 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIZOR: Viewpoint-Invariant Zero-Shot Scene Graph Generation for 3D Scene Reasoning
Jan 31, 2026Scene understanding and reasoning has been a fundamental problem in 3D computer vision, requiring models to identify objects, their properties, and spatial or comparative relationships among the objects. Existing approaches enable this by creating scene graphs using multiple inputs such as 2D images, depth maps, object labels, and annotated relationships from specific reference view. However, these methods often struggle with generalization and produce inaccurate spatial relationships like "left/right", which become inconsistent across different viewpoints. To address these limitations, we propose Viewpoint-Invariant Zero-shot scene graph generation for 3D scene Reasoning (VIZOR). VIZOR is a training-free, end-to-end framework that constructs dense, viewpoint-invariant 3D scene graphs directly from raw 3D scenes. The generated scene graph is unambiguous, as spatial relationships are defined relative to each object's front-facing direction, making them consistent regardless of the reference view. Furthermore, it infers open-vocabulary relationships that describe spatial and proximity relationships among scene objects without requiring annotated training data. We conduct extensive quantitative and qualitative evaluations to assess the effectiveness of VIZOR in scene graph generation and downstream tasks, such as query-based object grounding. VIZOR outperforms state-of-the-art methods, showing clear improvements in scene graph generation and achieving 22% and 4.81% gains in zero-shot grounding accuracy on the Replica and Nr3D datasets, respectively.
Towards a Training Free Approach for 3D Scene Editing
Dec 17, 2024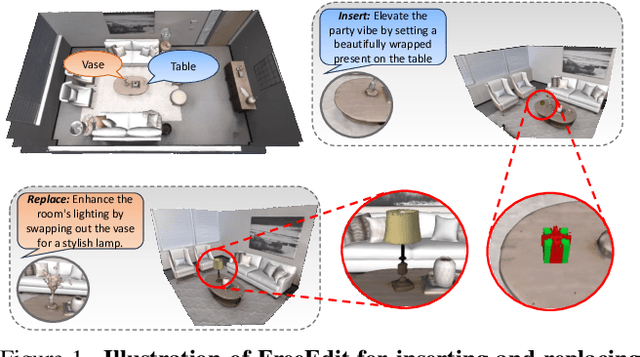

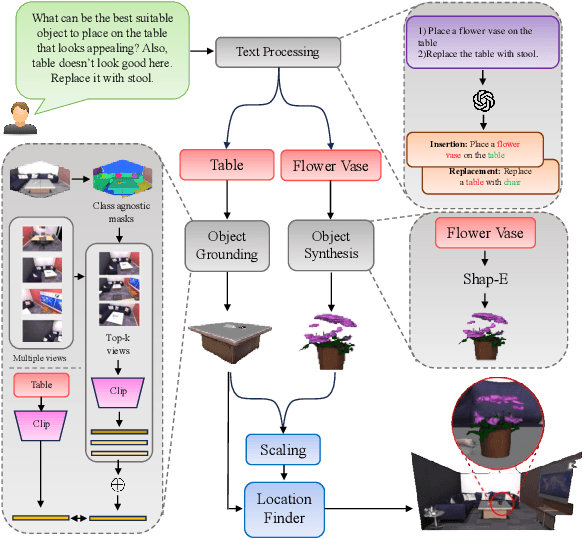
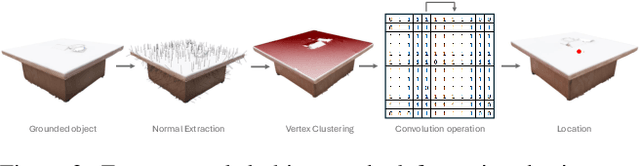
Text driven diffusion models have shown remarkable capabilities in editing images. However, when editing 3D scenes, existing works mostly rely on training a NeRF for 3D editing. Recent NeRF editing methods leverages edit operations by deploying 2D diffusion models and project these edits into 3D space. They require strong positional priors alongside text prompt to identify the edit location. These methods are operational on small 3D scenes and are more generalized to particular scene. They require training for each specific edit and cannot be exploited in real-time edits. To address these limitations, we propose a novel method, FreeEdit, to make edits in training free manner using mesh representations as a substitute for NeRF. Training-free methods are now a possibility because of the advances in foundation model's space. We leverage these models to bring a training-free alternative and introduce solutions for insertion, replacement and deletion. We consider insertion, replacement and deletion as basic blocks for performing intricate edits with certain combinations of these operations. Given a text prompt and a 3D scene, our model is capable of identifying what object should be inserted/replaced or deleted and location where edit should be performed. We also introduce a novel algorithm as part of FreeEdit to find the optimal location on grounding object for placement. We evaluate our model by comparing it with baseline models on a wide range of scenes using quantitative and qualitative metrics and showcase the merits of our method with respect to others.