 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reward Modeling for AI Tutors in Math Mistake Remediation
Mar 25, 2026Evaluating the pedagogical quality of AI tutors remains challenging: standard NLG metrics do not determine whether responses identify mistakes, scaffold reasoning, or avoid revealing the answers. For the task of mistake remediation, we derive a hierarchy of pedagogical aspects from human pairwise preferences on MRBench, and synthesize minimally contrastive response pairs that differ along key aspects (e.g., mistake identification and location, targetedness, scaffolding, actionability, clarity, and coherence). We develop and release Bradley-Terry preference models trained on weighted-sum rankings that we automatically create from MRBench, synthetic pairs, and data combinations. Using only synthetic data, our best model reaches 0.69 pairwise accuracy on a human preference test, and combining weighted-sum data with targeted synthetic groups improves accuracy to 0.74, outperforming larger general-purpose reward models while using only a 0.5B-parameter backbone.
Intent Matters: Enhancing AI Tutoring with Fine-Grained Pedagogical Intent Annotation
Jun 09, 2025

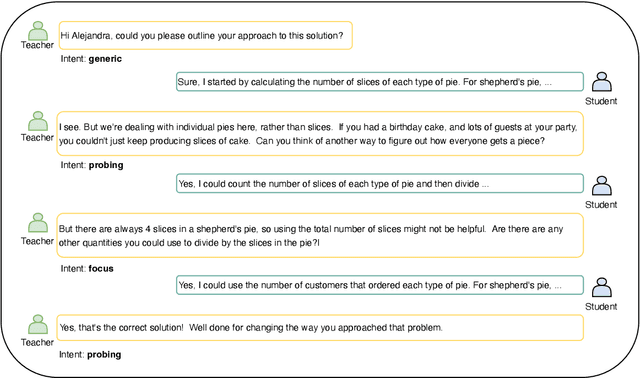

Large language models (LLMs) hold great promise for educational applications, particularly in intelligent tutoring systems. However, effective tutoring requires alignment with pedagogical strategies - something current LLMs lack without task-specific adaptation. In this work, we explore whether fine-grained annotation of teacher intents can improve the quality of LLM-generated tutoring responses. We focus on MathDial, a dialog dataset for math instruction, and apply an automated annotation framework to re-annotate a portion of the dataset using a detailed taxonomy of eleven pedagogical intents. We then fine-tune an LLM using these new annotations and compare its performance to models trained on the original four-category taxonomy. Both automatic and qualitative evaluations show that the fine-grained model produces more pedagogically aligned and effective responses. Our findings highlight the value of intent specificity for controlled text generation in educational settings, and we release our annotated data and code to facilitate further research.
A Fully Automated Pipeline for Conversational Discourse Annotation: Tree Scheme Generation and Labeling with Large Language Models
Apr 11, 2025
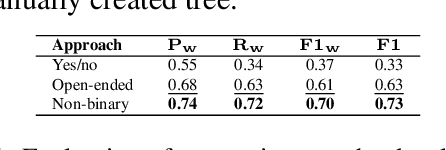
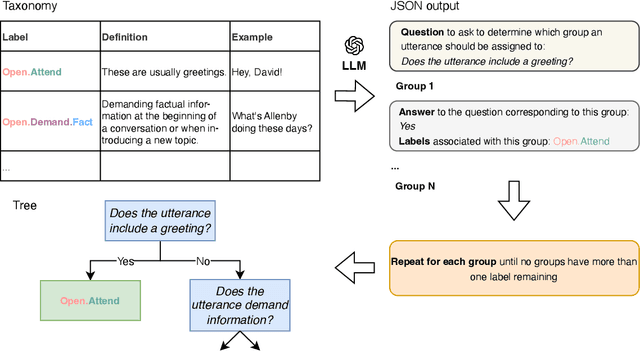
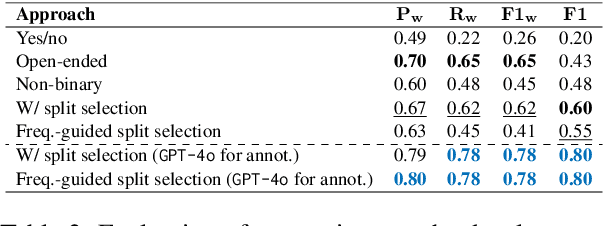
Recent advances in Large Language Models (LLMs) have shown promise in automating discourse annotation for conversations. While manually designing tree annotation schemes significantly improves annotation quality for humans and models, their creation remains time-consuming and requires expert knowledge. We propose a fully automated pipeline that uses LLMs to construct such schemes and perform annotation. We evaluate our approach on speech functions (SFs) and the Switchboard-DAMSL (SWBD-DAMSL) taxonomies. Our experiments compare various design choices, and we show that frequency-guided decision trees, paired with an advanced LLM for annotation, can outperform previously manually designed trees and even match or surpass human annotators while significantly reducing the time required for annotation. We release all code and resultant schemes and annotations to facilitate future research on discourse annotation.
Unifying AI Tutor Evaluation: An Evaluation Taxonomy for Pedagogical Ability Assessment of LLM-Powered AI Tutors
Dec 12, 2024In this paper, we investigate whether current state-of-the-art large language models (LLMs) are effective as AI tutors and whether they demonstrate pedagogical abilities necessary for good AI tutoring in educational dialogues. Previous efforts towards evaluation have been limited to subjective protocols and benchmarks. To bridge this gap, we propose a unified evaluation taxonomy with eight pedagogical dimensions based on key learning sciences principles, which is designed to assess the pedagogical value of LLM-powered AI tutor responses grounded in student mistakes or confusion in the mathematical domain. We release MRBench -- a new evaluation benchmark containing 192 conversations and 1,596 responses from seven state-of-the-art LLM-based and human tutors, providing gold annotations for eight pedagogical dimensions. We assess reliability of the popular Prometheus2 LLM as an evaluator and analyze each tutor's pedagogical abilities, highlighting which LLMs are good tutors and which ones are more suitable as question-answering systems. We believe that the presented taxonomy, benchmark, and human-annotated labels will streamline the evaluation process and help track the progress in AI tutors' development.
PetKaz at SemEval-2024 Task 8: Can Linguistics Capture the Specifics of LLM-generated Text?
Apr 08, 2024In this paper, we present our submission to the SemEval-2024 Task 8 "Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection", focusing on the detection of machine-generated texts (MGTs) in English. Specifically, our approach relies on combining embeddings from the RoBERTa-base with diversity features and uses a resampled training set. We score 12th from 124 in the ranking for Subtask A (monolingual track), and our results show that our approach is generalizable across unseen models and domains, achieving an accuracy of 0.91.
PetKaz at SemEval-2024 Task 3: Advancing Emotion Classification with an LLM for Emotion-Cause Pair Extraction in Conversations
Apr 08, 2024In this paper, we present our submission to the SemEval-2023 Task~3 "The Competition of Multimodal Emotion Cause Analysis in Conversations", focusing on extracting emotion-cause pairs from dialogs. Specifically, our approach relies on combining fine-tuned GPT-3.5 for emotion classification and a BiLSTM-based neural network to detect causes. We score 2nd in the ranking for Subtask 1, demonstrating the effectiveness of our approach through one of the highest weighted-average proportional F1 scores recorded at 0.264.