 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo I have the Knowledge to Answer? Investigating Answerability of Knowledge Base Questions
Paper and Code
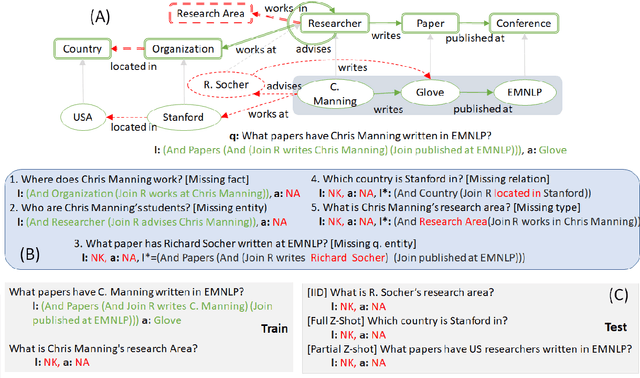

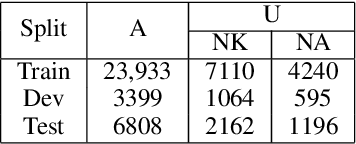
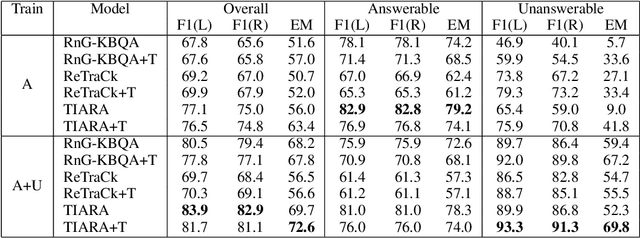
When answering natural language questions over knowledge bases (KBs), incompleteness in the KB can naturally lead to many questions being unanswerable. While answerability has been explored in other QA settings, it has not been studied for QA over knowledge bases (KBQA). We first identify various forms of KB incompleteness that can result in a question being unanswerable. We then propose GrailQAbility, a new benchmark dataset, which systematically modifies GrailQA (a popular KBQA dataset) to represent all these incompleteness issues. Testing two state-of-the-art KBQA models (trained on original GrailQA as well as our GrailQAbility), we find that both models struggle to detect unanswerable questions, or sometimes detect them for the wrong reasons. Consequently, both models suffer significant loss in performance, underscoring the need for further research in making KBQA systems robust to unanswerability.