 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Optimization: A Systems-Based Approach to Social Externalities
Jun 15, 2025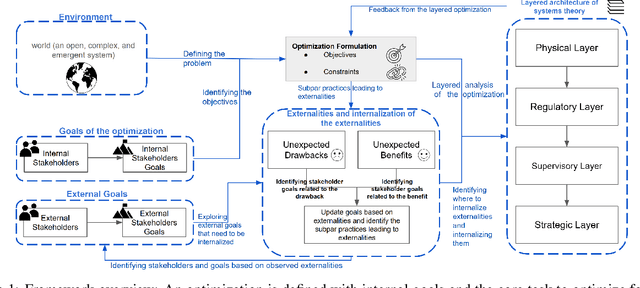



Optimization is widely used for decision making across various domains, valued for its ability to improve efficiency. However, poor implementation practices can lead to unintended consequences, particularly in socioeconomic contexts where externalities (costs or benefits to third parties outside the optimization process) are significant. To propose solutions, it is crucial to first characterize involved stakeholders, their goals, and the types of subpar practices causing unforeseen outcomes. This task is complex because affected stakeholders often fall outside the direct focus of optimization processes. Also, incorporating these externalities into optimization requires going beyond traditional economic frameworks, which often focus on describing externalities but fail to address their normative implications or interconnected nature, and feedback loops. This paper suggests a framework that combines systems thinking with the economic concept of externalities to tackle these challenges. This approach aims to characterize what went wrong, who was affected, and how (or where) to include them in the optimization process. Economic externalities, along with their established quantification methods, assist in identifying "who was affected and how" through stakeholder characterization. Meanwhile, systems thinking (an analytical approach to comprehending relationships in complex systems) provides a holistic, normative perspective. Systems thinking contributes to an understanding of interconnections among externalities, feedback loops, and determining "when" to incorporate them in the optimization. Together, these approaches create a comprehensive framework for addressing optimization's unintended consequences, balancing descriptive accuracy with normative objectives. Using this, we examine three common types of subpar practices: ignorance, error, and prioritization of short-term goals.
Counting Hours, Counting Losses: The Toll of Unpredictable Work Schedules on Financial Security
Apr 10, 2025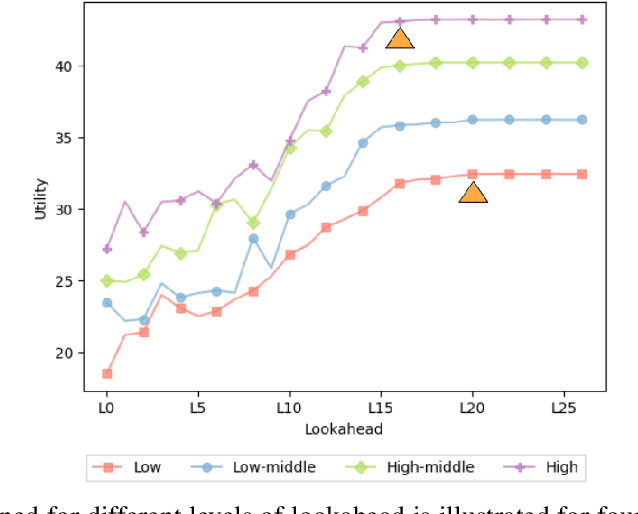
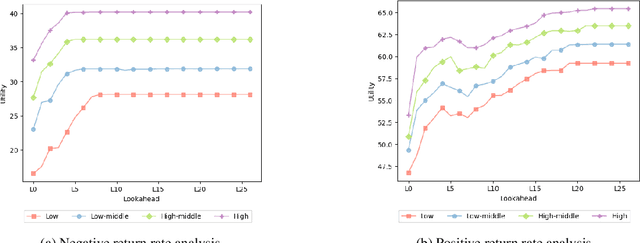
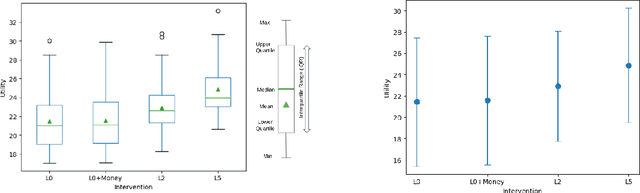
Financial instability has become a significant issue in today's society. While research typically focuses on financial aspects, there is a tendency to overlook time-related aspects of unstable work schedules. The inability to rely on consistent work schedules leads to burnout, work-family conflicts, and financial shocks that directly impact workers' income and assets. Unforeseen fluctuations in earnings pose challenges in financial planning, affecting decisions on savings and spending and ultimately undermining individuals' long-term financial stability and well-being. This issue is particularly evident in sectors where workers experience frequently changing schedules without sufficient notice, including those in the food service and retail sectors, part-time and hourly workers, and individuals with lower incomes. These groups are already more financially vulnerable, and the unpredictable nature of their schedules exacerbates their financial fragility. Our objective is to understand how unforeseen fluctuations in earnings exacerbate financial fragility by investigating the extent to which individuals' financial management depends on their ability to anticipate and plan for the future. To address this question, we develop a simulation framework that models how individuals optimize utility amidst financial uncertainty and the imperative to avoid financial ruin. We employ online learning techniques, specifically adapting workers' consumption policies based on evolving information about their work schedules. With this framework, we show both theoretically and empirically how a worker's capacity to anticipate schedule changes enhances their long-term utility. Conversely, the inability to predict future events can worsen workers' instability. Moreover, our framework enables us to explore interventions to mitigate the problem of schedule uncertainty and evaluate their effectiveness.
Precarity: Modeling the Long Term Effects of Compounded Decisions on Individual Instability
Apr 24, 2021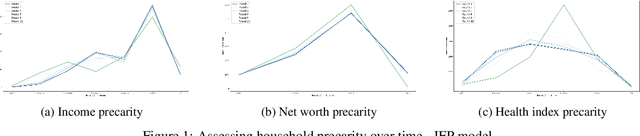
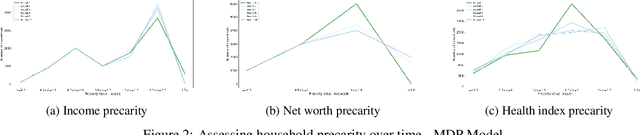
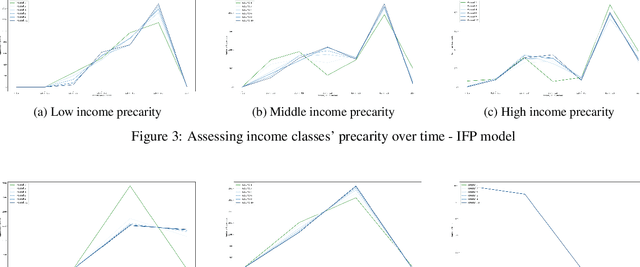
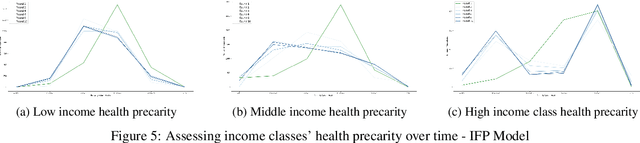
When it comes to studying the impacts of decision making, the research has been largely focused on examining the fairness of the decisions, the long-term effects of the decision pipelines, and utility-based perspectives considering both the decision-maker and the individuals. However, there has hardly been any focus on precarity which is the term that encapsulates the instability in people's lives. That is, a negative outcome can overspread to other decisions and measures of well-being. Studying precarity necessitates a shift in focus - from the point of view of the decision-maker to the perspective of the decision subject. This centering of the subject is an important direction that unlocks the importance of parting with aggregate measures to examine the long-term effects of decision making. To address this issue, in this paper, we propose a modeling framework that simulates the effects of compounded decision-making on precarity over time. Through our simulations, we are able to show the heterogeneity of precarity by the non-uniform ruinous aftereffects of negative decisions on different income classes of the underlying population and how policy interventions can help mitigate such effects.
P-SIF: Document Embeddings Using Partition Averaging
May 18, 2020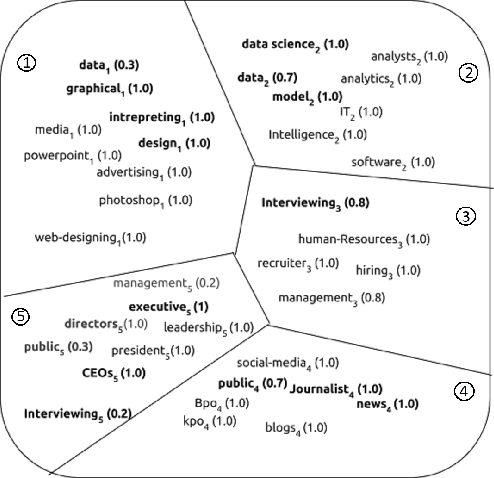


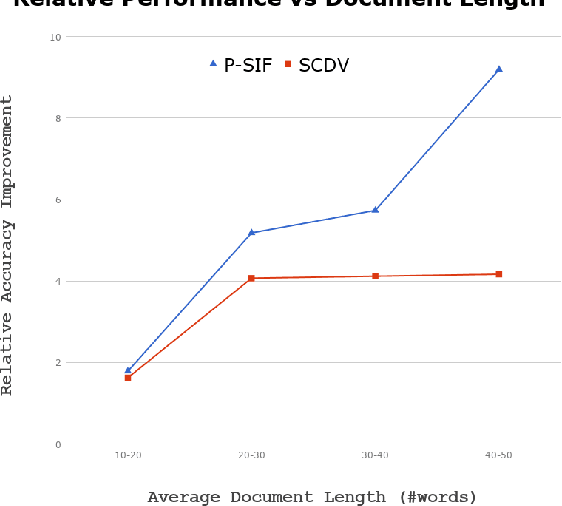
Simple weighted averaging of word vectors often yields effective representations for sentences which outperform sophisticated seq2seq neural models in many tasks. While it is desirable to use the same method to represent documents as well, unfortunately, the effectiveness is lost when representing long documents involving multiple sentences. One of the key reasons is that a longer document is likely to contain words from many different topics; hence, creating a single vector while ignoring all the topical structure is unlikely to yield an effective document representation. This problem is less acute in single sentences and other short text fragments where the presence of a single topic is most likely. To alleviate this problem, we present P-SIF, a partitioned word averaging model to represent long documents. P-SIF retains the simplicity of simple weighted word averaging while taking a document's topical structure into account. In particular, P-SIF learns topic-specific vectors from a document and finally concatenates them all to represent the overall document. We provide theoretical justifications on the correctness of P-SIF. Through a comprehensive set of experiments, we demonstrate P-SIF's effectiveness compared to simple weighted averaging and many other baselines.
INFOTABS: Inference on Tables as Semi-structured Data
May 13, 2020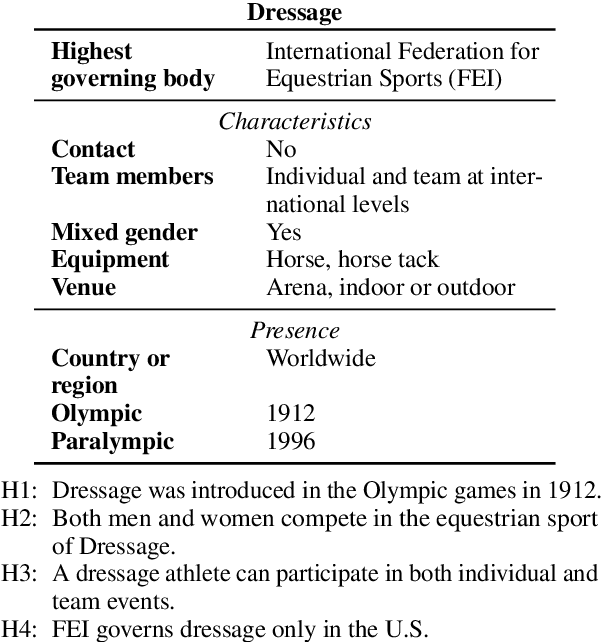
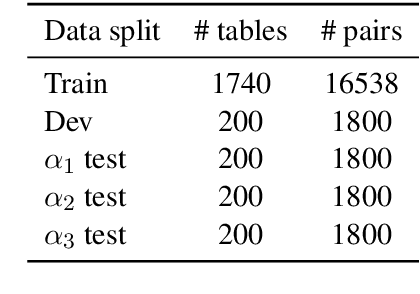

In this paper, we observe that semi-structured tabulated text is ubiquitous; understanding them requires not only comprehending the meaning of text fragments, but also implicit relationships between them. We argue that such data can prove as a testing ground for understanding how we reason about information. To study this, we introduce a new dataset called INFOTABS, comprising of human-written textual hypotheses based on premises that are tables extracted from Wikipedia info-boxes. Our analysis shows that the semi-structured, multi-domain and heterogeneous nature of the premises admits complex, multi-faceted reasoning. Experiments reveal that, while human annotators agree on the relationships between a table-hypothesis pair, several standard modeling strategies are unsuccessful at the task, suggesting that reasoning about tables can pose a difficult modeling challenge.
Improving Document Classification with Multi-Sense Embeddings
Nov 18, 2019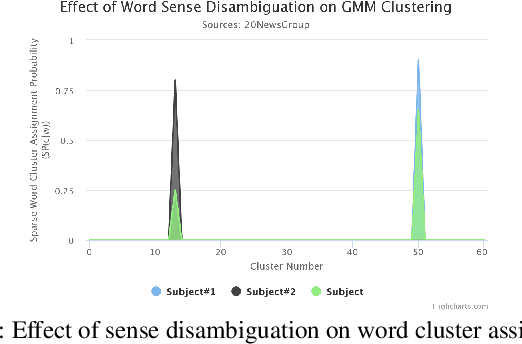

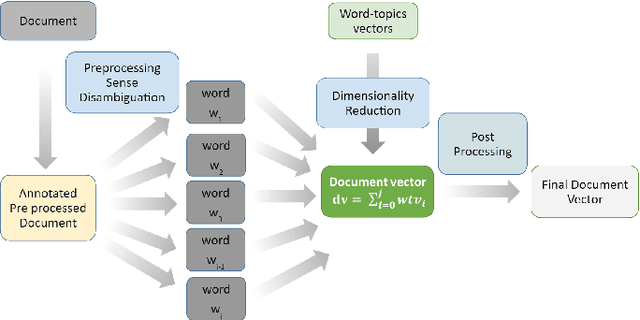
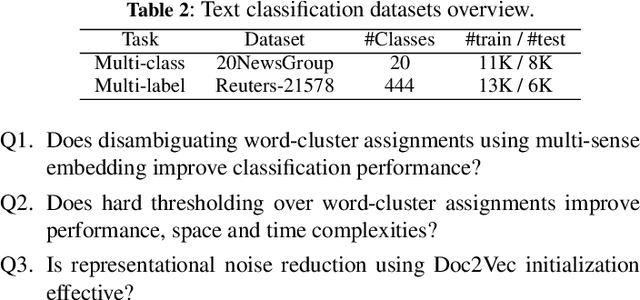
Efficient representation of text documents is an important building block in many NLP tasks. Research on long text categorization has shown that simple weighted averaging of word vectors for sentence representation often outperforms more sophisticated neural models. Recently proposed Sparse Composite Document Vector (SCDV) (Mekala et. al, 2017) extends this approach from sentences to documents using soft clustering over word vectors. However, SCDV disregards the multi-sense nature of words, and it also suffers from the curse of higher dimensionality. In this work, we address these shortcomings and propose SCDV-MS. SCDV-MS utilizes multi-sense word embeddings and learns a lower dimensional manifold. Through extensive experiments on multiple real-world datasets, we show that SCDV-MS embeddings outperform previous state-of-the-art embeddings on multi-class and multi-label text categorization tasks. Furthermore, SCDV-MS embeddings are more efficient than SCDV in terms of time and space complexity on textual classification tasks.
Equalizing Recourse across Groups
Sep 07, 2019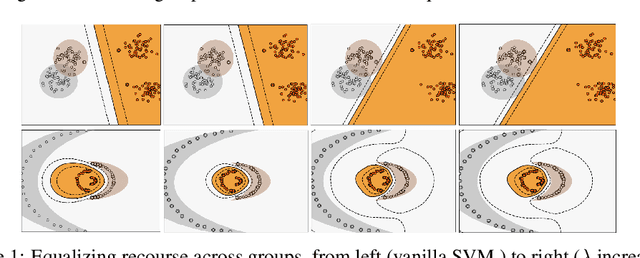
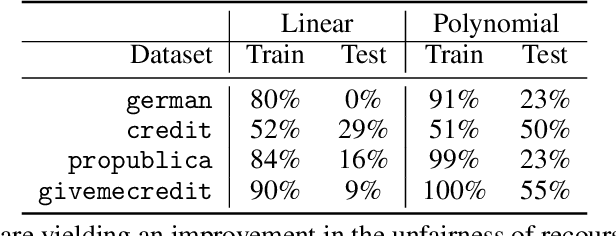

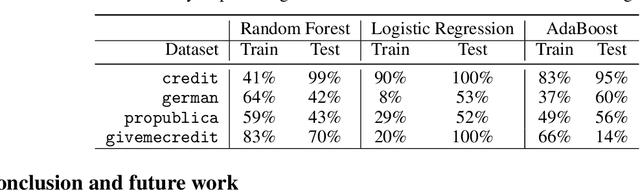
The rise in machine learning-assisted decision-making has led to concerns about the fairness of the decisions and techniques to mitigate problems of discrimination. If a negative decision is made about an individual (denying a loan, rejecting an application for housing, and so on) justice dictates that we be able to ask how we might change circumstances to get a favorable decision the next time. Moreover, the ability to change circumstances (a better education, improved credentials) should not be limited to only those with access to expensive resources. In other words, \emph{recourse} for negative decisions should be considered a desirable value that can be equalized across (demographically defined) groups. This paper describes how to build models that make accurate predictions while still ensuring that the penalties for a negative outcome do not disadvantage different groups disproportionately. We measure recourse as the distance of an individual from the decision boundary of a classifier. We then introduce a regularized objective to minimize the difference in recourse across groups. We explore linear settings and further extend recourse to non-linear settings as well as model-agnostic settings where the exact distance from boundary cannot be calculated. Our results show that we can successfully decrease the unfairness in recourse while maintaining classifier performance.