 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Efficiency: Quantization, Batching, and Serving Strategies in LLM Energy Use
Jan 29, 2026Large Language Models (LLMs) are increasingly deployed in production, contributing towards shifting the burden in terms of computational resources and energy demands from training to inference. While prior work has examined the energy cost of inference per prompt or per token, we highlight how \emph{system-level design choices} - such as numerical precision, batching strategy, and request scheduling - can lead to orders-of-magnitude differences in energy consumption for the same model. We perform a detailed empirical study of LLM inference energy and latency on NVIDIA H100 GPUs, analyzing the impact of quantization, batch size, and serving configuration (e.g., with Hugging Face's Text Generation Inference server). Our results reveal that lower-precision formats only yield energy gains in compute-bound regimes; that batching improves energy efficiency, especially in memory-bound phases like decoding; and that structured request timing (arrival shaping) can reduce per-request energy by up to 100 times. We argue that sustainable LLM deployment depends not only on model internals, but also on the orchestration of the serving stack. Our findings motivate phase-aware energy profiling and system-level optimizations for greener AI services.
Small Talk, Big Impact: The Energy Cost of Thanking AI
Jan 29, 2026Being polite is free - or is it? In this paper, we quantify the energy cost of seemingly innocuous messages such as ``thank you'' when interacting with large language models, often used by users to convey politeness. Using real-world conversation traces and fine-grained energy measurements, we quantify how input length, output length and model size affect energy use. While politeness is our motivating example, it also serves as a controlled and reproducible proxy for measuring the energy footprint of a typical LLM interaction. Our findings provide actionable insights for building more sustainable and efficient LLM applications, especially in increasingly widespread real-world contexts like chat. As user adoption grows and billions of prompts are processed daily, understanding and mitigating this cost becomes crucial - not just for efficiency, but for sustainable AI deployment.
Energy Considerations of Large Language Model Inference and Efficiency Optimizations
Apr 24, 2025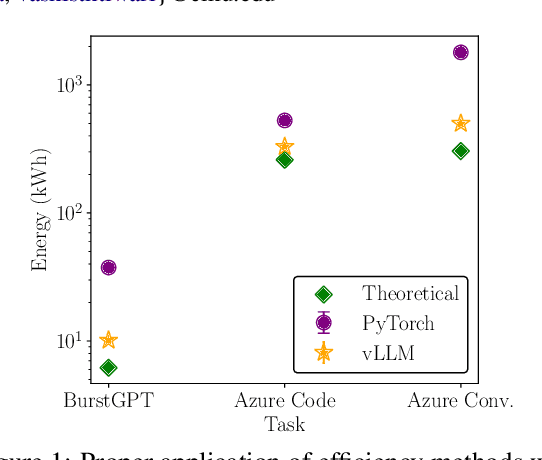
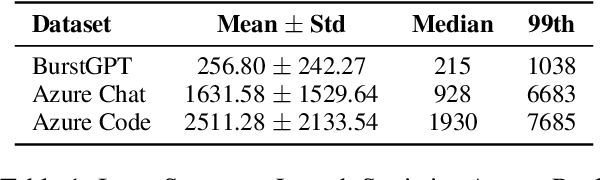
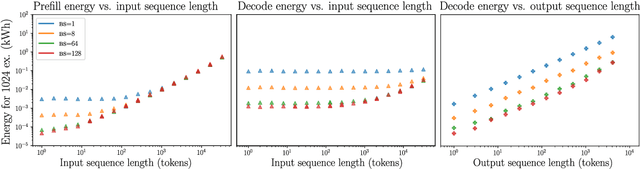

As large language models (LLMs) scale in size and adoption, their computational and environmental costs continue to rise. Prior benchmarking efforts have primarily focused on latency reduction in idealized settings, often overlooking the diverse real-world inference workloads that shape energy use. In this work, we systematically analyze the energy implications of common inference efficiency optimizations across diverse Natural Language Processing (NLP) and generative Artificial Intelligence (AI) workloads, including conversational AI and code generation. We introduce a modeling approach that approximates real-world LLM workflows through a binning strategy for input-output token distributions and batch size variations. Our empirical analysis spans software frameworks, decoding strategies, GPU architectures, online and offline serving settings, and model parallelism configurations. We show that the effectiveness of inference optimizations is highly sensitive to workload geometry, software stack, and hardware accelerators, demonstrating that naive energy estimates based on FLOPs or theoretical GPU utilization significantly underestimate real-world energy consumption. Our findings reveal that the proper application of relevant inference efficiency optimizations can reduce total energy use by up to 73% from unoptimized baselines. These insights provide a foundation for sustainable LLM deployment and inform energy-efficient design strategies for future AI infrastructure.
The Responsible Foundation Model Development Cheatsheet: A Review of Tools & Resources
Jun 26, 2024


Foundation model development attracts a rapidly expanding body of contributors, scientists, and applications. To help shape responsible development practices, we introduce the Foundation Model Development Cheatsheet: a growing collection of 250+ tools and resources spanning text, vision, and speech modalities. We draw on a large body of prior work to survey resources (e.g. software, documentation, frameworks, guides, and practical tools) that support informed data selection, processing, and understanding, precise and limitation-aware artifact documentation, efficient model training, advance awareness of the environmental impact from training, careful model evaluation of capabilities, risks, and claims, as well as responsible model release, licensing and deployment practices. We hope this curated collection of resources helps guide more responsible development. The process of curating this list, enabled us to review the AI development ecosystem, revealing what tools are critically missing, misused, or over-used in existing practices. We find that (i) tools for data sourcing, model evaluation, and monitoring are critically under-serving ethical and real-world needs, (ii) evaluations for model safety, capabilities, and environmental impact all lack reproducibility and transparency, (iii) text and particularly English-centric analyses continue to dominate over multilingual and multi-modal analyses, and (iv) evaluation of systems, rather than just models, is needed so that capabilities and impact are assessed in context.
Energy and Carbon Considerations of Fine-Tuning BERT
Nov 17, 2023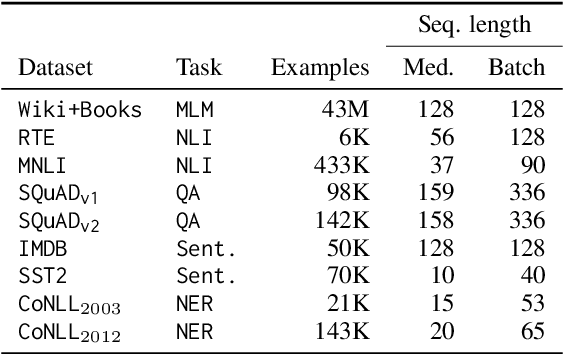
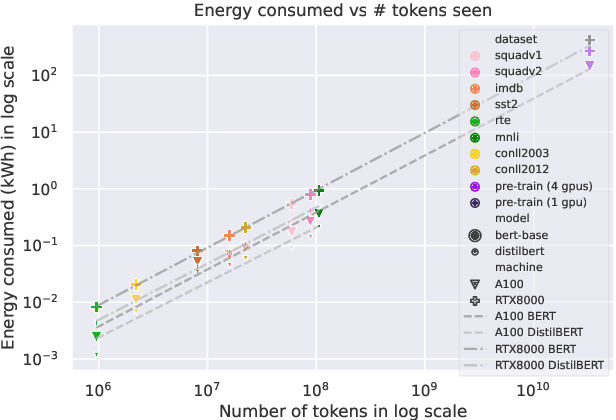
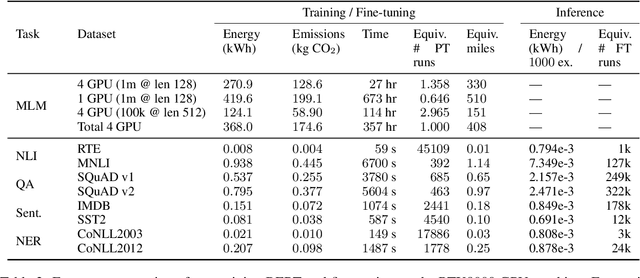

Despite the popularity of the `pre-train then fine-tune' paradigm in the NLP community, existing work quantifying energy costs and associated carbon emissions has largely focused on language model pre-training. Although a single pre-training run draws substantially more energy than fine-tuning, fine-tuning is performed more frequently by many more individual actors, and thus must be accounted for when considering the energy and carbon footprint of NLP. In order to better characterize the role of fine-tuning in the landscape of energy and carbon emissions in NLP, we perform a careful empirical study of the computational costs of fine-tuning across tasks, datasets, hardware infrastructure and measurement modalities. Our experimental results allow us to place fine-tuning energy and carbon costs into perspective with respect to pre-training and inference, and outline recommendations to NLP researchers and practitioners who wish to improve their fine-tuning energy efficiency.
StarCoder: may the source be with you!
May 09, 2023



The BigCode community, an open-scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder and StarCoderBase: 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. We perform the most comprehensive evaluation of Code LLMs to date and show that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model. Furthermore, StarCoder outperforms every model that is fine-tuned on Python, can be prompted to achieve 40\% pass@1 on HumanEval, and still retains its performance on other programming languages. We take several important steps towards a safe open-access model release, including an improved PII redaction pipeline and a novel attribution tracing tool, and make the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license.
Fair Diffusion: Instructing Text-to-Image Generation Models on Fairness
Feb 07, 2023Generative AI models have recently achieved astonishing results in quality and are consequently employed in a fast-growing number of applications. However, since they are highly data-driven, relying on billion-sized datasets randomly scraped from the internet, they also suffer from degenerated and biased human behavior, as we demonstrate. In fact, they may even reinforce such biases. To not only uncover but also combat these undesired effects, we present a novel strategy, called Fair Diffusion, to attenuate biases after the deployment of generative text-to-image models. Specifically, we demonstrate shifting a bias, based on human instructions, in any direction yielding arbitrarily new proportions for, e.g., identity groups. As our empirical evaluation demonstrates, this introduced control enables instructing generative image models on fairness, with no data filtering and additional training required.