 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePedagogy-driven Evaluation of Generative AI-powered Intelligent Tutoring Systems
Oct 26, 2025The interdisciplinary research domain of Artificial Intelligence in Education (AIED) has a long history of developing Intelligent Tutoring Systems (ITSs) by integrating insights from technological advancements, educational theories, and cognitive psychology. The remarkable success of generative AI (GenAI) models has accelerated the development of large language model (LLM)-powered ITSs, which have potential to imitate human-like, pedagogically rich, and cognitively demanding tutoring. However, the progress and impact of these systems remain largely untraceable due to the absence of reliable, universally accepted, and pedagogy-driven evaluation frameworks and benchmarks. Most existing educational dialogue-based ITS evaluations rely on subjective protocols and non-standardized benchmarks, leading to inconsistencies and limited generalizability. In this work, we take a step back from mainstream ITS development and provide comprehensive state-of-the-art evaluation practices, highlighting associated challenges through real-world case studies from careful and caring AIED research. Finally, building on insights from previous interdisciplinary AIED research, we propose three practical, feasible, and theoretically grounded research directions, rooted in learning science principles and aimed at establishing fair, unified, and scalable evaluation methodologies for ITSs.
* AIED 2025 (BlueSky)
Opportunities and Challenges of LLMs in Education: An NLP Perspective
Jul 30, 2025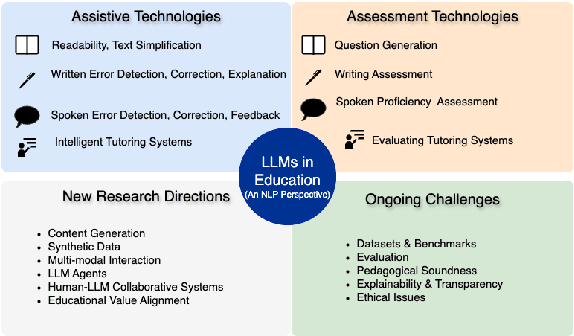


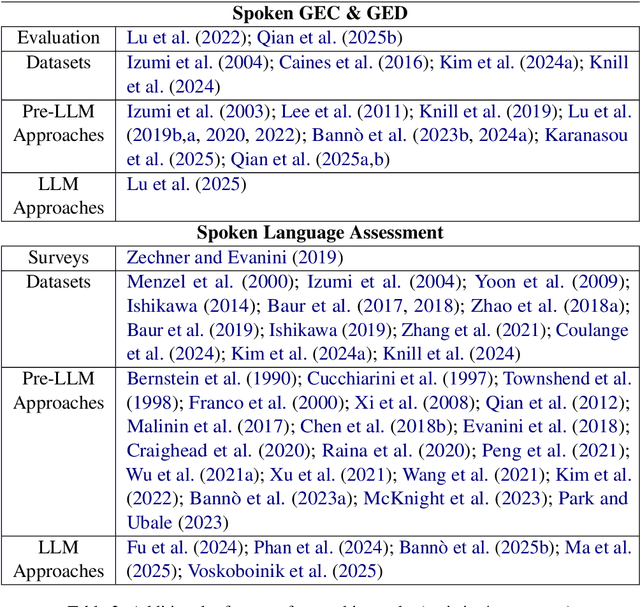
Interest in the role of large language models (LLMs) in education is increasing, considering the new opportunities they offer for teaching, learning, and assessment. In this paper, we examine the impact of LLMs on educational NLP in the context of two main application scenarios: {\em assistance} and {\em assessment}, grounding them along the four dimensions -- reading, writing, speaking, and tutoring. We then present the new directions enabled by LLMs, and the key challenges to address. We envision that this holistic overview would be useful for NLP researchers and practitioners interested in exploring the role of LLMs in developing language-focused and NLP-enabled educational applications of the future.
Simulating LLM-to-LLM Tutoring for Multilingual Math Feedback
Jun 05, 2025Large language models (LLMs) have demonstrated the ability to generate formative feedback and instructional hints in English, making them increasingly relevant for AI-assisted education. However, their ability to provide effective instructional support across different languages, especially for mathematically grounded reasoning tasks, remains largely unexamined. In this work, we present the first large-scale simulation of multilingual tutor-student interactions using LLMs. A stronger model plays the role of the tutor, generating feedback in the form of hints, while a weaker model simulates the student. We explore 352 experimental settings across 11 typologically diverse languages, four state-of-the-art LLMs, and multiple prompting strategies to assess whether language-specific feedback leads to measurable learning gains. Our study examines how student input language, teacher feedback language, model choice, and language resource level jointly influence performance. Results show that multilingual hints can significantly improve learning outcomes, particularly in low-resource languages when feedback is aligned with the student's native language. These findings offer practical insights for developing multilingual, LLM-based educational tools that are both effective and inclusive.
Unifying AI Tutor Evaluation: An Evaluation Taxonomy for Pedagogical Ability Assessment of LLM-Powered AI Tutors
Dec 12, 2024In this paper, we investigate whether current state-of-the-art large language models (LLMs) are effective as AI tutors and whether they demonstrate pedagogical abilities necessary for good AI tutoring in educational dialogues. Previous efforts towards evaluation have been limited to subjective protocols and benchmarks. To bridge this gap, we propose a unified evaluation taxonomy with eight pedagogical dimensions based on key learning sciences principles, which is designed to assess the pedagogical value of LLM-powered AI tutor responses grounded in student mistakes or confusion in the mathematical domain. We release MRBench -- a new evaluation benchmark containing 192 conversations and 1,596 responses from seven state-of-the-art LLM-based and human tutors, providing gold annotations for eight pedagogical dimensions. We assess reliability of the popular Prometheus2 LLM as an evaluator and analyze each tutor's pedagogical abilities, highlighting which LLMs are good tutors and which ones are more suitable as question-answering systems. We believe that the presented taxonomy, benchmark, and human-annotated labels will streamline the evaluation process and help track the progress in AI tutors' development.
LLMs in Education: Novel Perspectives, Challenges, and Opportunities
Sep 18, 2024The role of large language models (LLMs) in education is an increasing area of interest today, considering the new opportunities they offer for teaching, learning, and assessment. This cutting-edge tutorial provides an overview of the educational applications of NLP and the impact that the recent advances in LLMs have had on this field. We will discuss the key challenges and opportunities presented by LLMs, grounding them in the context of four major educational applications: reading, writing, and speaking skills, and intelligent tutoring systems (ITS). This COLING 2025 tutorial is designed for researchers and practitioners interested in the educational applications of NLP and the role LLMs have to play in this area. It is the first of its kind to address this timely topic.
SelectLLM: Query-Aware Efficient Selection Algorithm for Large Language Models
Aug 16, 2024



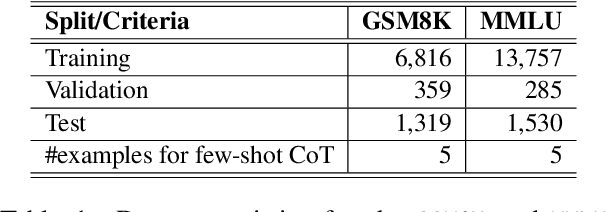
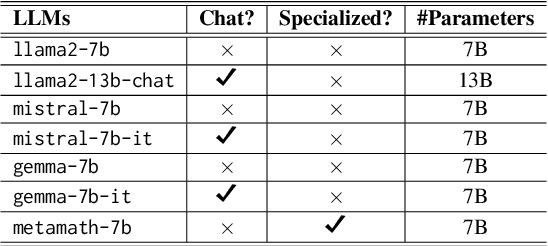
Large language models (LLMs) have gained increased popularity due to their remarkable success across various tasks, which has led to the active development of a large set of diverse LLMs. However, individual LLMs have limitations when applied to complex tasks because of such factors as training biases, model sizes, and the datasets used. A promising approach is to efficiently harness the diverse capabilities of LLMs to overcome these individual limitations. Towards this goal, we introduce a novel LLM selection algorithm called SelectLLM. This algorithm directs input queries to the most suitable subset of LLMs from a large pool, ensuring they collectively provide the correct response efficiently. SelectLLM uses a multi-label classifier, utilizing the classifier's predictions and confidence scores to design optimal policies for selecting an optimal, query-aware, and lightweight subset of LLMs. Our findings show that the proposed model outperforms individual LLMs and achieves competitive performance compared to similarly sized, computationally expensive top-performing LLM subsets. Specifically, with a similarly sized top-performing LLM subset, we achieve a significant reduction in latency on two standard reasoning benchmarks: 13% lower latency for GSM8K and 70% lower latency for MMLU. Additionally, we conduct comprehensive analyses and ablation studies, which validate the robustness of the proposed model.
Harnessing the Power of Multiple Minds: Lessons Learned from LLM Routing
May 01, 2024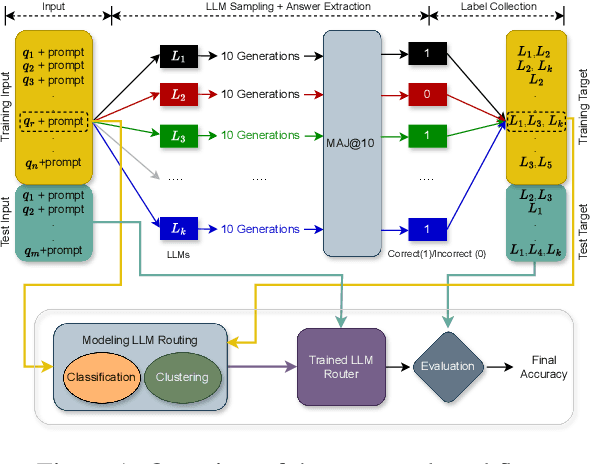
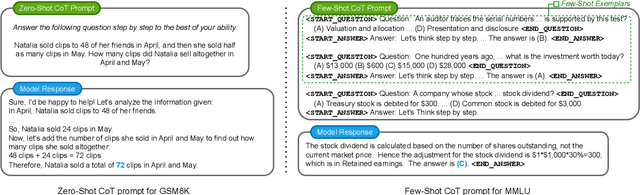
With the rapid development of LLMs, it is natural to ask how to harness their capabilities efficiently. In this paper, we explore whether it is feasible to direct each input query to a single most suitable LLM. To this end, we propose LLM routing for challenging reasoning tasks. Our extensive experiments suggest that such routing shows promise but is not feasible in all scenarios, so more robust approaches should be investigated to fill this gap.
Trie-NLG: Trie Context Augmentation to Improve Personalized Query Auto-Completion for Short and Unseen Prefixes
Jul 28, 2023Query auto-completion (QAC) aims at suggesting plausible completions for a given query prefix. Traditionally, QAC systems have leveraged tries curated from historical query logs to suggest most popular completions. In this context, there are two specific scenarios that are difficult to handle for any QAC system: short prefixes (which are inherently ambiguous) and unseen prefixes. Recently, personalized Natural Language Generation (NLG) models have been proposed to leverage previous session queries as context for addressing these two challenges. However, such NLG models suffer from two drawbacks: (1) some of the previous session queries could be noisy and irrelevant to the user intent for the current prefix, and (2) NLG models cannot directly incorporate historical query popularity. This motivates us to propose a novel NLG model for QAC, Trie-NLG, which jointly leverages popularity signals from trie and personalization signals from previous session queries. We train the Trie-NLG model by augmenting the prefix with rich context comprising of recent session queries and top trie completions. This simple modeling approach overcomes the limitations of trie-based and NLG-based approaches and leads to state-of-the-art performance. We evaluate the Trie-NLG model using two large QAC datasets. On average, our model achieves huge ~57% and ~14% boost in MRR over the popular trie-based lookup and the strong BART-based baseline methods, respectively. We make our code publicly available.
* Accepted at Journal Track of ECML-PKDD 2023
Utilizing Lexical Similarity to Enable Zero-Shot Machine Translation for Extremely Low-resource Languages
May 09, 2023



We address the task of machine translation from an extremely low-resource language (LRL) to English using cross-lingual transfer from a closely related high-resource language (HRL). For many of these languages, no parallel corpora are available, even monolingual corpora are limited and representations in pre-trained sequence-to-sequence models are absent. These factors limit the benefits of cross-lingual transfer from shared embedding spaces in multilingual models. However, many extremely LRLs have a high level of lexical similarity with related HRLs. We utilize this property by injecting character and character-span noise into the training data of the HRL prior to learning the vocabulary. This serves as a regularizer which makes the model more robust to lexical divergences between the HRL and LRL and better facilitates cross-lingual transfer. On closely related HRL and LRL pairs from multiple language families, we observe that our method significantly outperforms the baseline MT as well as approaches proposed previously to address cross-lingual transfer between closely related languages. We also show that the proposed character-span noise injection performs better than the unigram-character noise injection.
Meta-X$_{NLG}$: A Meta-Learning Approach Based on Language Clustering for Zero-Shot Cross-Lingual Transfer and Generation
Mar 19, 2022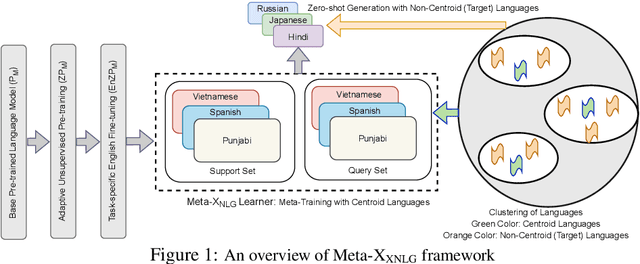
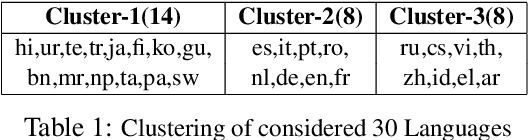


Recently, the NLP community has witnessed a rapid advancement in multilingual and cross-lingual transfer research where the supervision is transferred from high-resource languages (HRLs) to low-resource languages (LRLs). However, the cross-lingual transfer is not uniform across languages, particularly in the zero-shot setting. Towards this goal, one promising research direction is to learn shareable structures across multiple tasks with limited annotated data. The downstream multilingual applications may benefit from such a learning setup as most of the languages across the globe are low-resource and share some structures with other languages. In this paper, we propose a novel meta-learning framework (called Meta-X$_{NLG}$) to learn shareable structures from typologically diverse languages based on meta-learning and language clustering. This is a step towards uniform cross-lingual transfer for unseen languages. We first cluster the languages based on language representations and identify the centroid language of each cluster. Then, a meta-learning algorithm is trained with all centroid languages and evaluated on the other languages in the zero-shot setting. We demonstrate the effectiveness of this modeling on two NLG tasks (Abstractive Text Summarization and Question Generation), 5 popular datasets and 30 typologically diverse languages. Consistent improvements over strong baselines demonstrate the efficacy of the proposed framework. The careful design of the model makes this end-to-end NLG setup less vulnerable to the accidental translation problem, which is a prominent concern in zero-shot cross-lingual NLG tasks.