 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosed-Form Node Classification with Exact Graph Unlearning
May 25, 2026Graph neural networks for node classification are typically trained by gradient descent over hundreds or thousands of epochs. Recent work has shown that, when properly tuned, classic GCN/SAGE/GAT architectures can match graph transformers on many node-classification benchmarks. We ask a complementary question: how much of this performance can be recovered by deterministic closed-form solvers, and what guarantees does this enable? We introduce a routed closed-form framework selected by adjusted homophily. For assortative graphs, we use SGC-style propagation followed by Ridge regression; for heterophilous graphs, we introduce LCF-Net, a layer-wise closed-form graph feature-refinement network whose per-layer Ridge solves are capped by a Gaussian kernel-Ridge head. Across 14 benchmarks, including ogbn-arxiv and ogbn-proteins, our closed-form predictors match or beat the best vanilla 2-layer GCN/SAGE/GAT on 9 of 9 measured datasets, tie tuned deep recipes within one standard deviation on 9 of 12 small benchmarks, and exceed the OGB-leaderboard plain GCN on both large graphs. The remaining heterophilous gap closely tracks the gain from vanilla 2-layer to deep SAGE, suggesting that the residual difference is primarily architectural. Because our predictors are explicit solutions of deterministic linear systems, modified graph inputs can be re-solved to obtain retrain-equivalent parameters. We formalize exact graph-object unlearning for label, feature, edge, node, and subgraph modifications, prove K-hop locality for Ridge components, and verify exactness across 109 configurations. On ogbn-arxiv, localized updates give $21$--$45\times$ speedups over full re-solving and roughly $10^{6}\times$ speedups over gradient retraining. Structural-inversion experiments further quantify the privacy floor of exact retraining and the additional leakage of approximate graph-unlearning methods.
PatchPoison: Poisoning Multi-View Datasets to Degrade 3D Reconstruction
Apr 14, 20263D Gaussian Splatting (3DGS) has recently enabled highly photorealistic 3D reconstruction from casually captured multi-view images. However, this accessibility raises a privacy concern: publicly available images or videos can be exploited to reconstruct detailed 3D models of scenes or objects without the owner's consent. We present PatchPoison, a lightweight dataset-poisoning method that prevents unauthorized 3D reconstruction. Unlike global perturbations, PatchPoison injects a small high-frequency adversarial patch, a structured checkerboard, into the periphery of each image in a multi-view dataset. The patch is designed to corrupt the feature-matching stage of Structure-from-Motion (SfM) pipelines such as COLMAP by introducing spurious correspondences that systematically misalign estimated camera poses. Consequently, downstream 3DGS optimization diverges from the correct scene geometry. On the NeRF-Synthetic benchmark, inserting a 12 X 12 pixel patch increases reconstruction error by 6.8x in LPIPS, while the poisoned images remain unobtrusive to human viewers. PatchPoison requires no pipeline modifications, offering a practical, "drop-in" preprocessing step for content creators to protect their multi-view data.
VIZOR: Viewpoint-Invariant Zero-Shot Scene Graph Generation for 3D Scene Reasoning
Jan 31, 2026Scene understanding and reasoning has been a fundamental problem in 3D computer vision, requiring models to identify objects, their properties, and spatial or comparative relationships among the objects. Existing approaches enable this by creating scene graphs using multiple inputs such as 2D images, depth maps, object labels, and annotated relationships from specific reference view. However, these methods often struggle with generalization and produce inaccurate spatial relationships like "left/right", which become inconsistent across different viewpoints. To address these limitations, we propose Viewpoint-Invariant Zero-shot scene graph generation for 3D scene Reasoning (VIZOR). VIZOR is a training-free, end-to-end framework that constructs dense, viewpoint-invariant 3D scene graphs directly from raw 3D scenes. The generated scene graph is unambiguous, as spatial relationships are defined relative to each object's front-facing direction, making them consistent regardless of the reference view. Furthermore, it infers open-vocabulary relationships that describe spatial and proximity relationships among scene objects without requiring annotated training data. We conduct extensive quantitative and qualitative evaluations to assess the effectiveness of VIZOR in scene graph generation and downstream tasks, such as query-based object grounding. VIZOR outperforms state-of-the-art methods, showing clear improvements in scene graph generation and achieving 22% and 4.81% gains in zero-shot grounding accuracy on the Replica and Nr3D datasets, respectively.
InteracTalker: Prompt-Based Human-Object Interaction with Co-Speech Gesture Generation
Dec 14, 2025


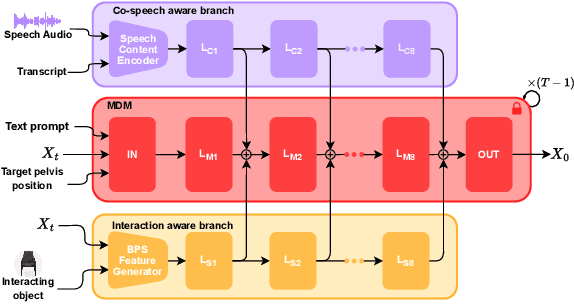
Generating realistic human motions that naturally respond to both spoken language and physical objects is crucial for interactive digital experiences. Current methods, however, address speech-driven gestures or object interactions independently, limiting real-world applicability due to a lack of integrated, comprehensive datasets. To overcome this, we introduce InteracTalker, a novel framework that seamlessly integrates prompt-based object-aware interactions with co-speech gesture generation. We achieve this by employing a multi-stage training process to learn a unified motion, speech, and prompt embedding space. To support this, we curate a rich human-object interaction dataset, formed by augmenting an existing text-to-motion dataset with detailed object interaction annotations. Our framework utilizes a Generalized Motion Adaptation Module that enables independent training, adapting to the corresponding motion condition, which is then dynamically combined during inference. To address the imbalance between heterogeneous conditioning signals, we propose an adaptive fusion strategy, which dynamically reweights the conditioning signals during diffusion sampling. InteracTalker successfully unifies these previously separate tasks, outperforming prior methods in both co-speech gesture generation and object-interaction synthesis, outperforming gesture-focused diffusion methods, yielding highly realistic, object-aware full-body motions with enhanced realism, flexibility, and control.
SymGS : Leveraging Local Symmetries for 3D Gaussian Splatting Compression
Nov 19, 2025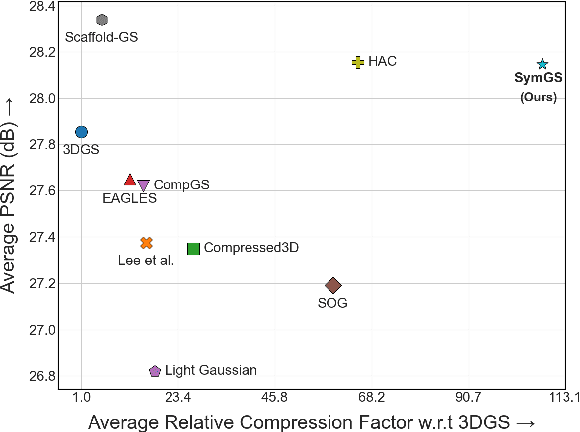



3D Gaussian Splatting has emerged as a transformative technique in novel view synthesis, primarily due to its high rendering speed and photorealistic fidelity. However, its memory footprint scales rapidly with scene complexity, often reaching several gigabytes. Existing methods address this issue by introducing compression strategies that exploit primitive-level redundancy through similarity detection and quantization. We aim to surpass the compression limits of such methods by incorporating symmetry-aware techniques, specifically targeting mirror symmetries to eliminate redundant primitives. We propose a novel compression framework, SymGS, introducing learnable mirrors into the scene, thereby eliminating local and global reflective redundancies for compression. Our framework functions as a plug-and-play enhancement to state-of-the-art compression methods, (e.g. HAC) to achieve further compression. Compared to HAC, we achieve $1.66 \times$ compression across benchmark datasets (upto $3\times$ on large-scale scenes). On an average, SymGS enables $\bf{108\times}$ compression of a 3DGS scene, while preserving rendering quality. The project page and supplementary can be found at symgs.github.io
Large Language Models and 3D Vision for Intelligent Robotic Perception and Autonomy
Nov 18, 2025With the rapid advancement of artificial intelligence and robotics, the integration of Large Language Models (LLMs) with 3D vision is emerging as a transformative approach to enhancing robotic sensing technologies. This convergence enables machines to perceive, reason and interact with complex environments through natural language and spatial understanding, bridging the gap between linguistic intelligence and spatial perception. This review provides a comprehensive analysis of state-of-the-art methodologies, applications and challenges at the intersection of LLMs and 3D vision, with a focus on next-generation robotic sensing technologies. We first introduce the foundational principles of LLMs and 3D data representations, followed by an in-depth examination of 3D sensing technologies critical for robotics. The review then explores key advancements in scene understanding, text-to-3D generation, object grounding and embodied agents, highlighting cutting-edge techniques such as zero-shot 3D segmentation, dynamic scene synthesis and language-guided manipulation. Furthermore, we discuss multimodal LLMs that integrate 3D data with touch, auditory and thermal inputs, enhancing environmental comprehension and robotic decision-making. To support future research, we catalog benchmark datasets and evaluation metrics tailored for 3D-language and vision tasks. Finally, we identify key challenges and future research directions, including adaptive model architectures, enhanced cross-modal alignment and real-time processing capabilities, which pave the way for more intelligent, context-aware and autonomous robotic sensing systems.
* 45 pages, 15 figures, MDPI Sensors Journal
LoReTTA: A Low Resource Framework To Poison Continuous Time Dynamic Graphs
Nov 10, 2025Temporal Graph Neural Networks (TGNNs) are increasingly used in high-stakes domains, such as financial forecasting, recommendation systems, and fraud detection. However, their susceptibility to poisoning attacks poses a critical security risk. We introduce LoReTTA (Low Resource Two-phase Temporal Attack), a novel adversarial framework on Continuous-Time Dynamic Graphs, which degrades TGNN performance by an average of 29.47% across 4 widely benchmark datasets and 4 State-of-the-Art (SotA) models. LoReTTA operates through a two-stage approach: (1) sparsify the graph by removing high-impact edges using any of the 16 tested temporal importance metrics, (2) strategically replace removed edges with adversarial negatives via LoReTTA's novel degree-preserving negative sampling algorithm. Our plug-and-play design eliminates the need for expensive surrogate models while adhering to realistic unnoticeability constraints. LoReTTA degrades performance by upto 42.0% on MOOC, 31.5% on Wikipedia, 28.8% on UCI, and 15.6% on Enron. LoReTTA outperforms 11 attack baselines, remains undetectable to 4 leading anomaly detection systems, and is robust to 4 SotA adversarial defense training methods, establishing its effectiveness, unnoticeability, and robustness.
Federated Spectral Graph Transformers Meet Neural Ordinary Differential Equations for Non-IID Graphs
Apr 16, 2025Graph Neural Network (GNN) research is rapidly advancing due to GNNs' capacity to learn distributed representations from graph-structured data. However, centralizing large volumes of real-world graph data for GNN training is often impractical due to privacy concerns, regulatory restrictions, and commercial competition. Federated learning (FL), a distributed learning paradigm, offers a solution by preserving data privacy with collaborative model training. Despite progress in training huge vision and language models, federated learning for GNNs remains underexplored. To address this challenge, we present a novel method for federated learning on GNNs based on spectral GNNs equipped with neural ordinary differential equations (ODE) for better information capture, showing promising results across both homophilic and heterophilic graphs. Our approach effectively handles non-Independent and Identically Distributed (non-IID) data, while also achieving performance comparable to existing methods that only operate on IID data. It is designed to be privacy-preserving and bandwidth-optimized, making it suitable for real-world applications such as social network analysis, recommendation systems, and fraud detection, which often involve complex, non-IID, and heterophilic graph structures. Our results in the area of federated learning on non-IID heterophilic graphs demonstrate significant improvements, while also achieving better performance on homophilic graphs. This work highlights the potential of federated learning in diverse and challenging graph settings. Open-source code available on GitHub (https://github.com/SpringWiz11/Fed-GNODEFormer).
Predict Confidently, Predict Right: Abstention in Dynamic Graph Learning
Jan 14, 2025Many real-world systems can be modeled as dynamic graphs, where nodes and edges evolve over time, requiring specialized models to capture their evolving dynamics in risk-sensitive applications effectively. Temporal graph neural networks (GNNs) are one such category of specialized models. For the first time, our approach integrates a reject option strategy within the framework of GNNs for continuous-time dynamic graphs. This allows the model to strategically abstain from making predictions when the uncertainty is high and confidence is low, thus minimizing the risk of critical misclassification and enhancing the results and reliability. We propose a coverage-based abstention prediction model to implement the reject option that maximizes prediction within a specified coverage. It improves the prediction score for link prediction and node classification tasks. Temporal GNNs deal with extremely skewed datasets for the next state prediction or node classification task. In the case of class imbalance, our method can be further tuned to provide a higher weightage to the minority class. Exhaustive experiments are presented on four datasets for dynamic link prediction and two datasets for dynamic node classification tasks. This demonstrates the effectiveness of our approach in improving the reliability and area under the curve (AUC)/ average precision (AP) scores for predictions in dynamic graph scenarios. The results highlight our model's ability to efficiently handle the trade-offs between prediction confidence and coverage, making it a dependable solution for applications requiring high precision in dynamic and uncertain environments.
Towards a Training Free Approach for 3D Scene Editing
Dec 17, 2024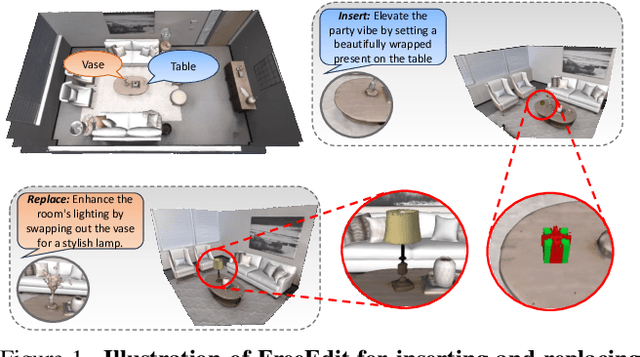

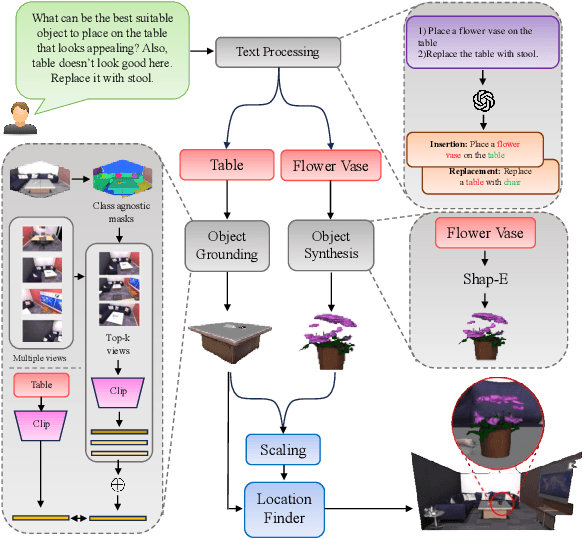
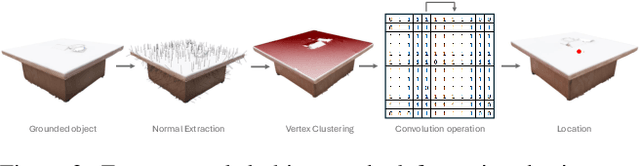
Text driven diffusion models have shown remarkable capabilities in editing images. However, when editing 3D scenes, existing works mostly rely on training a NeRF for 3D editing. Recent NeRF editing methods leverages edit operations by deploying 2D diffusion models and project these edits into 3D space. They require strong positional priors alongside text prompt to identify the edit location. These methods are operational on small 3D scenes and are more generalized to particular scene. They require training for each specific edit and cannot be exploited in real-time edits. To address these limitations, we propose a novel method, FreeEdit, to make edits in training free manner using mesh representations as a substitute for NeRF. Training-free methods are now a possibility because of the advances in foundation model's space. We leverage these models to bring a training-free alternative and introduce solutions for insertion, replacement and deletion. We consider insertion, replacement and deletion as basic blocks for performing intricate edits with certain combinations of these operations. Given a text prompt and a 3D scene, our model is capable of identifying what object should be inserted/replaced or deleted and location where edit should be performed. We also introduce a novel algorithm as part of FreeEdit to find the optimal location on grounding object for placement. We evaluate our model by comparing it with baseline models on a wide range of scenes using quantitative and qualitative metrics and showcase the merits of our method with respect to others.