 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulating LLM-to-LLM Tutoring for Multilingual Math Feedback
Jun 05, 2025Large language models (LLMs) have demonstrated the ability to generate formative feedback and instructional hints in English, making them increasingly relevant for AI-assisted education. However, their ability to provide effective instructional support across different languages, especially for mathematically grounded reasoning tasks, remains largely unexamined. In this work, we present the first large-scale simulation of multilingual tutor-student interactions using LLMs. A stronger model plays the role of the tutor, generating feedback in the form of hints, while a weaker model simulates the student. We explore 352 experimental settings across 11 typologically diverse languages, four state-of-the-art LLMs, and multiple prompting strategies to assess whether language-specific feedback leads to measurable learning gains. Our study examines how student input language, teacher feedback language, model choice, and language resource level jointly influence performance. Results show that multilingual hints can significantly improve learning outcomes, particularly in low-resource languages when feedback is aligned with the student's native language. These findings offer practical insights for developing multilingual, LLM-based educational tools that are both effective and inclusive.
Unifying AI Tutor Evaluation: An Evaluation Taxonomy for Pedagogical Ability Assessment of LLM-Powered AI Tutors
Dec 12, 2024In this paper, we investigate whether current state-of-the-art large language models (LLMs) are effective as AI tutors and whether they demonstrate pedagogical abilities necessary for good AI tutoring in educational dialogues. Previous efforts towards evaluation have been limited to subjective protocols and benchmarks. To bridge this gap, we propose a unified evaluation taxonomy with eight pedagogical dimensions based on key learning sciences principles, which is designed to assess the pedagogical value of LLM-powered AI tutor responses grounded in student mistakes or confusion in the mathematical domain. We release MRBench -- a new evaluation benchmark containing 192 conversations and 1,596 responses from seven state-of-the-art LLM-based and human tutors, providing gold annotations for eight pedagogical dimensions. We assess reliability of the popular Prometheus2 LLM as an evaluator and analyze each tutor's pedagogical abilities, highlighting which LLMs are good tutors and which ones are more suitable as question-answering systems. We believe that the presented taxonomy, benchmark, and human-annotated labels will streamline the evaluation process and help track the progress in AI tutors' development.
SelectLLM: Query-Aware Efficient Selection Algorithm for Large Language Models
Aug 16, 2024



Large language models (LLMs) have gained increased popularity due to their remarkable success across various tasks, which has led to the active development of a large set of diverse LLMs. However, individual LLMs have limitations when applied to complex tasks because of such factors as training biases, model sizes, and the datasets used. A promising approach is to efficiently harness the diverse capabilities of LLMs to overcome these individual limitations. Towards this goal, we introduce a novel LLM selection algorithm called SelectLLM. This algorithm directs input queries to the most suitable subset of LLMs from a large pool, ensuring they collectively provide the correct response efficiently. SelectLLM uses a multi-label classifier, utilizing the classifier's predictions and confidence scores to design optimal policies for selecting an optimal, query-aware, and lightweight subset of LLMs. Our findings show that the proposed model outperforms individual LLMs and achieves competitive performance compared to similarly sized, computationally expensive top-performing LLM subsets. Specifically, with a similarly sized top-performing LLM subset, we achieve a significant reduction in latency on two standard reasoning benchmarks: 13% lower latency for GSM8K and 70% lower latency for MMLU. Additionally, we conduct comprehensive analyses and ablation studies, which validate the robustness of the proposed model.
Harnessing the Power of Multiple Minds: Lessons Learned from LLM Routing
May 01, 2024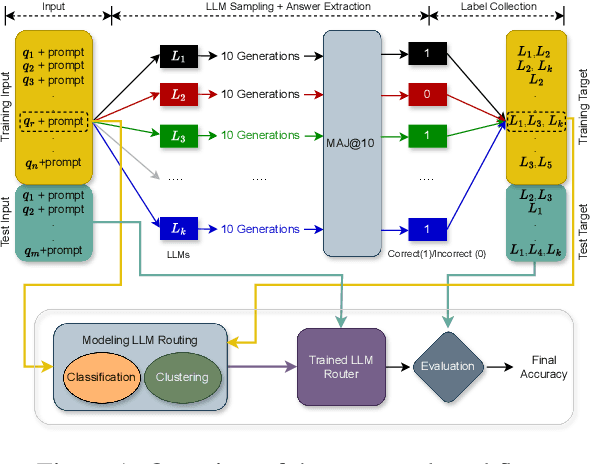
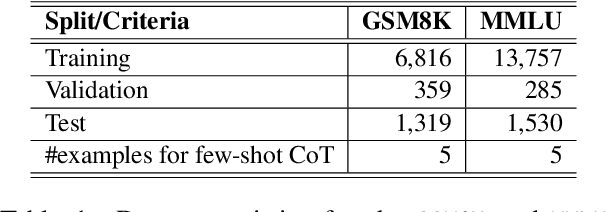
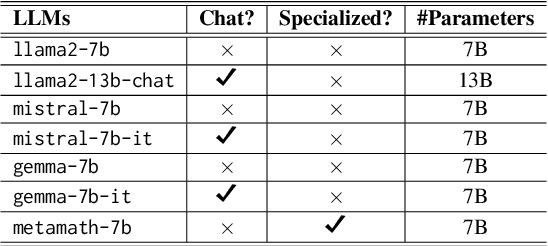
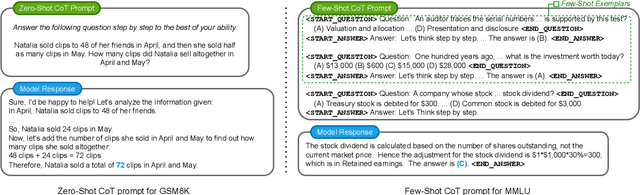
With the rapid development of LLMs, it is natural to ask how to harness their capabilities efficiently. In this paper, we explore whether it is feasible to direct each input query to a single most suitable LLM. To this end, we propose LLM routing for challenging reasoning tasks. Our extensive experiments suggest that such routing shows promise but is not feasible in all scenarios, so more robust approaches should be investigated to fill this gap.
What Makes Math Word Problems Challenging for LLMs?
Apr 01, 2024This paper investigates the question of what makes math word problems (MWPs) in English challenging for large language models (LLMs). We conduct an in-depth analysis of the key linguistic and mathematical characteristics of MWPs. In addition, we train feature-based classifiers to better understand the impact of each feature on the overall difficulty of MWPs for prominent LLMs and investigate whether this helps predict how well LLMs fare against specific categories of MWPs.
Neural models for Factual Inconsistency Classification with Explanations
Jun 15, 2023
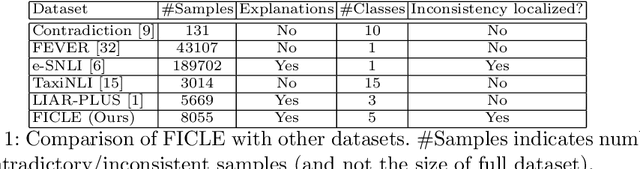

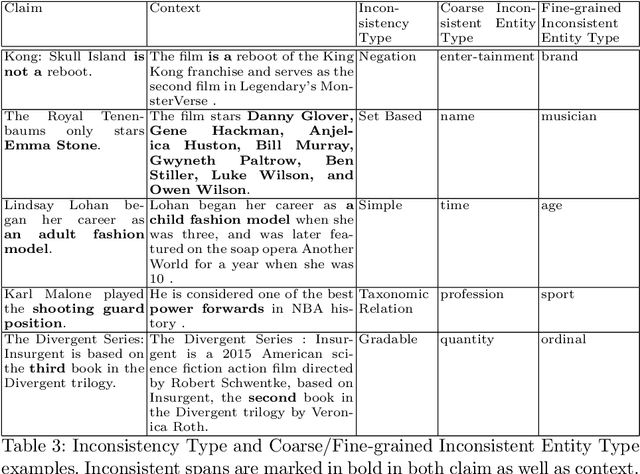
Factual consistency is one of the most important requirements when editing high quality documents. It is extremely important for automatic text generation systems like summarization, question answering, dialog modeling, and language modeling. Still, automated factual inconsistency detection is rather under-studied. Existing work has focused on (a) finding fake news keeping a knowledge base in context, or (b) detecting broad contradiction (as part of natural language inference literature). However, there has been no work on detecting and explaining types of factual inconsistencies in text, without any knowledge base in context. In this paper, we leverage existing work in linguistics to formally define five types of factual inconsistencies. Based on this categorization, we contribute a novel dataset, FICLE (Factual Inconsistency CLassification with Explanation), with ~8K samples where each sample consists of two sentences (claim and context) annotated with type and span of inconsistency. When the inconsistency relates to an entity type, it is labeled as well at two levels (coarse and fine-grained). Further, we leverage this dataset to train a pipeline of four neural models to predict inconsistency type with explanations, given a (claim, context) sentence pair. Explanations include inconsistent claim fact triple, inconsistent context span, inconsistent claim component, coarse and fine-grained inconsistent entity types. The proposed system first predicts inconsistent spans from claim and context; and then uses them to predict inconsistency types and inconsistent entity types (when inconsistency is due to entities). We experiment with multiple Transformer-based natural language classification as well as generative models, and find that DeBERTa performs the best. Our proposed methods provide a weighted F1 of ~87% for inconsistency type classification across the five classes.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).