 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept-based Anomaly Detection in Retail Stores for Automatic Correction using Mobile Robots
Oct 21, 2023
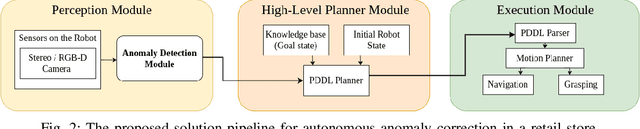

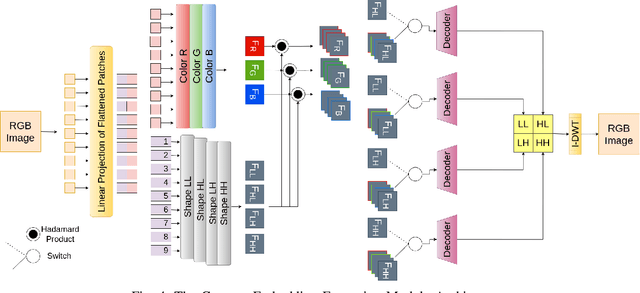
Tracking of inventory and rearrangement of misplaced items are some of the most labor-intensive tasks in a retail environment. While there have been attempts at using vision-based techniques for these tasks, they mostly use planogram compliance for detection of any anomalies, a technique that has been found lacking in robustness and scalability. Moreover, existing systems rely on human intervention to perform corrective actions after detection. In this paper, we present Co-AD, a Concept-based Anomaly Detection approach using a Vision Transformer (ViT) that is able to flag misplaced objects without using a prior knowledge base such as a planogram. It uses an auto-encoder architecture followed by outlier detection in the latent space. Co-AD has a peak success rate of 89.90% on anomaly detection image sets of retail objects drawn from the RP2K dataset, compared to 80.81% on the best-performing baseline of a standard ViT auto-encoder. To demonstrate its utility, we describe a robotic mobile manipulation pipeline to autonomously correct the anomalies flagged by Co-AD. This work is ultimately aimed towards developing autonomous mobile robot solutions that reduce the need for human intervention in retail store management.
Challenges in Applying Robotics to Retail Store Management
Aug 18, 2022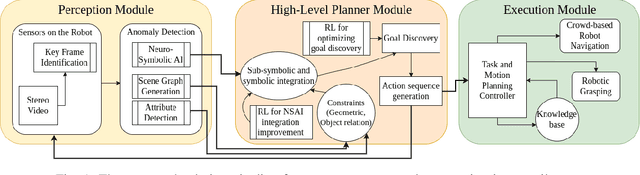
An autonomous retail store management system entails inventory tracking, store monitoring, and anomaly correction. Recent attempts at autonomous retail store management have faced challenges primarily in perception for anomaly detection, as well as new challenges arising in mobile manipulation for executing anomaly correction. Advances in each of these areas along with system integration are necessary for a scalable solution in this domain.
SCNet: A Generalized Attention-based Model for Crack Fault Segmentation
Dec 02, 2021
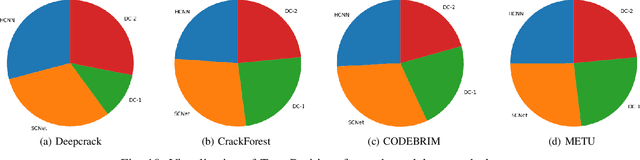
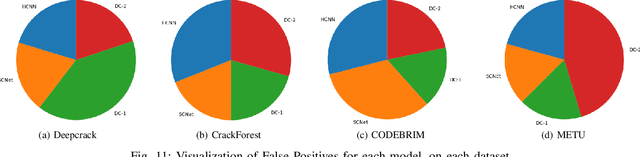
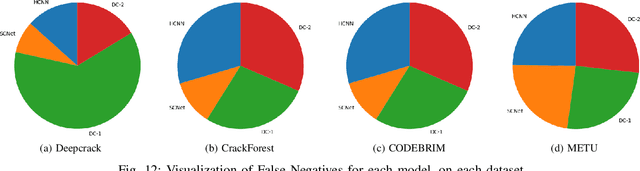
Anomaly detection and localization is an important vision problem, having multiple applications. Effective and generic semantic segmentation of anomalous regions on various different surfaces, where most anomalous regions inherently do not have any obvious pattern, is still under active research. Periodic health monitoring and fault (anomaly) detection in vast infrastructures, which is an important safety-related task, is one such application area of vision-based anomaly segmentation. However, the task is quite challenging due to large variations in surface faults, texture-less construction material/background, lighting conditions etc. Cracks are critical and frequent surface faults that manifest as extreme zigzag-shaped thin, elongated regions. They are among the hardest faults to detect, even with deep learning. In this work, we address an open aspect of automatic crack segmentation problem, that of generalizing and improving the performance of segmentation across a variety of scenarios, by modeling the problem differently. We carefully study and abstract the sub-problems involved and solve them in a broader context, making our solution generic. On a variety of datasets related to surveillance of different infrastructures, under varying conditions, our model consistently outperforms the state-of-the-art algorithms by a significant margin, without any bells-and-whistles. This performance advantage easily carried over in two deployments of our model, tested against industry-provided datasets. Even further, we could establish our model's performance for two manufacturing quality inspection scenarios as well, where the defect types are not just crack equivalents, but much more and different. Hence we hope that our model is indeed a truly generic defect segmentation model.
Enabling human-like task identification from natural conversation
Aug 29, 2020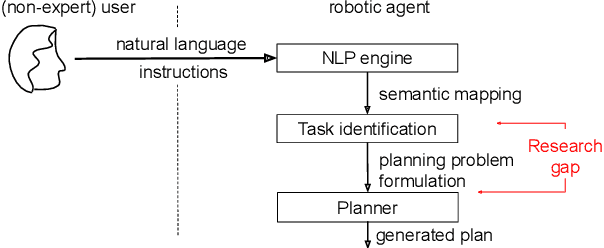
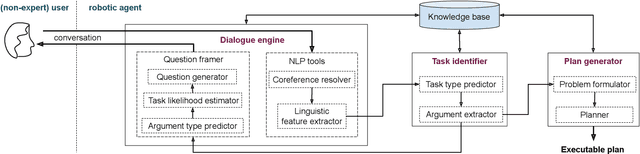
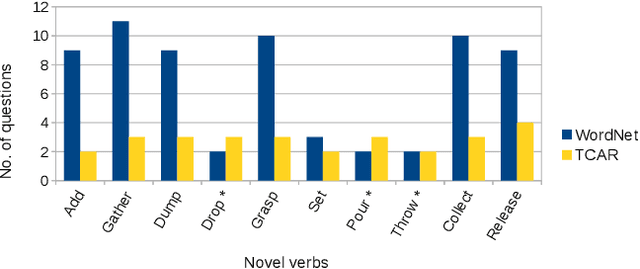
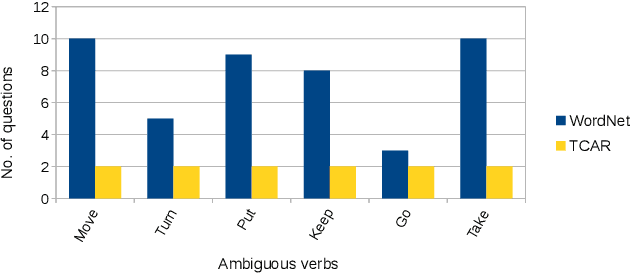
A robot as a coworker or a cohabitant is becoming mainstream day-by-day with the development of low-cost sophisticated hardware. However, an accompanying software stack that can aid the usability of the robotic hardware remains the bottleneck of the process, especially if the robot is not dedicated to a single job. Programming a multi-purpose robot requires an on the fly mission scheduling capability that involves task identification and plan generation. The problem dimension increases if the robot accepts tasks from a human in natural language. Though recent advances in NLP and planner development can solve a variety of complex problems, their amalgamation for a dynamic robotic task handler is used in a limited scope. Specifically, the problem of formulating a planning problem from natural language instructions is not studied in details. In this work, we provide a non-trivial method to combine an NLP engine and a planner such that a robot can successfully identify tasks and all the relevant parameters and generate an accurate plan for the task. Additionally, some mechanism is required to resolve the ambiguity or missing pieces of information in natural language instruction. Thus, we also develop a dialogue strategy that aims to gather additional information with minimal question-answer iterations and only when it is necessary. This work makes a significant stride towards enabling a human-like task understanding capability in a robot.
Demo: Edge-centric Telepresence Avatar Robot for Geographically Distributed Environment
Jul 25, 2020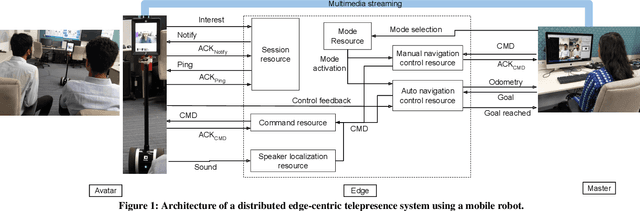
Using a robotic platform for telepresence applications has gained paramount importance in this decade. Scenarios such as remote meetings, group discussions, and presentations/talks in seminars and conferences get much attention in this regard. Though there exist some robotic platforms for such telepresence applications, they lack efficacy in communication and interaction between the remote person and the avatar robot deployed in another geographic location. Also, such existing systems are often cloud-centric which adds to its network overhead woes. In this demo, we develop and test a framework that brings the best of both cloud and edge-centric systems together along with a newly designed communication protocol. Our solution adds to the improvement of the existing systems in terms of robustness and efficacy in communication for a geographically distributed environment.
I can attend a meeting too! Towards a human-like telepresence avatar robot to attend meeting on your behalf
Jun 28, 2020
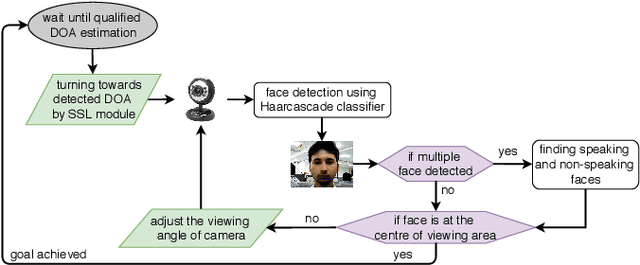
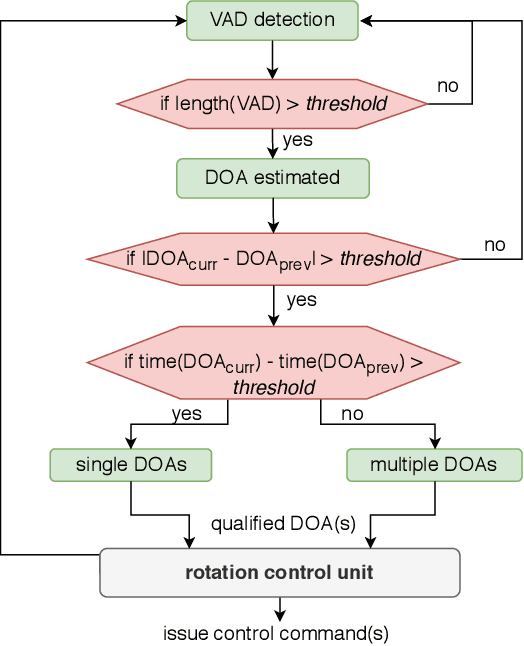
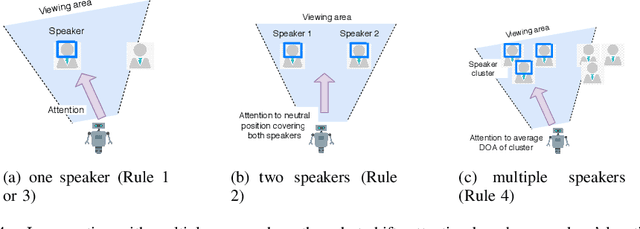
Telepresence robots are used in various forms in various use-cases that helps to avoid physical human presence at the scene of action. In this work, we focus on a telepresence robot that can be used to attend a meeting remotely with a group of people. Unlike a one-to-one meeting, participants in a group meeting can be located at a different part of the room, especially in an informal setup. As a result, all of them may not be at the viewing angle of the robot, a.k.a. the remote participant. In such a case, to provide a better meeting experience, the robot should localize the speaker and bring the speaker at the center of the viewing angle. Though sound source localization can easily be done using a microphone-array, bringing the speaker or set of speakers at the viewing angle is not a trivial task. First of all, the robot should react only to a human voice, but not to the random noises. Secondly, if there are multiple speakers, to whom the robot should face or should it rotate continuously with every new speaker? Lastly, most robotic platforms are resource-constrained and to achieve a real-time response, i.e., avoiding network delay, all the algorithms should be implemented within the robot itself. This article presents a study and implementation of an attention shifting scheme in a telepresence meeting scenario which best suits the needs and expectations of the collocated and remote attendees. We define a policy to decide when a robot should rotate and how much based on real-time speaker localization. Using user satisfaction study, we show the efficacy and usability of our system in the meeting scenario. Moreover, our system can be easily adapted to other scenarios where multiple people are located.