 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy and Carbon Considerations of Fine-Tuning BERT
Nov 17, 2023
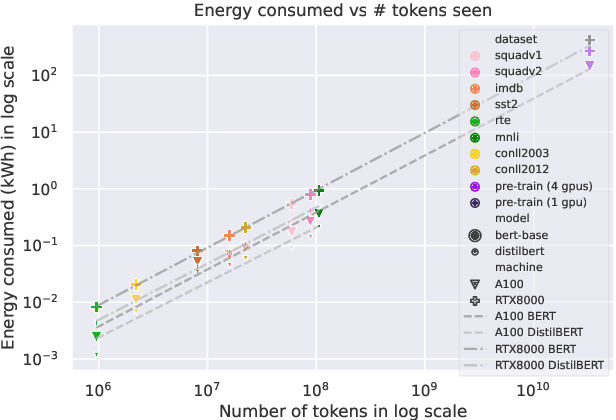
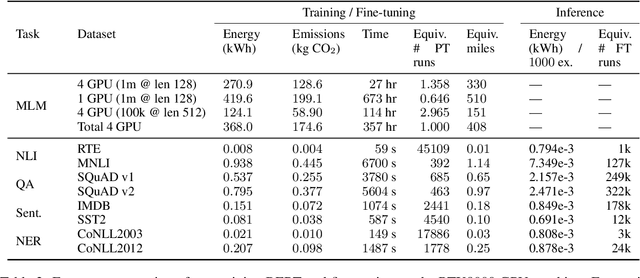

Despite the popularity of the `pre-train then fine-tune' paradigm in the NLP community, existing work quantifying energy costs and associated carbon emissions has largely focused on language model pre-training. Although a single pre-training run draws substantially more energy than fine-tuning, fine-tuning is performed more frequently by many more individual actors, and thus must be accounted for when considering the energy and carbon footprint of NLP. In order to better characterize the role of fine-tuning in the landscape of energy and carbon emissions in NLP, we perform a careful empirical study of the computational costs of fine-tuning across tasks, datasets, hardware infrastructure and measurement modalities. Our experimental results allow us to place fine-tuning energy and carbon costs into perspective with respect to pre-training and inference, and outline recommendations to NLP researchers and practitioners who wish to improve their fine-tuning energy efficiency.
Problems with Shapley-value-based explanations as feature importance measures
Feb 25, 2020
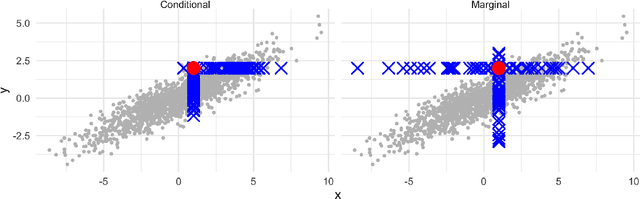
Game-theoretic formulations of feature importance have become popular as a way to "explain" machine learning models. These methods define a cooperative game between the features of a model and distribute influence among these input elements using some form of the game's unique Shapley values. Justification for these methods rests on two pillars: their desirable mathematical properties, and their applicability to specific motivations for explanations. We show that mathematical problems arise when Shapley values are used for feature importance and that the solutions to mitigate these necessarily induce further complexity, such as the need for causal reasoning. We also draw on additional literature to argue that Shapley values do not provide explanations which suit human-centric goals of explainability.
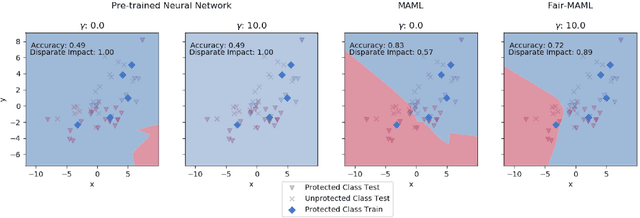
Fair Meta-Learning: Learning How to Learn Fairly
Nov 06, 2019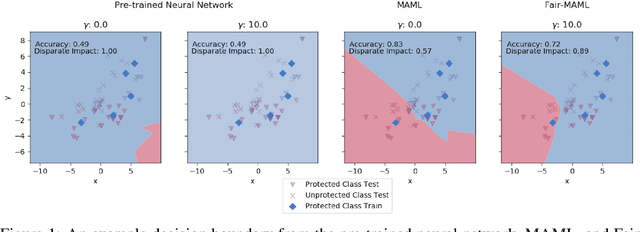
Data sets for fairness relevant tasks can lack examples or be biased according to a specific label in a sensitive attribute. We demonstrate the usefulness of weight based meta-learning approaches in such situations. For models that can be trained through gradient descent, we demonstrate that there are some parameter configurations that allow models to be optimized from a few number of gradient steps and with minimal data which are both fair and accurate. To learn such weight sets, we adapt the popular MAML algorithm to Fair-MAML by the inclusion of a fairness regularization term. In practice, Fair-MAML allows practitioners to train fair machine learning models from only a few examples when data from related tasks is available. We empirically exhibit the value of this technique by comparing to relevant baselines.
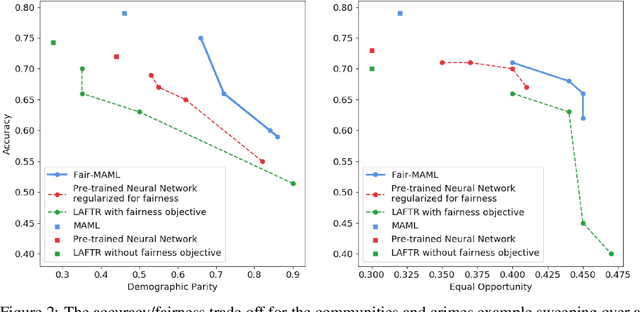
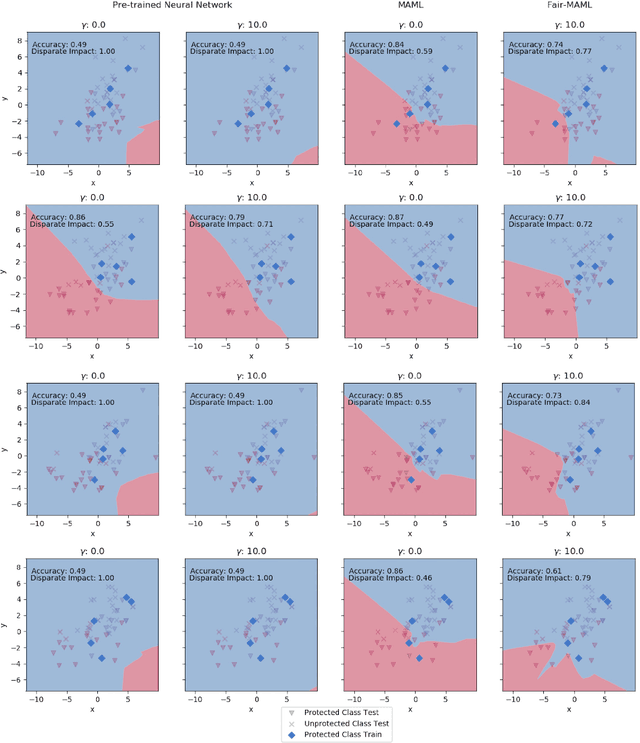
Fairness Warnings and Fair-MAML: Learning Fairly with Minimal Data
Aug 24, 2019
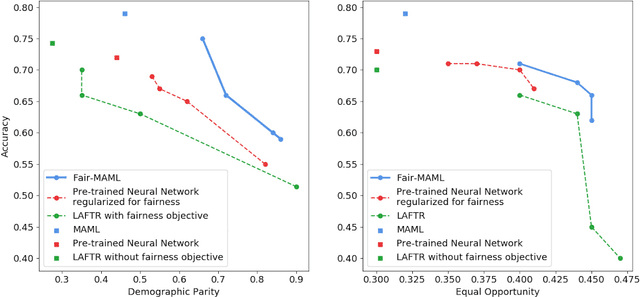

In this paper, we advocate for the study of fairness techniques in low data situations. We propose two algorithms Fairness Warnings and Fair-MAML. The first is a model-agnostic algorithm that provides interpretable boundary conditions for when a fairly trained model may not behave fairly on similar but slightly different tasks within a given domain. The second is a fair meta-learning approach to train models that can be trained through gradient descent with the objective of "learning how to learn fairly". This method encodes more general notions of fairness and accuracy into the model so that it can learn new tasks within a domain both quickly and fairly from only a few training points. We demonstrate experimentally the individual utility of each model using relevant baselines for comparison and provide the first experiment to our knowledge of K-shot fairness, i.e. training a fair model on a new task with only K data points. Then, we illustrate the usefulness of both algorithms as a combined method for training models from a few data points on new tasks while using Fairness Warnings as interpretable boundary conditions under which the newly trained model may not be fair.
Certifying and removing disparate impact
Jul 16, 2015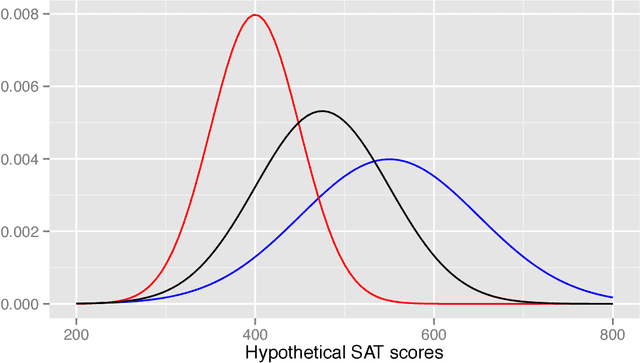
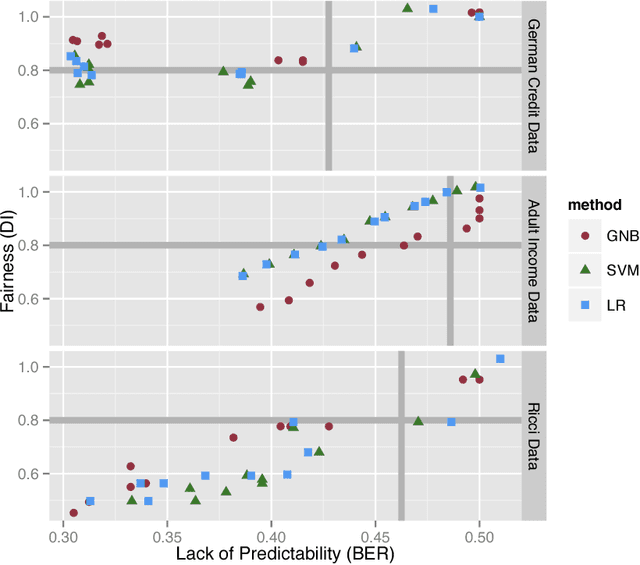

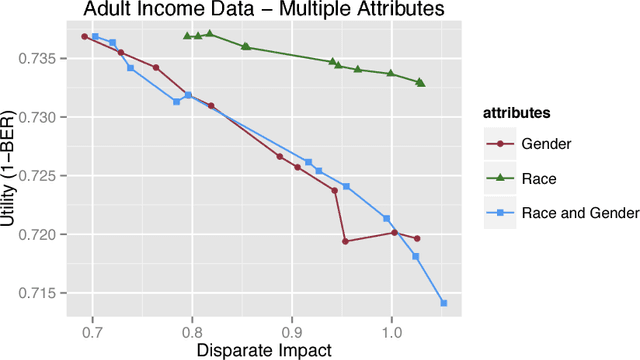
What does it mean for an algorithm to be biased? In U.S. law, unintentional bias is encoded via disparate impact, which occurs when a selection process has widely different outcomes for different groups, even as it appears to be neutral. This legal determination hinges on a definition of a protected class (ethnicity, gender, religious practice) and an explicit description of the process. When the process is implemented using computers, determining disparate impact (and hence bias) is harder. It might not be possible to disclose the process. In addition, even if the process is open, it might be hard to elucidate in a legal setting how the algorithm makes its decisions. Instead of requiring access to the algorithm, we propose making inferences based on the data the algorithm uses. We make four contributions to this problem. First, we link the legal notion of disparate impact to a measure of classification accuracy that while known, has received relatively little attention. Second, we propose a test for disparate impact based on analyzing the information leakage of the protected class from the other data attributes. Third, we describe methods by which data might be made unbiased. Finally, we present empirical evidence supporting the effectiveness of our test for disparate impact and our approach for both masking bias and preserving relevant information in the data. Interestingly, our approach resembles some actual selection practices that have recently received legal scrutiny.