 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing (In)Abilities of SAEs via Formal Languages
Oct 15, 2024Autoencoders have been used for finding interpretable and disentangled features underlying neural network representations in both image and text domains. While the efficacy and pitfalls of such methods are well-studied in vision, there is a lack of corresponding results, both qualitative and quantitative, for the text domain. We aim to address this gap by training sparse autoencoders (SAEs) on a synthetic testbed of formal languages. Specifically, we train SAEs on the hidden representations of models trained on formal languages (Dyck-2, Expr, and English PCFG) under a wide variety of hyperparameter settings, finding interpretable latents often emerge in the features learned by our SAEs. However, similar to vision, we find performance turns out to be highly sensitive to inductive biases of the training pipeline. Moreover, we show latents correlating to certain features of the input do not always induce a causal impact on model's computation. We thus argue that causality has to become a central target in SAE training: learning of causal features should be incentivized from the ground-up. Motivated by this, we propose and perform preliminary investigations for an approach that promotes learning of causally relevant features in our formal language setting.
Neural models for Factual Inconsistency Classification with Explanations
Jun 15, 2023
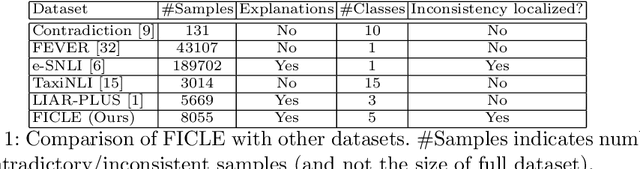

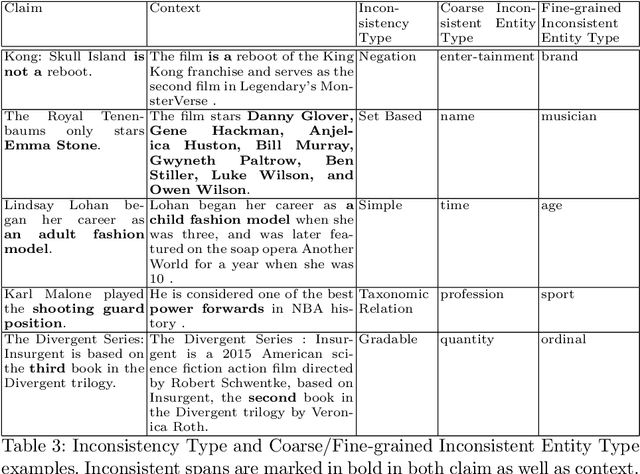
Factual consistency is one of the most important requirements when editing high quality documents. It is extremely important for automatic text generation systems like summarization, question answering, dialog modeling, and language modeling. Still, automated factual inconsistency detection is rather under-studied. Existing work has focused on (a) finding fake news keeping a knowledge base in context, or (b) detecting broad contradiction (as part of natural language inference literature). However, there has been no work on detecting and explaining types of factual inconsistencies in text, without any knowledge base in context. In this paper, we leverage existing work in linguistics to formally define five types of factual inconsistencies. Based on this categorization, we contribute a novel dataset, FICLE (Factual Inconsistency CLassification with Explanation), with ~8K samples where each sample consists of two sentences (claim and context) annotated with type and span of inconsistency. When the inconsistency relates to an entity type, it is labeled as well at two levels (coarse and fine-grained). Further, we leverage this dataset to train a pipeline of four neural models to predict inconsistency type with explanations, given a (claim, context) sentence pair. Explanations include inconsistent claim fact triple, inconsistent context span, inconsistent claim component, coarse and fine-grained inconsistent entity types. The proposed system first predicts inconsistent spans from claim and context; and then uses them to predict inconsistency types and inconsistent entity types (when inconsistency is due to entities). We experiment with multiple Transformer-based natural language classification as well as generative models, and find that DeBERTa performs the best. Our proposed methods provide a weighted F1 of ~87% for inconsistency type classification across the five classes.