 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompression of Deep Learning Models for Text: A Survey
Paper and Code
Aug 13, 2020


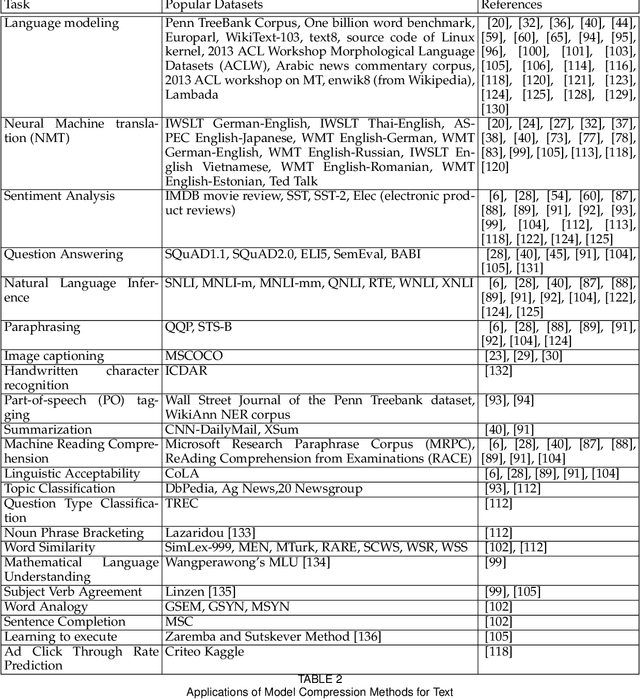
In recent years, the fields of natural language processing (NLP) and information retrieval (IR) have made tremendous progress thanks to deep learning models like Recurrent Neural Networks (RNNs), Gated Recurrent Units (GRUs) and Long Short-Term Memory (LSTMs) networks, and Transformer based models like Bidirectional Encoder Representations from Transformers (BERT). But these models are humongous in size. On the other hand, real world applications demand small model size, low response times and low computational power wattage. In this survey, we discuss six different types of methods (Pruning, Quantization, Knowledge Distillation, Parameter Sharing, Tensor Decomposition, and Linear Transformer based methods) for compression of such models to enable their deployment in real industry NLP projects. Given the critical need of building applications with efficient and small models, and the large amount of recently published work in this area, we believe that this survey organizes the plethora of work done by the 'deep learning for NLP' community in the past few years and presents it as a coherent story.