 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIZOR: Viewpoint-Invariant Zero-Shot Scene Graph Generation for 3D Scene Reasoning
Jan 31, 2026Scene understanding and reasoning has been a fundamental problem in 3D computer vision, requiring models to identify objects, their properties, and spatial or comparative relationships among the objects. Existing approaches enable this by creating scene graphs using multiple inputs such as 2D images, depth maps, object labels, and annotated relationships from specific reference view. However, these methods often struggle with generalization and produce inaccurate spatial relationships like "left/right", which become inconsistent across different viewpoints. To address these limitations, we propose Viewpoint-Invariant Zero-shot scene graph generation for 3D scene Reasoning (VIZOR). VIZOR is a training-free, end-to-end framework that constructs dense, viewpoint-invariant 3D scene graphs directly from raw 3D scenes. The generated scene graph is unambiguous, as spatial relationships are defined relative to each object's front-facing direction, making them consistent regardless of the reference view. Furthermore, it infers open-vocabulary relationships that describe spatial and proximity relationships among scene objects without requiring annotated training data. We conduct extensive quantitative and qualitative evaluations to assess the effectiveness of VIZOR in scene graph generation and downstream tasks, such as query-based object grounding. VIZOR outperforms state-of-the-art methods, showing clear improvements in scene graph generation and achieving 22% and 4.81% gains in zero-shot grounding accuracy on the Replica and Nr3D datasets, respectively.
Concept-based Anomaly Detection in Retail Stores for Automatic Correction using Mobile Robots
Oct 21, 2023
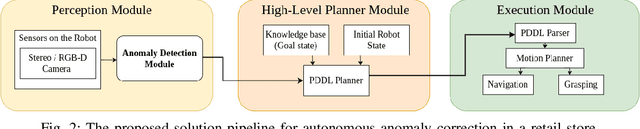

Tracking of inventory and rearrangement of misplaced items are some of the most labor-intensive tasks in a retail environment. While there have been attempts at using vision-based techniques for these tasks, they mostly use planogram compliance for detection of any anomalies, a technique that has been found lacking in robustness and scalability. Moreover, existing systems rely on human intervention to perform corrective actions after detection. In this paper, we present Co-AD, a Concept-based Anomaly Detection approach using a Vision Transformer (ViT) that is able to flag misplaced objects without using a prior knowledge base such as a planogram. It uses an auto-encoder architecture followed by outlier detection in the latent space. Co-AD has a peak success rate of 89.90% on anomaly detection image sets of retail objects drawn from the RP2K dataset, compared to 80.81% on the best-performing baseline of a standard ViT auto-encoder. To demonstrate its utility, we describe a robotic mobile manipulation pipeline to autonomously correct the anomalies flagged by Co-AD. This work is ultimately aimed towards developing autonomous mobile robot solutions that reduce the need for human intervention in retail store management.
Auto-TransRL: Autonomous Composition of Vision Pipelines for Robotic Perception
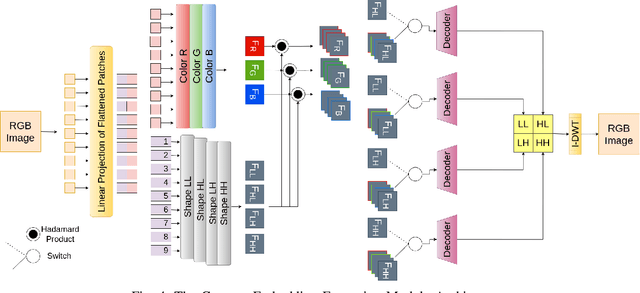
Sep 07, 2022
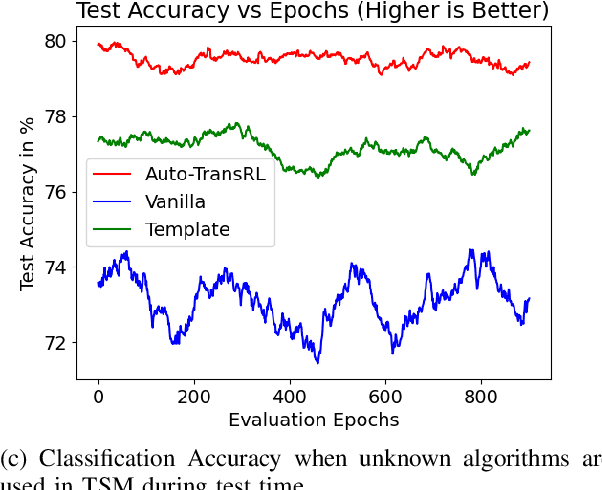
Creating a vision pipeline for different datasets to solve a computer vision task is a complex and time consuming process. Currently, these pipelines are developed with the help of domain experts. Moreover, there is no systematic structure to construct a vision pipeline apart from relying on experience, trial and error or using template-based approaches. As the search space for choosing suitable algorithms for achieving a particular vision task is large, human exploration for finding a good solution requires time and effort. To address the following issues, we propose a dynamic and data-driven way to identify an appropriate set of algorithms that would be fit for building the vision pipeline in order to achieve the goal task. We introduce a Transformer Architecture complemented with Deep Reinforcement Learning to recommend algorithms that can be incorporated at different stages of the vision workflow. This system is both robust and adaptive to dynamic changes in the environment. Experimental results further show that our method also generalizes well to recommend algorithms that have not been used while training and hence alleviates the need of retraining the system on a new set of algorithms introduced during test time.
Challenges in Applying Robotics to Retail Store Management
Aug 18, 2022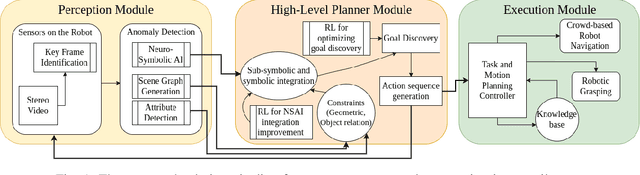
An autonomous retail store management system entails inventory tracking, store monitoring, and anomaly correction. Recent attempts at autonomous retail store management have faced challenges primarily in perception for anomaly detection, as well as new challenges arising in mobile manipulation for executing anomaly correction. Advances in each of these areas along with system integration are necessary for a scalable solution in this domain.