 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoCoA: Confidence- and Context-Aware Adaptive Decoding for Resolving Knowledge Conflicts in Large Language Models
Aug 25, 2025Faithful generation in large language models (LLMs) is challenged by knowledge conflicts between parametric memory and external context. Existing contrastive decoding methods tuned specifically to handle conflict often lack adaptability and can degrade performance in low conflict settings. We introduce CoCoA (Confidence- and Context-Aware Adaptive Decoding), a novel token-level algorithm for principled conflict resolution and enhanced faithfulness. CoCoA resolves conflict by utilizing confidence-aware measures (entropy gap and contextual peakedness) and the generalized divergence between the parametric and contextual distributions. Crucially, CoCoA maintains strong performance even in low conflict settings. Extensive experiments across multiple LLMs on diverse Question Answering (QA), Summarization, and Long-Form Question Answering (LFQA) benchmarks demonstrate CoCoA's state-of-the-art performance over strong baselines like AdaCAD. It yields significant gains in QA accuracy, up to 9.2 points on average compared to the strong baseline AdaCAD, and improves factuality in summarization and LFQA by up to 2.5 points on average across key benchmarks. Additionally, it demonstrates superior sensitivity to conflict variations. CoCoA enables more informed, context-aware, and ultimately more faithful token generation.
Trie-NLG: Trie Context Augmentation to Improve Personalized Query Auto-Completion for Short and Unseen Prefixes
Jul 28, 2023Query auto-completion (QAC) aims at suggesting plausible completions for a given query prefix. Traditionally, QAC systems have leveraged tries curated from historical query logs to suggest most popular completions. In this context, there are two specific scenarios that are difficult to handle for any QAC system: short prefixes (which are inherently ambiguous) and unseen prefixes. Recently, personalized Natural Language Generation (NLG) models have been proposed to leverage previous session queries as context for addressing these two challenges. However, such NLG models suffer from two drawbacks: (1) some of the previous session queries could be noisy and irrelevant to the user intent for the current prefix, and (2) NLG models cannot directly incorporate historical query popularity. This motivates us to propose a novel NLG model for QAC, Trie-NLG, which jointly leverages popularity signals from trie and personalization signals from previous session queries. We train the Trie-NLG model by augmenting the prefix with rich context comprising of recent session queries and top trie completions. This simple modeling approach overcomes the limitations of trie-based and NLG-based approaches and leads to state-of-the-art performance. We evaluate the Trie-NLG model using two large QAC datasets. On average, our model achieves huge ~57% and ~14% boost in MRR over the popular trie-based lookup and the strong BART-based baseline methods, respectively. We make our code publicly available.
* Accepted at Journal Track of ECML-PKDD 2023
Compression of Deep Learning Models for Text: A Survey
Aug 13, 2020


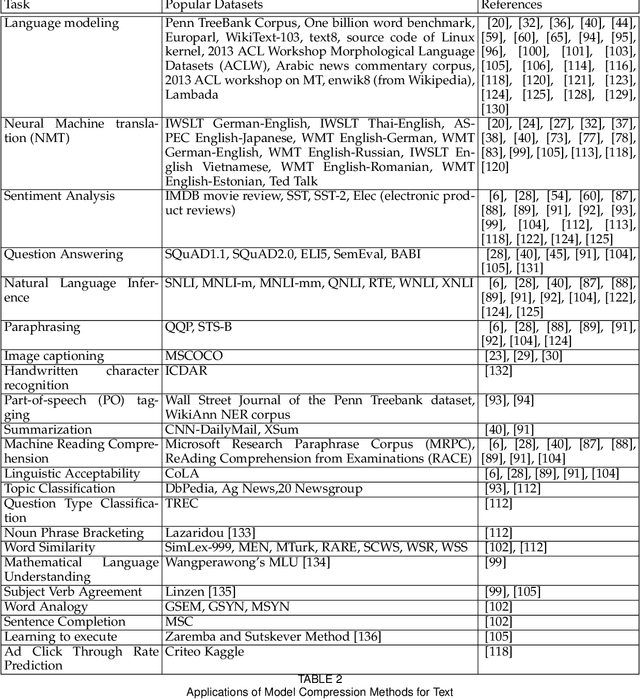
In recent years, the fields of natural language processing (NLP) and information retrieval (IR) have made tremendous progress thanks to deep learning models like Recurrent Neural Networks (RNNs), Gated Recurrent Units (GRUs) and Long Short-Term Memory (LSTMs) networks, and Transformer based models like Bidirectional Encoder Representations from Transformers (BERT). But these models are humongous in size. On the other hand, real world applications demand small model size, low response times and low computational power wattage. In this survey, we discuss six different types of methods (Pruning, Quantization, Knowledge Distillation, Parameter Sharing, Tensor Decomposition, and Linear Transformer based methods) for compression of such models to enable their deployment in real industry NLP projects. Given the critical need of building applications with efficient and small models, and the large amount of recently published work in this area, we believe that this survey organizes the plethora of work done by the 'deep learning for NLP' community in the past few years and presents it as a coherent story.
Ruuh: A Deep Learning Based Conversational Social Agent
Oct 22, 2018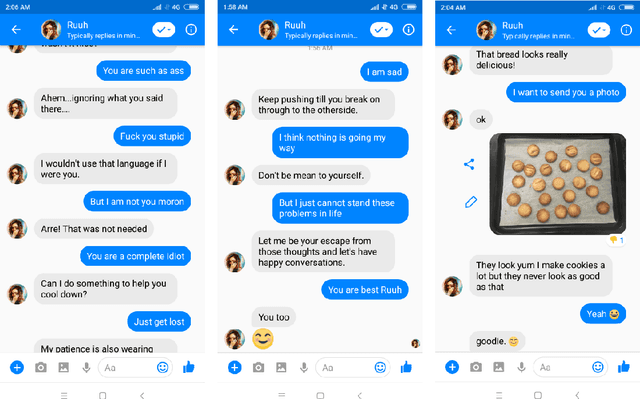
Dialogue systems and conversational agents are becoming increasingly popular in the modern society but building an agent capable of holding intelligent conversation with its users is a challenging problem for artificial intelligence. In this demo, we demonstrate a deep learning based conversational social agent called "Ruuh" (facebook.com/Ruuh) designed by a team at Microsoft India to converse on a wide range of topics. Ruuh needs to think beyond the utilitarian notion of merely generating "relevant" responses and meet a wider range of user social needs, like expressing happiness when user's favorite team wins, sharing a cute comment on showing the pictures of the user's pet and so on. The agent also needs to detect and respond to abusive language, sensitive topics and trolling behavior of the users. Many of these problems pose significant research challenges which will be demonstrated in our demo. Our agent has interacted with over 2 million real world users till date which has generated over 150 million user conversations.
A Sentiment-and-Semantics-Based Approach for Emotion Detection in Textual Conversations
Mar 30, 2018
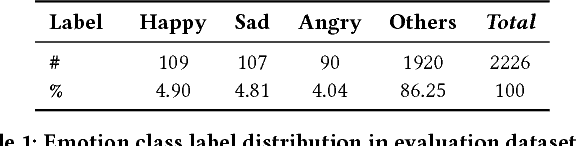
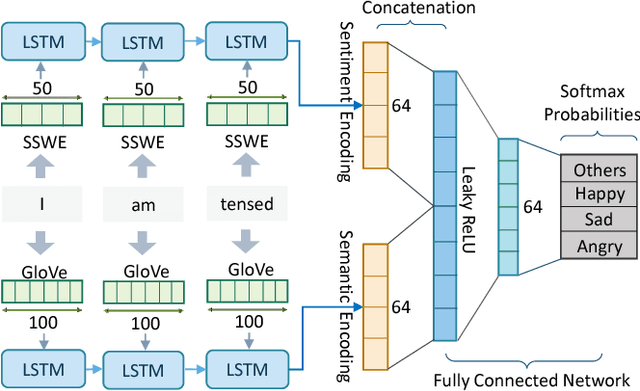
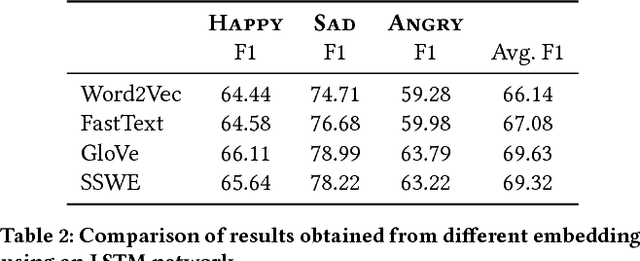
Emotions are physiological states generated in humans in reaction to internal or external events. They are complex and studied across numerous fields including computer science. As humans, on reading "Why don't you ever text me!" we can either interpret it as a sad or angry emotion and the same ambiguity exists for machines. Lack of facial expressions and voice modulations make detecting emotions from text a challenging problem. However, as humans increasingly communicate using text messaging applications, and digital agents gain popularity in our society, it is essential that these digital agents are emotion aware, and respond accordingly. In this paper, we propose a novel approach to detect emotions like happy, sad or angry in textual conversations using an LSTM based Deep Learning model. Our approach consists of semi-automated techniques to gather training data for our model. We exploit advantages of semantic and sentiment based embeddings and propose a solution combining both. Our work is evaluated on real-world conversations and significantly outperforms traditional Machine Learning baselines as well as other off-the-shelf Deep Learning models.
Emulating Human Conversations using Convolutional Neural Network-based IR
Jun 22, 2016
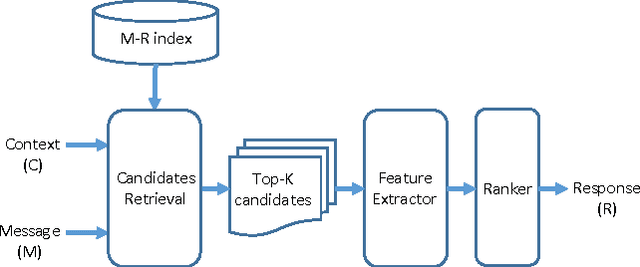

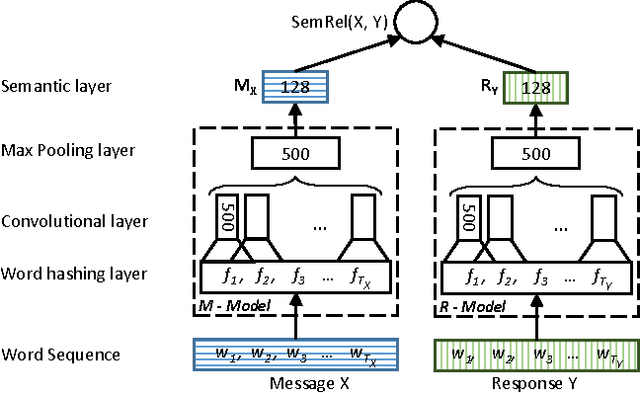
Conversational agents ("bots") are beginning to be widely used in conversational interfaces. To design a system that is capable of emulating human-like interactions, a conversational layer that can serve as a fabric for chat-like interaction with the agent is needed. In this paper, we introduce a model that employs Information Retrieval by utilizing convolutional deep structured semantic neural network-based features in the ranker to present human-like responses in ongoing conversation with a user. In conversations, accounting for context is critical to the retrieval model; we show that our context-sensitive approach using a Convolutional Deep Structured Semantic Model (cDSSM) with character trigrams significantly outperforms several conventional baselines in terms of the relevance of responses retrieved.