 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-lingual Functional Evaluation for Large Language Models
Jun 25, 2025Multi-lingual competence in large language models is often evaluated via static data benchmarks such as Belebele, M-MMLU and M-GSM. However, these evaluations often fail to provide an adequate understanding of the practical performance and robustness of models across multi-lingual settings. In response, we create multi-lingual functional benchmarks -- Cross-Lingual Grade School Math Symbolic (CL-GSM Symbolic) and Cross-Lingual Instruction-Following Eval (CL-IFEval)-- by translating existing functional benchmark templates from English to five additional languages that span the range of resources available for NLP: French, Spanish, Hindi, Arabic and Yoruba. Our results reveal that some static multi-lingual benchmarks capture functional performance much more closely than others (i.e. across models, there is a 24%, 17% and 18% decrease in performance between M-GSM and CL-GSM Symbolic in English, French and Spanish respectively; similarly there's a 15 - 24% performance drop across languages between Belebele and CL-IFEval, and only a 0.5% to 3% performance drop between M-MMLU and CL-IFEval). Similarly, we find that model robustness across languages varies significantly, with certain languages (eg. Arabic, English) being the most consistently well performing across evaluation iterations.
Counting Hours, Counting Losses: The Toll of Unpredictable Work Schedules on Financial Security
Apr 10, 2025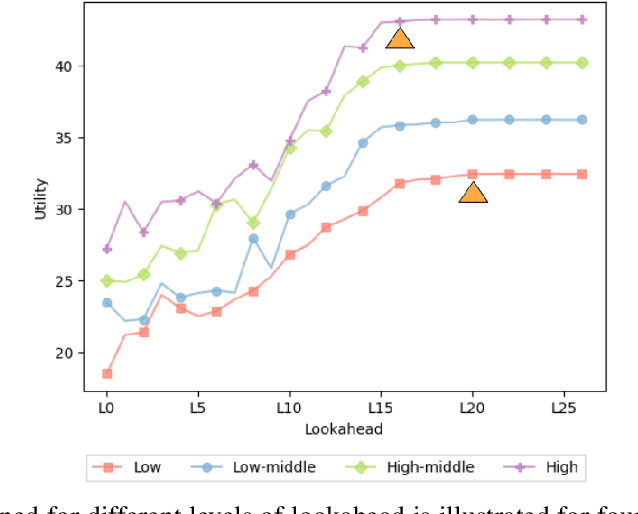
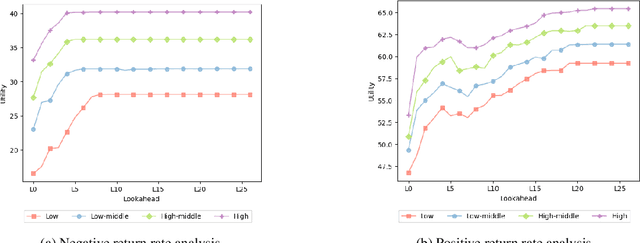
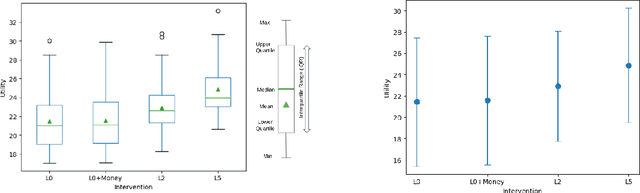
Financial instability has become a significant issue in today's society. While research typically focuses on financial aspects, there is a tendency to overlook time-related aspects of unstable work schedules. The inability to rely on consistent work schedules leads to burnout, work-family conflicts, and financial shocks that directly impact workers' income and assets. Unforeseen fluctuations in earnings pose challenges in financial planning, affecting decisions on savings and spending and ultimately undermining individuals' long-term financial stability and well-being. This issue is particularly evident in sectors where workers experience frequently changing schedules without sufficient notice, including those in the food service and retail sectors, part-time and hourly workers, and individuals with lower incomes. These groups are already more financially vulnerable, and the unpredictable nature of their schedules exacerbates their financial fragility. Our objective is to understand how unforeseen fluctuations in earnings exacerbate financial fragility by investigating the extent to which individuals' financial management depends on their ability to anticipate and plan for the future. To address this question, we develop a simulation framework that models how individuals optimize utility amidst financial uncertainty and the imperative to avoid financial ruin. We employ online learning techniques, specifically adapting workers' consumption policies based on evolving information about their work schedules. With this framework, we show both theoretically and empirically how a worker's capacity to anticipate schedule changes enhances their long-term utility. Conversely, the inability to predict future events can worsen workers' instability. Moreover, our framework enables us to explore interventions to mitigate the problem of schedule uncertainty and evaluate their effectiveness.
Navigating Dialectal Bias and Ethical Complexities in Levantine Arabic Hate Speech Detection
Dec 14, 2024
Social media platforms have become central to global communication, yet they also facilitate the spread of hate speech. For underrepresented dialects like Levantine Arabic, detecting hate speech presents unique cultural, ethical, and linguistic challenges. This paper explores the complex sociopolitical and linguistic landscape of Levantine Arabic and critically examines the limitations of current datasets used in hate speech detection. We highlight the scarcity of publicly available, diverse datasets and analyze the consequences of dialectal bias within existing resources. By emphasizing the need for culturally and contextually informed natural language processing (NLP) tools, we advocate for a more nuanced and inclusive approach to hate speech detection in the Arab world.
Operationalizing the Blueprint for an AI Bill of Rights: Recommendations for Practitioners, Researchers, and Policy Makers
Jul 11, 2024As Artificial Intelligence (AI) tools are increasingly employed in diverse real-world applications, there has been significant interest in regulating these tools. To this end, several regulatory frameworks have been introduced by different countries worldwide. For example, the European Union recently passed the AI Act, the White House issued an Executive Order on safe, secure, and trustworthy AI, and the White House Office of Science and Technology Policy issued the Blueprint for an AI Bill of Rights (AI BoR). Many of these frameworks emphasize the need for auditing and improving the trustworthiness of AI tools, underscoring the importance of safety, privacy, explainability, fairness, and human fallback options. Although these regulatory frameworks highlight the necessity of enforcement, practitioners often lack detailed guidance on implementing them. Furthermore, the extensive research on operationalizing each of these aspects is frequently buried in technical papers that are difficult for practitioners to parse. In this write-up, we address this shortcoming by providing an accessible overview of existing literature related to operationalizing regulatory principles. We provide easy-to-understand summaries of state-of-the-art literature and highlight various gaps that exist between regulatory guidelines and existing AI research, including the trade-offs that emerge during operationalization. We hope that this work not only serves as a starting point for practitioners interested in learning more about operationalizing the regulatory guidelines outlined in the Blueprint for an AI BoR but also provides researchers with a list of critical open problems and gaps between regulations and state-of-the-art AI research. Finally, we note that this is a working paper and we invite feedback in line with the purpose of this document as described in the introduction.
To Pool or Not To Pool: Analyzing the Regularizing Effects of Group-Fair Training on Shared Models
Feb 29, 2024In fair machine learning, one source of performance disparities between groups is over-fitting to groups with relatively few training samples. We derive group-specific bounds on the generalization error of welfare-centric fair machine learning that benefit from the larger sample size of the majority group. We do this by considering group-specific Rademacher averages over a restricted hypothesis class, which contains the family of models likely to perform well with respect to a fair learning objective (e.g., a power-mean). Our simulations demonstrate these bounds improve over a naive method, as expected by theory, with particularly significant improvement for smaller group sizes.
Measuring and mitigating voting access disparities: a study of race and polling locations in Florida and North Carolina
May 30, 2022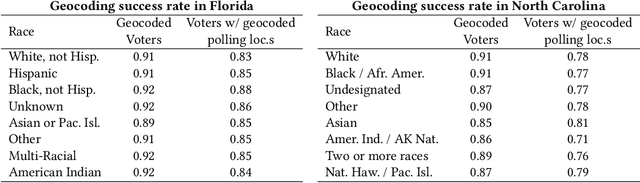

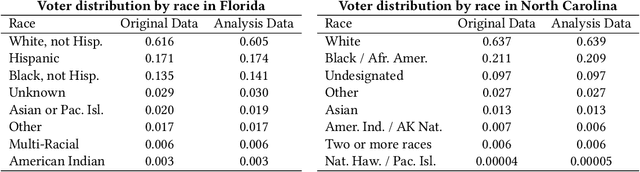

Voter suppression and associated racial disparities in access to voting are long-standing civil rights concerns in the United States. Barriers to voting have taken many forms over the decades. A history of violent explicit discouragement has shifted to more subtle access limitations that can include long lines and wait times, long travel times to reach a polling station, and other logistical barriers to voting. Our focus in this work is on quantifying disparities in voting access pertaining to the overall time-to-vote, and how they could be remedied via a better choice of polling location or provisioning more sites where voters can cast ballots. However, appropriately calibrating access disparities is difficult because of the need to account for factors such as population density and different community expectations for reasonable travel times. In this paper, we quantify access to polling locations, developing a methodology for the calibrated measurement of racial disparities in polling location "load" and distance to polling locations. We apply this methodology to a study of real-world data from Florida and North Carolina to identify disparities in voting access from the 2020 election. We also introduce algorithms, with modifications to handle scale, that can reduce these disparities by suggesting new polling locations from a given list of identified public locations (including schools and libraries). Applying these algorithms on the 2020 election location data also helps to expose and explore tradeoffs between the cost of allocating more polling locations and the potential impact on access disparities. The developed voting access measurement methodology and algorithmic remediation technique is a first step in better polling location assignment.
Precarity: Modeling the Long Term Effects of Compounded Decisions on Individual Instability
Apr 24, 2021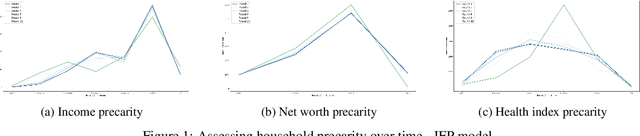
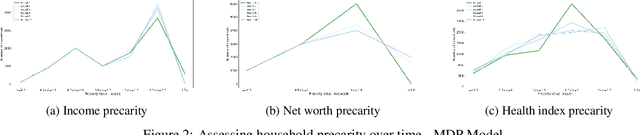
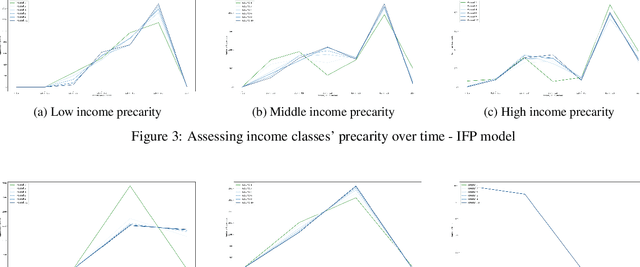
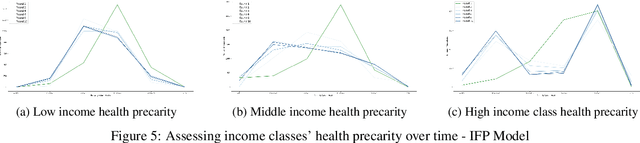
When it comes to studying the impacts of decision making, the research has been largely focused on examining the fairness of the decisions, the long-term effects of the decision pipelines, and utility-based perspectives considering both the decision-maker and the individuals. However, there has hardly been any focus on precarity which is the term that encapsulates the instability in people's lives. That is, a negative outcome can overspread to other decisions and measures of well-being. Studying precarity necessitates a shift in focus - from the point of view of the decision-maker to the perspective of the decision subject. This centering of the subject is an important direction that unlocks the importance of parting with aggregate measures to examine the long-term effects of decision making. To address this issue, in this paper, we propose a modeling framework that simulates the effects of compounded decision-making on precarity over time. Through our simulations, we are able to show the heterogeneity of precarity by the non-uniform ruinous aftereffects of negative decisions on different income classes of the underlying population and how policy interventions can help mitigate such effects.
Interdisciplinary Approaches to Understanding Artificial Intelligence's Impact on Society
Dec 11, 2020Innovations in AI have focused primarily on the questions of "what" and "how"-algorithms for finding patterns in web searches, for instance-without adequate attention to the possible harms (such as privacy, bias, or manipulation) and without adequate consideration of the societal context in which these systems operate. In part, this is driven by incentives and forces in the tech industry, where a more product-driven focus tends to drown out broader reflective concerns about potential harms and misframings. But this focus on what and how is largely a reflection of the engineering and mathematics-focused training in computer science, which emphasizes the building of tools and development of computational concepts. As a result of this tight technical focus, and the rapid, worldwide explosion in its use, AI has come with a storm of unanticipated socio-technical problems, ranging from algorithms that act in racially or gender-biased ways, get caught in feedback loops that perpetuate inequalities, or enable unprecedented behavioral monitoring surveillance that challenges the fundamental values of free, democratic societies. Given that AI is no longer solely the domain of technologists but rather of society as a whole, we need tighter coupling of computer science and those disciplines that study society and societal values.
Fair clustering via equitable group representations
Jun 19, 2020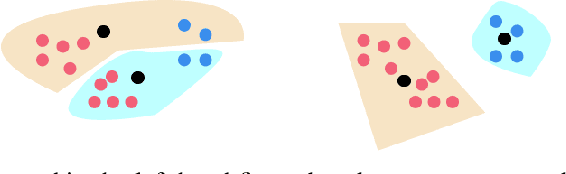

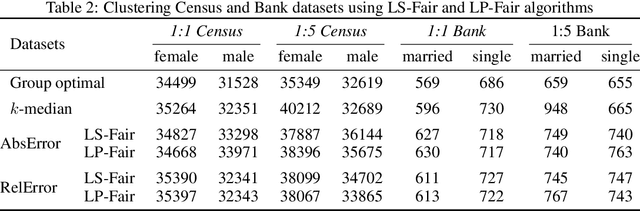
What does it mean for a clustering to be fair? One popular approach seeks to ensure that each cluster contains groups in (roughly) the same proportion in which they exist in the population. The normative principle at play is balance: any cluster might act as a representative of the data, and thus should reflect its diversity. But clustering also captures a different form of representativeness. A core principle in most clustering problems is that a cluster center should be representative of the cluster it represents, by being "close" to the points associated with it. This is so that we can effectively replace the points by their cluster centers without significant loss in fidelity, and indeed is a common "use case" for clustering. For such a clustering to be fair, the centers should "represent" different groups equally well. We call such a clustering a group-representative clustering. In this paper, we study the structure and computation of group-representative clusterings. We show that this notion naturally parallels the development of fairness notions in classification, with direct analogs of ideas like demographic parity and equal opportunity. We demonstrate how these notions are distinct from and cannot be captured by balance-based notions of fairness. We present approximation algorithms for group representative $k$-median clustering and couple this with an empirical evaluation on various real-world data sets.
Problems with Shapley-value-based explanations as feature importance measures
Feb 25, 2020
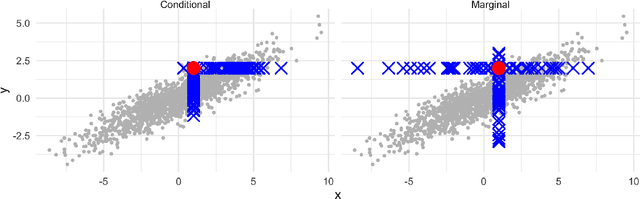
Game-theoretic formulations of feature importance have become popular as a way to "explain" machine learning models. These methods define a cooperative game between the features of a model and distribute influence among these input elements using some form of the game's unique Shapley values. Justification for these methods rests on two pillars: their desirable mathematical properties, and their applicability to specific motivations for explanations. We show that mathematical problems arise when Shapley values are used for feature importance and that the solutions to mitigate these necessarily induce further complexity, such as the need for causal reasoning. We also draw on additional literature to argue that Shapley values do not provide explanations which suit human-centric goals of explainability.