 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRETINAQA : A Knowledge Base Question Answering Model Robust to both Answerable and Unanswerable Questions
Mar 16, 2024



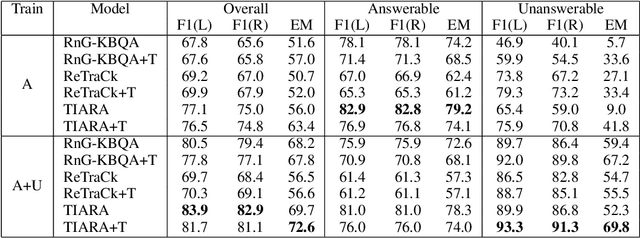
State-of-the-art KBQA models assume answerability of questions. Recent research has shown that while these can be adapted to detect unaswerability with suitable training and thresholding, this comes at the expense of accuracy for answerable questions, and no single model is able to handle all categories of unanswerability. We propose a new model for KBQA named RetinaQA that is robust against unaswerability. It complements KB-traversal based logical form retrieval with sketch-filling based logical form construction. This helps with questions that have valid logical forms but no data paths in the KB leading to an answer. Additionally, it uses discrimination instead of generation to better identify questions that do not have valid logical forms. We demonstrate that RetinaQA significantly outperforms adaptations of state-of-the-art KBQA models across answerable and unanswerable questions, while showing robustness across unanswerability categories. Remarkably, it also establishes a new state-of-the art for answerable KBQA by surpassing existing models
Do I have the Knowledge to Answer? Investigating Answerability of Knowledge Base Questions
Dec 20, 2022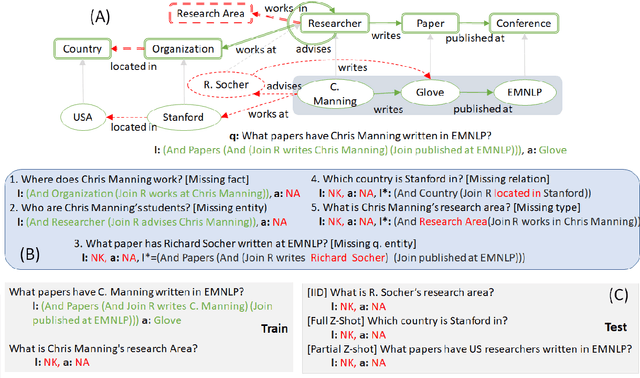

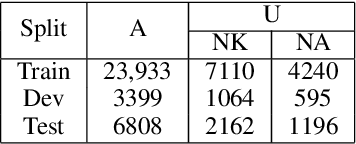
When answering natural language questions over knowledge bases (KBs), incompleteness in the KB can naturally lead to many questions being unanswerable. While answerability has been explored in other QA settings, it has not been studied for QA over knowledge bases (KBQA). We first identify various forms of KB incompleteness that can result in a question being unanswerable. We then propose GrailQAbility, a new benchmark dataset, which systematically modifies GrailQA (a popular KBQA dataset) to represent all these incompleteness issues. Testing two state-of-the-art KBQA models (trained on original GrailQA as well as our GrailQAbility), we find that both models struggle to detect unanswerable questions, or sometimes detect them for the wrong reasons. Consequently, both models suffer significant loss in performance, underscoring the need for further research in making KBQA systems robust to unanswerability.