 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIZOR: Viewpoint-Invariant Zero-Shot Scene Graph Generation for 3D Scene Reasoning
Jan 31, 2026Scene understanding and reasoning has been a fundamental problem in 3D computer vision, requiring models to identify objects, their properties, and spatial or comparative relationships among the objects. Existing approaches enable this by creating scene graphs using multiple inputs such as 2D images, depth maps, object labels, and annotated relationships from specific reference view. However, these methods often struggle with generalization and produce inaccurate spatial relationships like "left/right", which become inconsistent across different viewpoints. To address these limitations, we propose Viewpoint-Invariant Zero-shot scene graph generation for 3D scene Reasoning (VIZOR). VIZOR is a training-free, end-to-end framework that constructs dense, viewpoint-invariant 3D scene graphs directly from raw 3D scenes. The generated scene graph is unambiguous, as spatial relationships are defined relative to each object's front-facing direction, making them consistent regardless of the reference view. Furthermore, it infers open-vocabulary relationships that describe spatial and proximity relationships among scene objects without requiring annotated training data. We conduct extensive quantitative and qualitative evaluations to assess the effectiveness of VIZOR in scene graph generation and downstream tasks, such as query-based object grounding. VIZOR outperforms state-of-the-art methods, showing clear improvements in scene graph generation and achieving 22% and 4.81% gains in zero-shot grounding accuracy on the Replica and Nr3D datasets, respectively.
Synergizing Contrastive Learning and Optimal Transport for 3D Point Cloud Domain Adaptation
Aug 27, 2023



Recently, the fundamental problem of unsupervised domain adaptation (UDA) on 3D point clouds has been motivated by a wide variety of applications in robotics, virtual reality, and scene understanding, to name a few. The point cloud data acquisition procedures manifest themselves as significant domain discrepancies and geometric variations among both similar and dissimilar classes. The standard domain adaptation methods developed for images do not directly translate to point cloud data because of their complex geometric nature. To address this challenge, we leverage the idea of multimodality and alignment between distributions. We propose a new UDA architecture for point cloud classification that benefits from multimodal contrastive learning to get better class separation in both domains individually. Further, the use of optimal transport (OT) aims at learning source and target data distributions jointly to reduce the cross-domain shift and provide a better alignment. We conduct a comprehensive empirical study on PointDA-10 and GraspNetPC-10 and show that our method achieves state-of-the-art performance on GraspNetPC-10 (with approx 4-12% margin) and best average performance on PointDA-10. Our ablation studies and decision boundary analysis also validate the significance of our contrastive learning module and OT alignment.
ComplAI: Theory of A Unified Framework for Multi-factor Assessment of Black-Box Supervised Machine Learning Models
Dec 30, 2022



The advances in Artificial Intelligence are creating new opportunities to improve lives of people around the world, from business to healthcare, from lifestyle to education. For example, some systems profile the users using their demographic and behavioral characteristics to make certain domain-specific predictions. Often, such predictions impact the life of the user directly or indirectly (e.g., loan disbursement, determining insurance coverage, shortlisting applications, etc.). As a result, the concerns over such AI-enabled systems are also increasing. To address these concerns, such systems are mandated to be responsible i.e., transparent, fair, and explainable to developers and end-users. In this paper, we present ComplAI, a unique framework to enable, observe, analyze and quantify explainability, robustness, performance, fairness, and model behavior in drift scenarios, and to provide a single Trust Factor that evaluates different supervised Machine Learning models not just from their ability to make correct predictions but from overall responsibility perspective. The framework helps users to (a) connect their models and enable explanations, (b) assess and visualize different aspects of the model, such as robustness, drift susceptibility, and fairness, and (c) compare different models (from different model families or obtained through different hyperparameter settings) from an overall perspective thereby facilitating actionable recourse for improvement of the models. It is model agnostic and works with different supervised machine learning scenarios (i.e., Binary Classification, Multi-class Classification, and Regression) and frameworks. It can be seamlessly integrated with any ML life-cycle framework. Thus, this already deployed framework aims to unify critical aspects of Responsible AI systems for regulating the development process of such real systems.
IITP at AILA 2019: System Report for Artificial Intelligence for Legal Assistance Shared Task
May 24, 2021
In this article, we present a description of our systems as a part of our participation in the shared task namely Artificial Intelligence for Legal Assistance (AILA 2019). This is an integral event of Forum for Information Retrieval Evaluation-2019. The outcomes of this track would be helpful for the automation of the working process of the Indian Judiciary System. The manual working procedures and documentation at any level (from lower to higher court) of the judiciary system are very complex in nature. The systems produced as a part of this track would assist the law practitioners. It would be helpful for common men too. This kind of track also opens the path of research of Natural Language Processing (NLP) in the judicial domain. This track defined two problems such as Task 1: Identifying relevant prior cases for a given situation and Task 2: Identifying the most relevant statutes for a given situation. We tackled both of them. Our proposed approaches are based on BM25 and Doc2Vec. As per the results declared by the task organizers, we are in 3rd and a modest position in Task 1 and Task 2 respectively.
Coarse and Fine-Grained Hostility Detection in Hindi Posts using Fine Tuned Multilingual Embeddings
Jan 13, 2021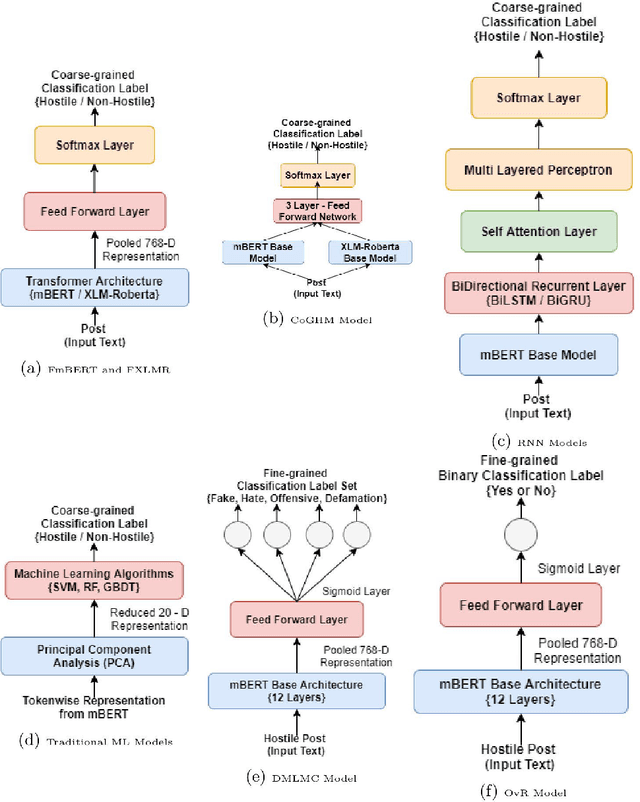



Due to the wide adoption of social media platforms like Facebook, Twitter, etc., there is an emerging need of detecting online posts that can go against the community acceptance standards. The hostility detection task has been well explored for resource-rich languages like English, but is unexplored for resource-constrained languages like Hindidue to the unavailability of large suitable data. We view this hostility detection as a multi-label multi-class classification problem. We propose an effective neural network-based technique for hostility detection in Hindi posts. We leverage pre-trained multilingual Bidirectional Encoder Representations of Transformer (mBERT) to obtain the contextual representations of Hindi posts. We have performed extensive experiments including different pre-processing techniques, pre-trained models, neural architectures, hybrid strategies, etc. Our best performing neural classifier model includes One-vs-the-Rest approach where we obtained 92.60%, 81.14%,69.59%, 75.29% and 73.01% F1 scores for hostile, fake, hate, offensive, and defamation labels respectively. The proposed model outperformed the existing baseline models and emerged as the state-of-the-art model for detecting hostility in the Hindi posts.
A Deep Learning Approach for Automatic Detection of Fake News
May 11, 2020
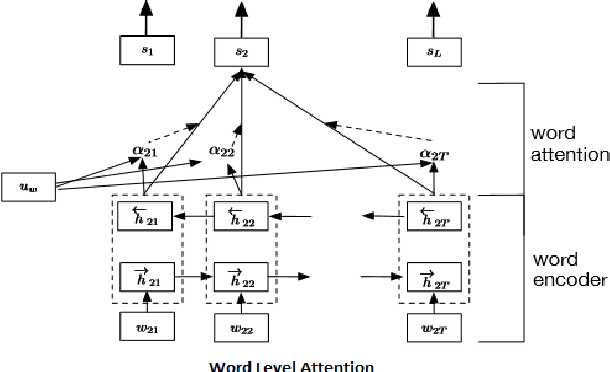
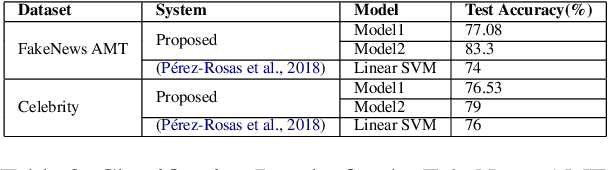
Fake news detection is a very prominent and essential task in the field of journalism. This challenging problem is seen so far in the field of politics, but it could be even more challenging when it is to be determined in the multi-domain platform. In this paper, we propose two effective models based on deep learning for solving fake news detection problem in online news contents of multiple domains. We evaluate our techniques on the two recently released datasets, namely FakeNews AMT and Celebrity for fake news detection. The proposed systems yield encouraging performance, outperforming the current handcrafted feature engineering based state-of-the-art system with a significant margin of 3.08% and 9.3% by the two models, respectively. In order to exploit the datasets, available for the related tasks, we perform cross-domain analysis (i.e. model trained on FakeNews AMT and tested on Celebrity and vice versa) to explore the applicability of our systems across the domains.