 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepScholar-Bench: A Live Benchmark and Automated Evaluation for Generative Research Synthesis
Aug 27, 2025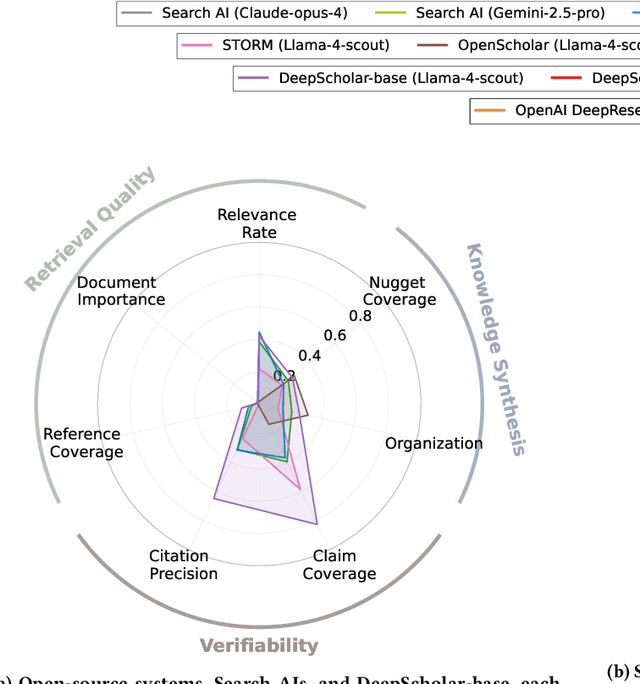
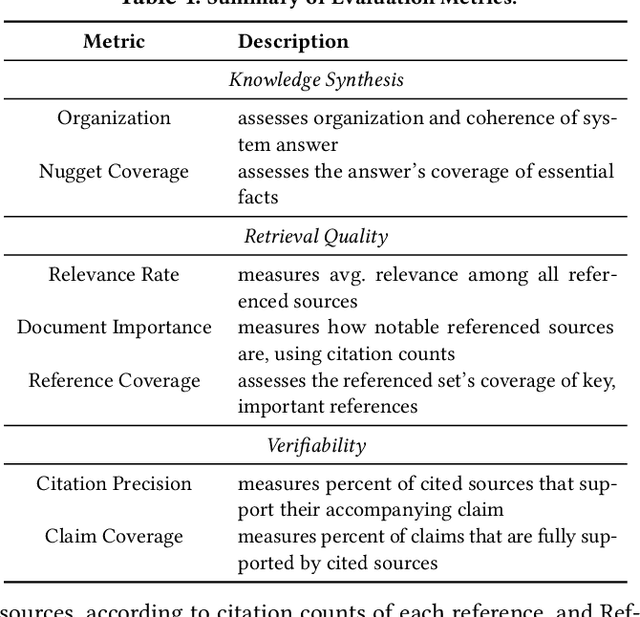
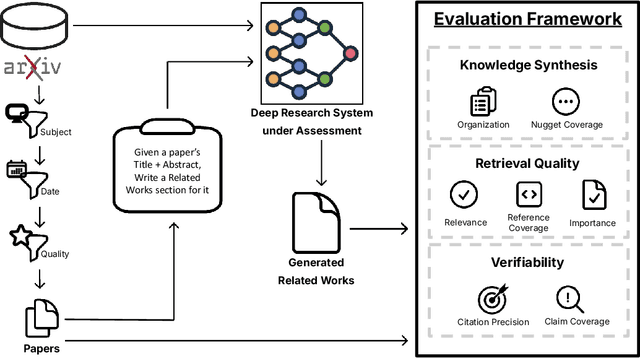
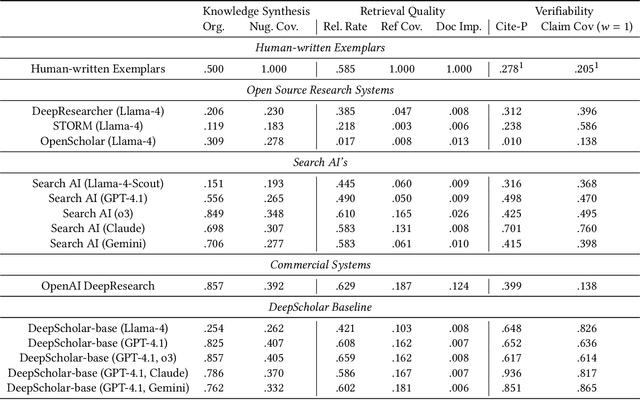
The ability to research and synthesize knowledge is central to human expertise and progress. An emerging class of systems promises these exciting capabilities through generative research synthesis, performing retrieval over the live web and synthesizing discovered sources into long-form, cited summaries. However, evaluating such systems remains an open challenge: existing question-answering benchmarks focus on short-form factual responses, while expert-curated datasets risk staleness and data contamination. Both fail to capture the complexity and evolving nature of real research synthesis tasks. In this work, we introduce DeepScholar-bench, a live benchmark and holistic, automated evaluation framework designed to evaluate generative research synthesis. DeepScholar-bench draws queries from recent, high-quality ArXiv papers and focuses on a real research synthesis task: generating the related work sections of a paper by retrieving, synthesizing, and citing prior research. Our evaluation framework holistically assesses performance across three key dimensions, knowledge synthesis, retrieval quality, and verifiability. We also develop DeepScholar-base, a reference pipeline implemented efficiently using the LOTUS API. Using the DeepScholar-bench framework, we perform a systematic evaluation of prior open-source systems, search AI's, OpenAI's DeepResearch, and DeepScholar-base. We find that DeepScholar-base establishes a strong baseline, attaining competitive or higher performance than each other method. We also find that DeepScholar-bench remains far from saturated, with no system exceeding a score of $19\%$ across all metrics. These results underscore the difficulty of DeepScholar-bench, as well as its importance for progress towards AI systems capable of generative research synthesis. We make our code available at https://github.com/guestrin-lab/deepscholar-bench.
GenCAD-Self-Repairing: Feasibility Enhancement for 3D CAD Generation
May 29, 2025With the advancement of generative AI, research on its application to 3D model generation has gained traction, particularly in automating the creation of Computer-Aided Design (CAD) files from images. GenCAD is a notable model in this domain, leveraging an autoregressive transformer-based architecture with a contrastive learning framework to generate CAD programs. However, a major limitation of GenCAD is its inability to consistently produce feasible boundary representations (B-reps), with approximately 10% of generated designs being infeasible. To address this, we propose GenCAD-Self-Repairing, a framework that enhances the feasibility of generative CAD models through diffusion guidance and a self-repairing pipeline. This framework integrates a guided diffusion denoising process in the latent space and a regression-based correction mechanism to refine infeasible CAD command sequences while preserving geometric accuracy. Our approach successfully converted two-thirds of infeasible designs in the baseline method into feasible ones, significantly improving the feasibility rate while simultaneously maintaining a reasonable level of geometric accuracy between the point clouds of ground truth models and generated models. By significantly improving the feasibility rate of generating CAD models, our approach helps expand the availability of high-quality training data and enhances the applicability of AI-driven CAD generation in manufacturing, architecture, and product design.
AutoRev: Automatic Peer Review System for Academic Research Papers
May 20, 2025Generating a review for an academic research paper is a complex task that requires a deep understanding of the document's content and the interdependencies between its sections. It demands not only insight into technical details but also an appreciation of the paper's overall coherence and structure. Recent methods have predominantly focused on fine-tuning large language models (LLMs) to address this challenge. However, they often overlook the computational and performance limitations imposed by long input token lengths. To address this, we introduce AutoRev, an Automatic Peer Review System for Academic Research Papers. Our novel framework represents an academic document as a graph, enabling the extraction of the most critical passages that contribute significantly to the review. This graph-based approach demonstrates effectiveness for review generation and is potentially adaptable to various downstream tasks, such as question answering, summarization, and document representation. When applied to review generation, our method outperforms SOTA baselines by an average of 58.72% across all evaluation metrics. We hope that our work will stimulate further research in applying graph-based extraction techniques to other downstream tasks in NLP. We plan to make our code public upon acceptance.
Towards Understanding the Robustness of LLM-based Evaluations under Perturbations
Dec 12, 2024
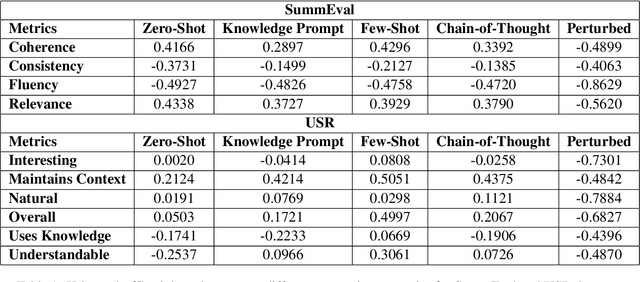
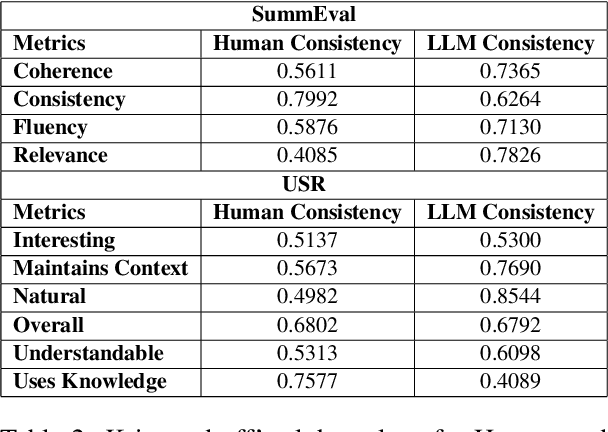
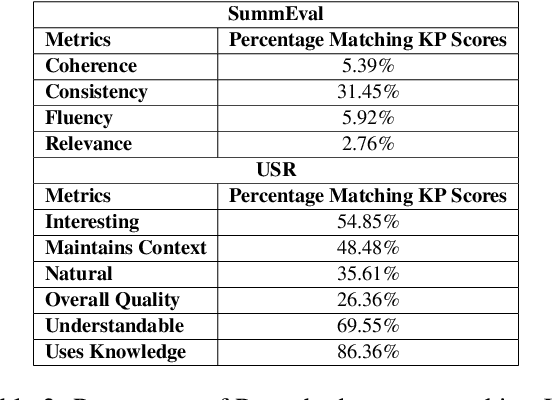
Traditional evaluation metrics like BLEU and ROUGE fall short when capturing the nuanced qualities of generated text, particularly when there is no single ground truth. In this paper, we explore the potential of Large Language Models (LLMs), specifically Google Gemini 1, to serve as automatic evaluators for non-standardized metrics in summarization and dialog-based tasks. We conduct experiments across multiple prompting strategies to examine how LLMs fare as quality evaluators when compared with human judgments on the SummEval and USR datasets, asking the model to generate both a score as well as a justification for the score. Furthermore, we explore the robustness of the LLM evaluator by using perturbed inputs. Our findings suggest that while LLMs show promise, their alignment with human evaluators is limited, they are not robust against perturbations and significant improvements are required for their standalone use as reliable evaluators for subjective metrics.
iREL at SemEval-2024 Task 9: Improving Conventional Prompting Methods for Brain Teasers
May 25, 2024
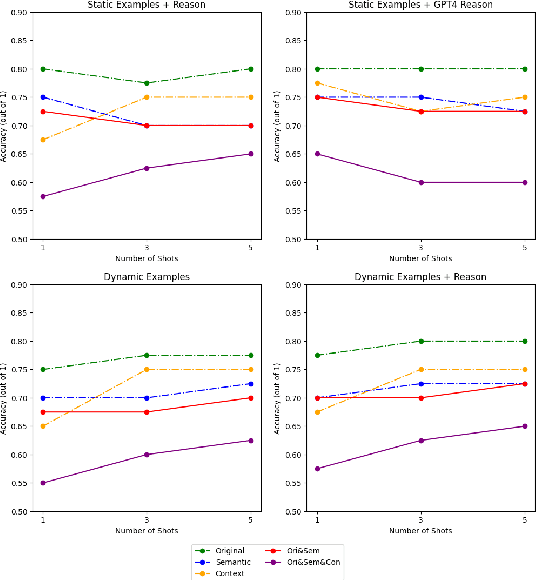
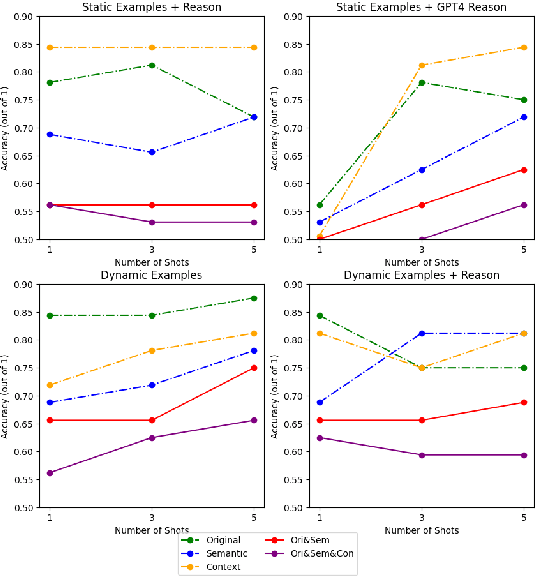
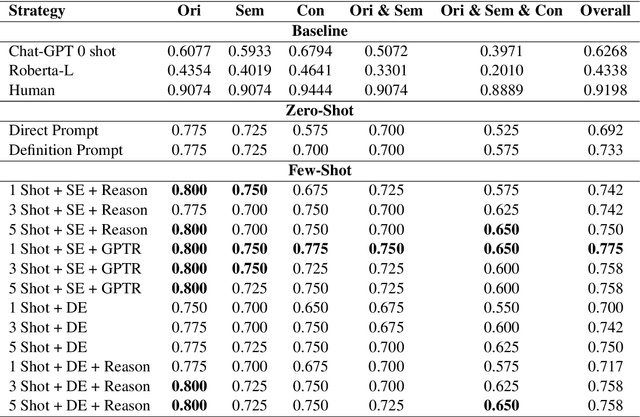
This paper describes our approach for SemEval-2024 Task 9: BRAINTEASER: A Novel Task Defying Common Sense. The BRAINTEASER task comprises multiple-choice Question Answering designed to evaluate the models' lateral thinking capabilities. It consists of Sentence Puzzle and Word Puzzle subtasks that require models to defy default common-sense associations and exhibit unconventional thinking. We propose a unique strategy to improve the performance of pre-trained language models, notably the Gemini 1.0 Pro Model, in both subtasks. We employ static and dynamic few-shot prompting techniques and introduce a model-generated reasoning strategy that utilizes the LLM's reasoning capabilities to improve performance. Our approach demonstrated significant improvements, showing that it performed better than the baseline models by a considerable margin but fell short of performing as well as the human annotators, thus highlighting the efficacy of the proposed strategies.
BrainStorm @ iREL at SMM4H 2024: Leveraging Translation and Topical Embeddings for Annotation Detection in Tweets
May 18, 2024
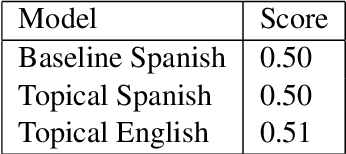
The proliferation of LLMs in various NLP tasks has sparked debates regarding their reliability, particularly in annotation tasks where biases and hallucinations may arise. In this shared task, we address the challenge of distinguishing annotations made by LLMs from those made by human domain experts in the context of COVID-19 symptom detection from tweets in Latin American Spanish. This paper presents BrainStorm @ iREL's approach to the SMM4H 2024 Shared Task, leveraging the inherent topical information in tweets, we propose a novel approach to identify and classify annotations, aiming to enhance the trustworthiness of annotated data.
Neural models for Factual Inconsistency Classification with Explanations
Jun 15, 2023
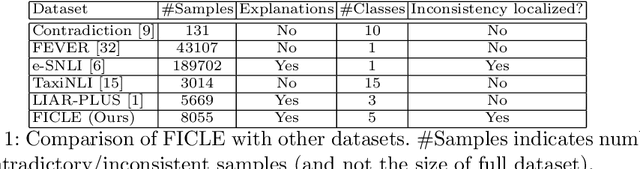

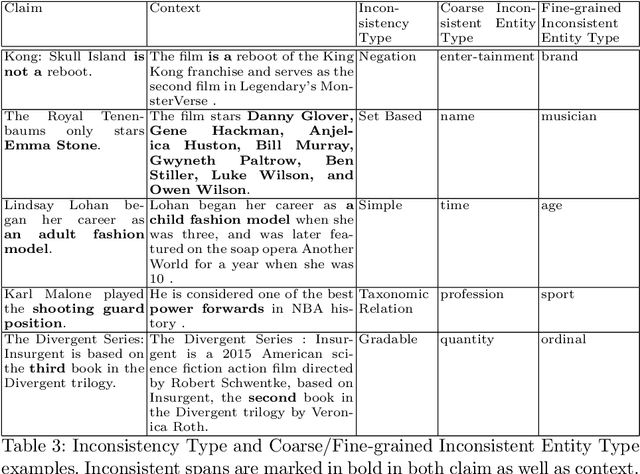
Factual consistency is one of the most important requirements when editing high quality documents. It is extremely important for automatic text generation systems like summarization, question answering, dialog modeling, and language modeling. Still, automated factual inconsistency detection is rather under-studied. Existing work has focused on (a) finding fake news keeping a knowledge base in context, or (b) detecting broad contradiction (as part of natural language inference literature). However, there has been no work on detecting and explaining types of factual inconsistencies in text, without any knowledge base in context. In this paper, we leverage existing work in linguistics to formally define five types of factual inconsistencies. Based on this categorization, we contribute a novel dataset, FICLE (Factual Inconsistency CLassification with Explanation), with ~8K samples where each sample consists of two sentences (claim and context) annotated with type and span of inconsistency. When the inconsistency relates to an entity type, it is labeled as well at two levels (coarse and fine-grained). Further, we leverage this dataset to train a pipeline of four neural models to predict inconsistency type with explanations, given a (claim, context) sentence pair. Explanations include inconsistent claim fact triple, inconsistent context span, inconsistent claim component, coarse and fine-grained inconsistent entity types. The proposed system first predicts inconsistent spans from claim and context; and then uses them to predict inconsistency types and inconsistent entity types (when inconsistency is due to entities). We experiment with multiple Transformer-based natural language classification as well as generative models, and find that DeBERTa performs the best. Our proposed methods provide a weighted F1 of ~87% for inconsistency type classification across the five classes.
Assessment of DeepONet for reliability analysis of stochastic nonlinear dynamical systems
Jan 31, 2022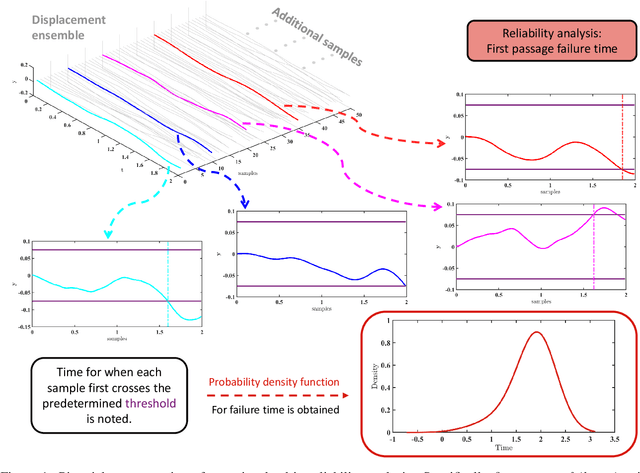

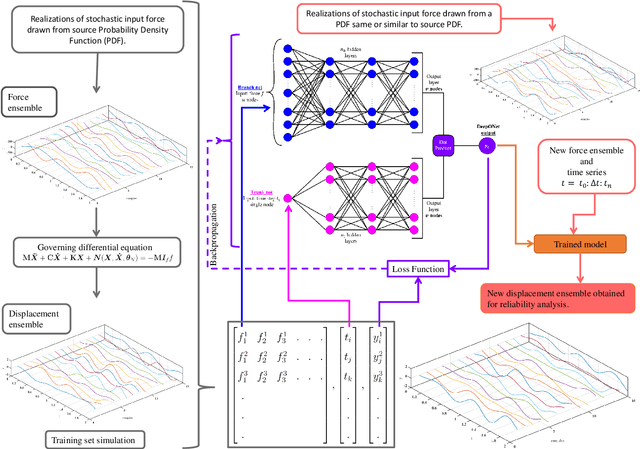
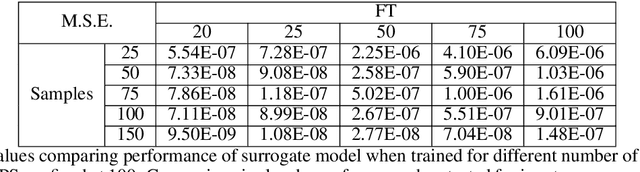
Time dependent reliability analysis and uncertainty quantification of structural system subjected to stochastic forcing function is a challenging endeavour as it necessitates considerable computational time. We investigate the efficacy of recently proposed DeepONet in solving time dependent reliability analysis and uncertainty quantification of systems subjected to stochastic loading. Unlike conventional machine learning and deep learning algorithms, DeepONet learns is a operator network and learns a function to function mapping and hence, is ideally suited to propagate the uncertainty from the stochastic forcing function to the output responses. We use DeepONet to build a surrogate model for the dynamical system under consideration. Multiple case studies, involving both toy and benchmark problems, have been conducted to examine the efficacy of DeepONet in time dependent reliability analysis and uncertainty quantification of linear and nonlinear dynamical systems. Results obtained indicate that the DeepONet architecture is accurate as well as efficient. Moreover, DeepONet posses zero shot learning capabilities and hence, a trained model easily generalizes to unseen and new environment with no further training.
End-to-End Simultaneous Learning of Single-particle Orientation and 3D Map Reconstruction from Cryo-electron Microscopy Data
Jul 07, 2021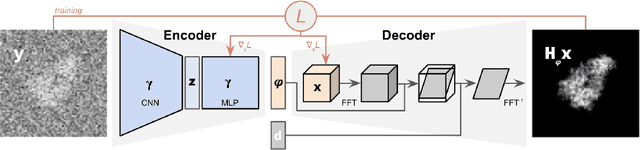
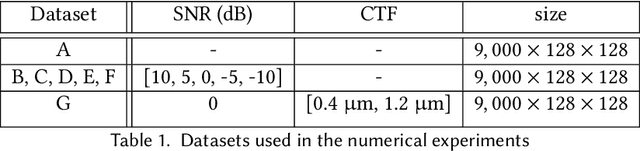
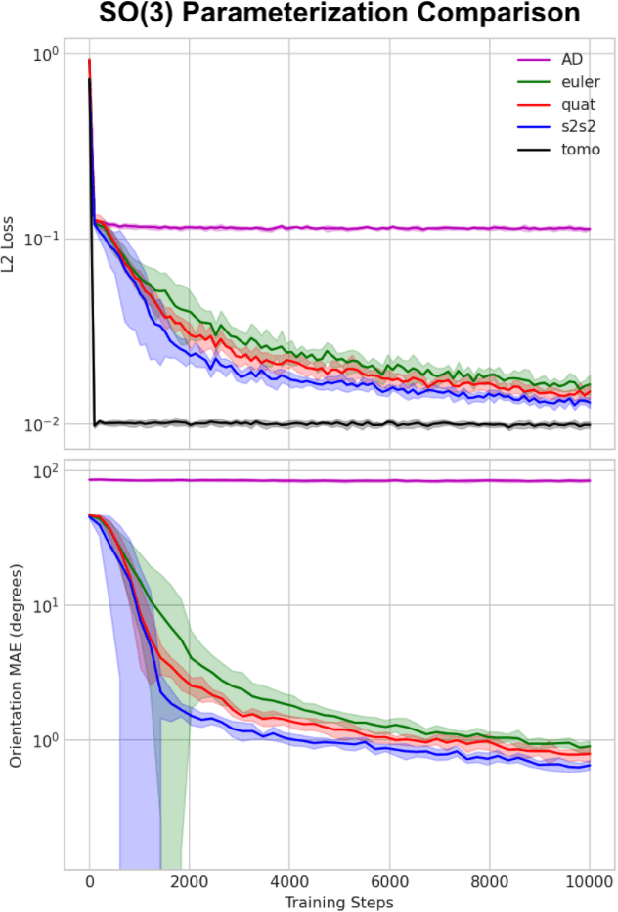
Cryogenic electron microscopy (cryo-EM) provides images from different copies of the same biomolecule in arbitrary orientations. Here, we present an end-to-end unsupervised approach that learns individual particle orientations from cryo-EM data while reconstructing the average 3D map of the biomolecule, starting from a random initialization. The approach relies on an auto-encoder architecture where the latent space is explicitly interpreted as orientations used by the decoder to form an image according to the linear projection model. We evaluate our method on simulated data and show that it is able to reconstruct 3D particle maps from noisy- and CTF-corrupted 2D projection images of unknown particle orientations.
Deep Neural Networks with Trainable Activations and Controlled Lipschitz Constant
Jan 17, 2020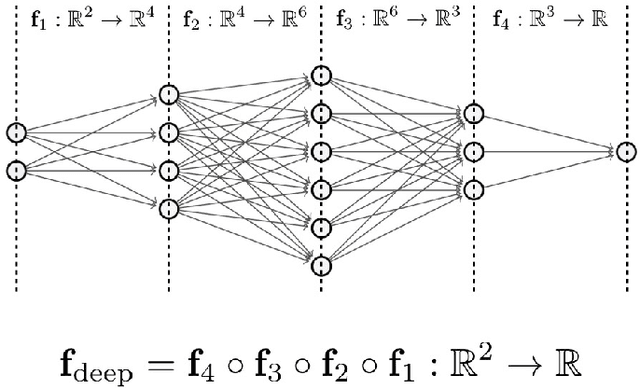
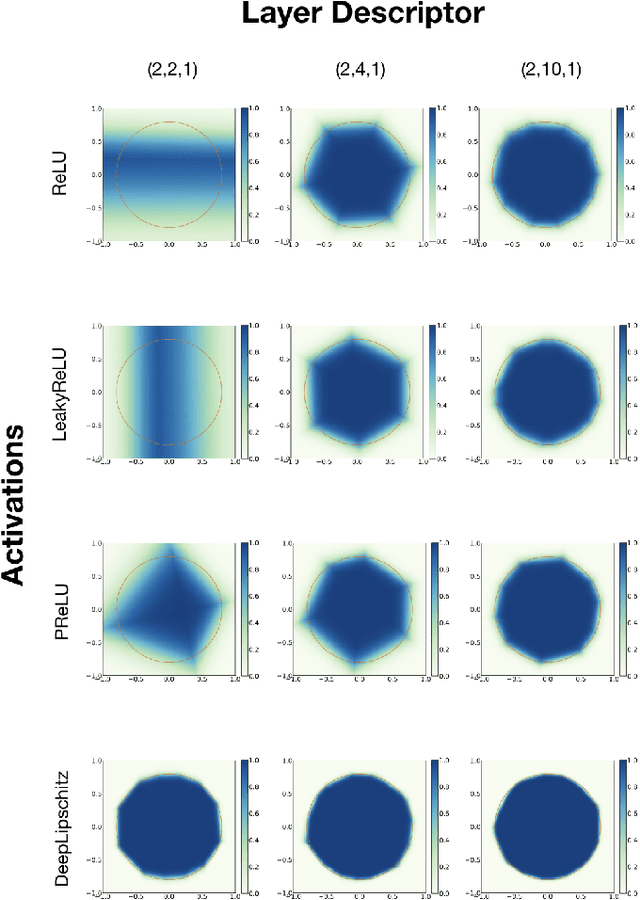
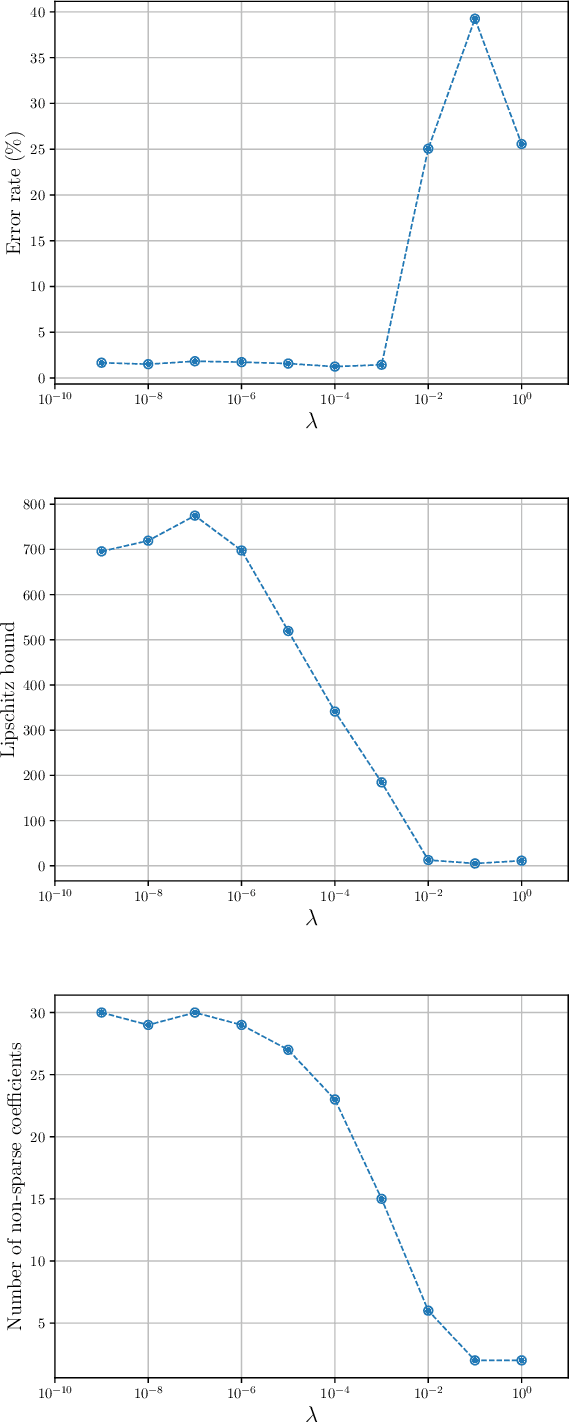
We introduce a variational framework to learn the activation functions of deep neural networks. The main motivation is to control the Lipschitz regularity of the input-output relation. To that end, we first establish a global bound for the Lipschitz constant of neural networks. Based on the obtained bound, we then formulate a variational problem for learning activation functions. Our variational problem is infinite-dimensional and is not computationally tractable. However, we prove that there always exists a solution that has continuous and piecewise-linear (linear-spline) activations. This reduces the original problem to a finite-dimensional minimization. We numerically compare our scheme with standard ReLU network and its variations, PReLU and LeakyReLU.