination brings significant improvements to both stages and also outperforms by a large margin state-of-the-art supervised KBQA models trained on the source. We also show that in the in-domain setting, the proposed BLLM augmentation significantly outperforms state-of-the-art supervised models, when the volume of labeled data is limited, and also outperforms these marginally even when using the entire large training dataset.
Adapting Pre-trained Generative Models for Extractive Question Answering
Nov 06, 2023Pre-trained Generative models such as BART, T5, etc. have gained prominence as a preferred method for text generation in various natural language processing tasks, including abstractive long-form question answering (QA) and summarization. However, the potential of generative models in extractive QA tasks, where discriminative models are commonly employed, remains largely unexplored. Discriminative models often encounter challenges associated with label sparsity, particularly when only a small portion of the context contains the answer. The challenge is more pronounced for multi-span answers. In this work, we introduce a novel approach that uses the power of pre-trained generative models to address extractive QA tasks by generating indexes corresponding to context tokens or sentences that form part of the answer. Through comprehensive evaluations on multiple extractive QA datasets, including MultiSpanQA, BioASQ, MASHQA, and WikiQA, we demonstrate the superior performance of our proposed approach compared to existing state-of-the-art models.
Do the Benefits of Joint Models for Relation Extraction Extend to Document-level Tasks?
Oct 01, 2023



Two distinct approaches have been proposed for relational triple extraction - pipeline and joint. Joint models, which capture interactions across triples, are the more recent development, and have been shown to outperform pipeline models for sentence-level extraction tasks. Document-level extraction is a more challenging setting where interactions across triples can be long-range, and individual triples can also span across sentences. Joint models have not been applied for document-level tasks so far. In this paper, we benchmark state-of-the-art pipeline and joint extraction models on sentence-level as well as document-level datasets. Our experiments show that while joint models outperform pipeline models significantly for sentence-level extraction, their performance drops sharply below that of pipeline models for the document-level dataset.
A Two-step Approach for Handling Zero-Cardinality in Relation Extraction
Feb 20, 2023



Relation tuple extraction from text is an important task for building knowledge bases. Recently, joint entity and relation extraction models have achieved very high F1 scores in this task. However, the experimental settings used by these models are restrictive and the datasets used in the experiments are not realistic. They do not include sentences with zero tuples (zero-cardinality). In this paper, we evaluate the state-of-the-art joint entity and relation extraction models in a more realistic setting. We include sentences that do not contain any tuples in our experiments. Our experiments show that there is significant drop ($\sim 10-15\%$ in one dataset and $\sim 6-14\%$ in another dataset) in their F1 score in this setting. We also propose a two-step modeling using a simple BERT-based classifier that leads to improvement in the overall performance of these models in this realistic experimental setup.
Do I have the Knowledge to Answer? Investigating Answerability of Knowledge Base Questions
Dec 20, 2022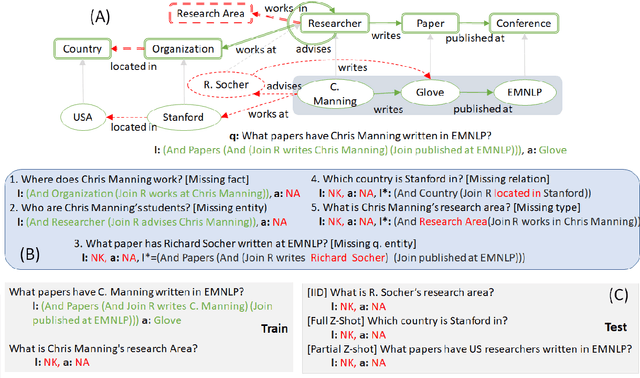

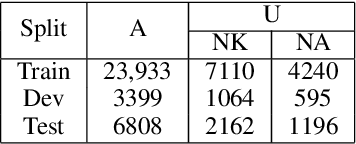
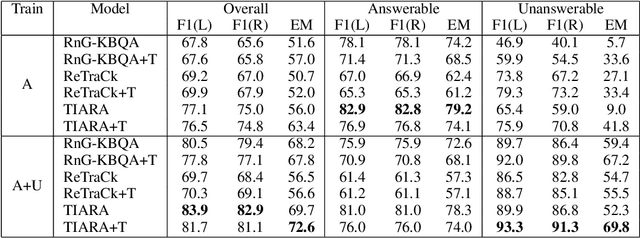
When answering natural language questions over knowledge bases (KBs), incompleteness in the KB can naturally lead to many questions being unanswerable. While answerability has been explored in other QA settings, it has not been studied for QA over knowledge bases (KBQA). We first identify various forms of KB incompleteness that can result in a question being unanswerable. We then propose GrailQAbility, a new benchmark dataset, which systematically modifies GrailQA (a popular KBQA dataset) to represent all these incompleteness issues. Testing two state-of-the-art KBQA models (trained on original GrailQA as well as our GrailQAbility), we find that both models struggle to detect unanswerable questions, or sometimes detect them for the wrong reasons. Consequently, both models suffer significant loss in performance, underscoring the need for further research in making KBQA systems robust to unanswerability.
Enabling human-like task identification from natural conversation
Aug 29, 2020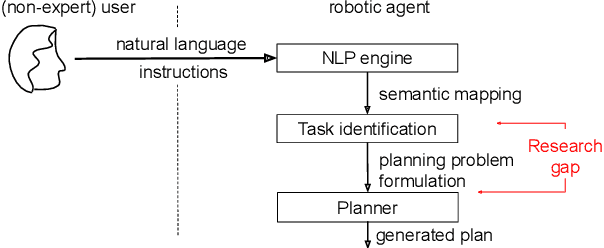
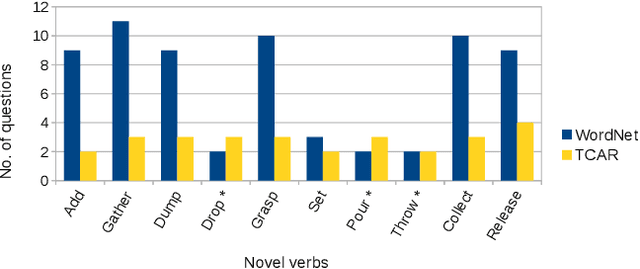
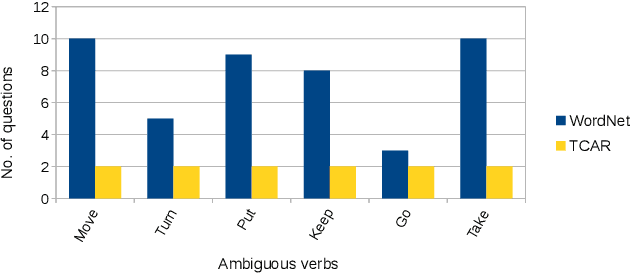
A robot as a coworker or a cohabitant is becoming mainstream day-by-day with the development of low-cost sophisticated hardware. However, an accompanying software stack that can aid the usability of the robotic hardware remains the bottleneck of the process, especially if the robot is not dedicated to a single job. Programming a multi-purpose robot requires an on the fly mission scheduling capability that involves task identification and plan generation. The problem dimension increases if the robot accepts tasks from a human in natural language. Though recent advances in NLP and planner development can solve a variety of complex problems, their amalgamation for a dynamic robotic task handler is used in a limited scope. Specifically, the problem of formulating a planning problem from natural language instructions is not studied in details. In this work, we provide a non-trivial method to combine an NLP engine and a planner such that a robot can successfully identify tasks and all the relevant parameters and generate an accurate plan for the task. Additionally, some mechanism is required to resolve the ambiguity or missing pieces of information in natural language instruction. Thus, we also develop a dialogue strategy that aims to gather additional information with minimal question-answer iterations and only when it is necessary. This work makes a significant stride towards enabling a human-like task understanding capability in a robot.
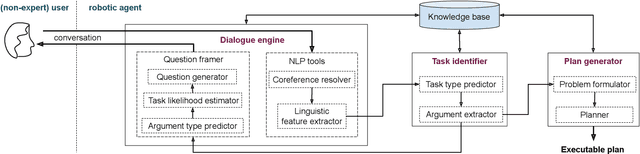
Your instruction may be crisp, but not clear to me!
Aug 23, 2020

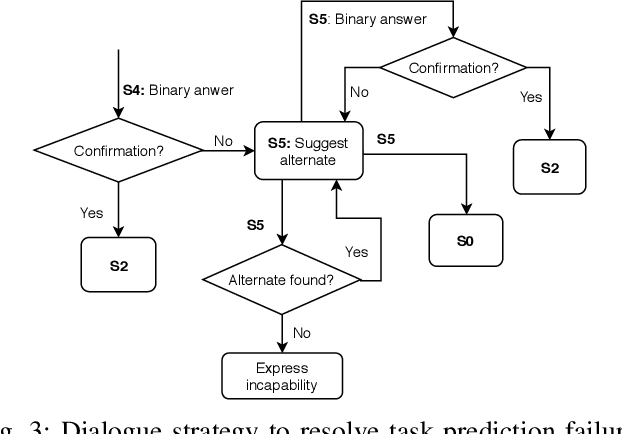

The number of robots deployed in our daily surroundings is ever-increasing. Even in the industrial set-up, the use of coworker robots is increasing rapidly. These cohabitant robots perform various tasks as instructed by co-located human beings. Thus, a natural interaction mechanism plays a big role in the usability and acceptability of the robot, especially by a non-expert user. The recent development in natural language processing (NLP) has paved the way for chatbots to generate an automatic response for users' query. A robot can be equipped with such a dialogue system. However, the goal of human-robot interaction is not focused on generating a response to queries, but it often involves performing some tasks in the physical world. Thus, a system is required that can detect user intended task from the natural instruction along with the set of pre- and post-conditions. In this work, we develop a dialogue engine for a robot that can classify and map a task instruction to the robot's capability. If there is some ambiguity in the instructions or some required information is missing, which is often the case in natural conversation, it asks an appropriate question(s) to resolve it. The goal is to generate minimal and pin-pointed queries for the user to resolve an ambiguity. We evaluate our system for a telepresence scenario where a remote user instructs the robot for various tasks. Our study based on 12 individuals shows that the proposed dialogue strategy can help a novice user to effectively interact with a robot, leading to satisfactory user experience.
Discovering Topical Interactions in Text-based Cascades using Hidden Markov Hawkes Processes
Sep 12, 2018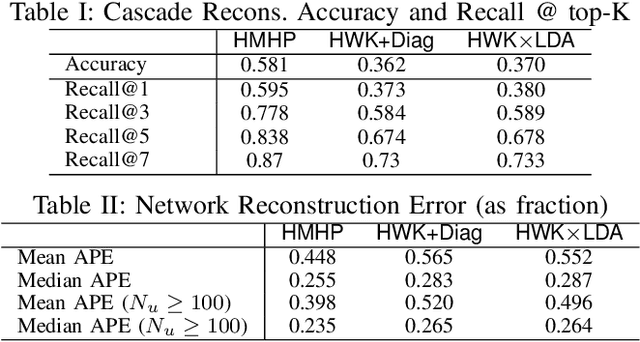
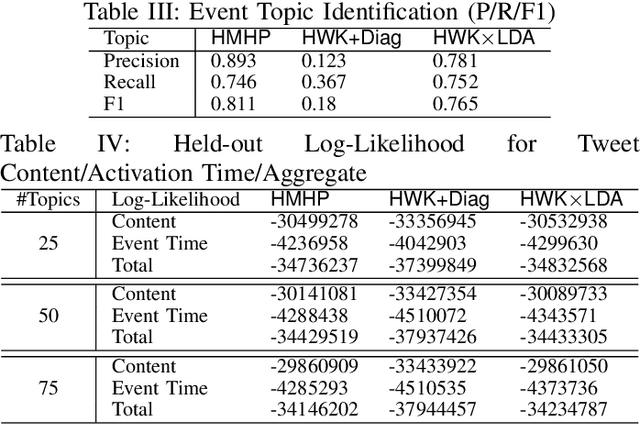
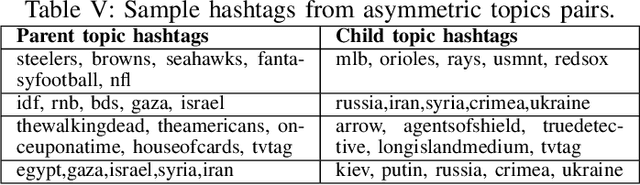
Social media conversations unfold based on complex interactions between users, topics and time. While recent models have been proposed to capture network strengths between users, users' topical preferences and temporal patterns between posting and response times, interaction patterns between topics has not been studied. We propose the Hidden Markov Hawkes Process (HMHP) that incorporates topical Markov Chains within Hawkes processes to jointly model topical interactions along with user-user and user-topic patterns. We propose a Gibbs sampling algorithm for HMHP that jointly infers the network strengths, diffusion paths, the topics of the posts as well as the topic-topic interactions. We show using experiments on real and semi-synthetic data that HMHP is able to generalize better and recover the network strengths, topics and diffusion paths more accurately than state-of-the-art baselines. More interestingly, HMHP finds insightful interactions between topics in real tweets which no existing model is able to do.