 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExposing the Systematic Vulnerability of Open-Weight Models to Prefill Attacks
Feb 16, 2026As the capabilities of large language models continue to advance, so does their potential for misuse. While closed-source models typically rely on external defenses, open-weight models must primarily depend on internal safeguards to mitigate harmful behavior. Prior red-teaming research has largely focused on input-based jailbreaking and parameter-level manipulations. However, open-weight models also natively support prefilling, which allows an attacker to predefine initial response tokens before generation begins. Despite its potential, this attack vector has received little systematic attention. We present the largest empirical study to date of prefill attacks, evaluating over 20 existing and novel strategies across multiple model families and state-of-the-art open-weight models. Our results show that prefill attacks are consistently effective against all major contemporary open-weight models, revealing a critical and previously underexplored vulnerability with significant implications for deployment. While certain large reasoning models exhibit some robustness against generic prefilling, they remain vulnerable to tailored, model-specific strategies. Our findings underscore the urgent need for model developers to prioritize defenses against prefill attacks in open-weight LLMs.
Finding Dori: Memorization in Text-to-Image Diffusion Models Is Less Local Than Assumed
Jul 22, 2025Text-to-image diffusion models (DMs) have achieved remarkable success in image generation. However, concerns about data privacy and intellectual property remain due to their potential to inadvertently memorize and replicate training data. Recent mitigation efforts have focused on identifying and pruning weights responsible for triggering replication, based on the assumption that memorization can be localized. Our research assesses the robustness of these pruning-based approaches. We demonstrate that even after pruning, minor adjustments to text embeddings of input prompts are sufficient to re-trigger data replication, highlighting the fragility of these defenses. Furthermore, we challenge the fundamental assumption of memorization locality, by showing that replication can be triggered from diverse locations within the text embedding space, and follows different paths in the model. Our findings indicate that existing mitigation strategies are insufficient and underscore the need for methods that truly remove memorized content, rather than attempting to suppress its retrieval. As a first step in this direction, we introduce a novel adversarial fine-tuning method that iteratively searches for replication triggers and updates the model to increase robustness. Through our research, we provide fresh insights into the nature of memorization in text-to-image DMs and a foundation for building more trustworthy and compliant generative AI.
Navigating Shortcuts, Spurious Correlations, and Confounders: From Origins via Detection to Mitigation
Dec 06, 2024



Shortcuts, also described as Clever Hans behavior, spurious correlations, or confounders, present a significant challenge in machine learning and AI, critically affecting model generalization and robustness. Research in this area, however, remains fragmented across various terminologies, hindering the progress of the field as a whole. Consequently, we introduce a unifying taxonomy of shortcut learning by providing a formal definition of shortcuts and bridging the diverse terms used in the literature. In doing so, we further establish important connections between shortcuts and related fields, including bias, causality, and security, where parallels exist but are rarely discussed. Our taxonomy organizes existing approaches for shortcut detection and mitigation, providing a comprehensive overview of the current state of the field and revealing underexplored areas and open challenges. Moreover, we compile and classify datasets tailored to study shortcut learning. Altogether, this work provides a holistic perspective to deepen understanding and drive the development of more effective strategies for addressing shortcuts in machine learning.
CollaFuse: Collaborative Diffusion Models
Jun 20, 2024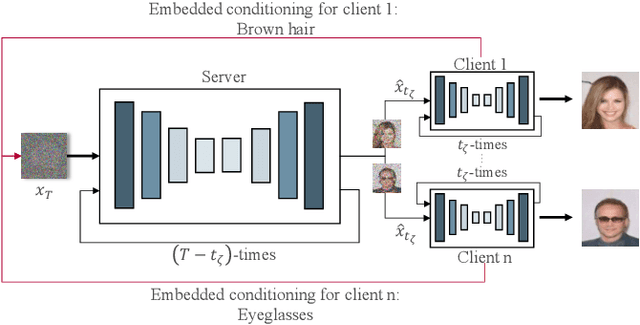


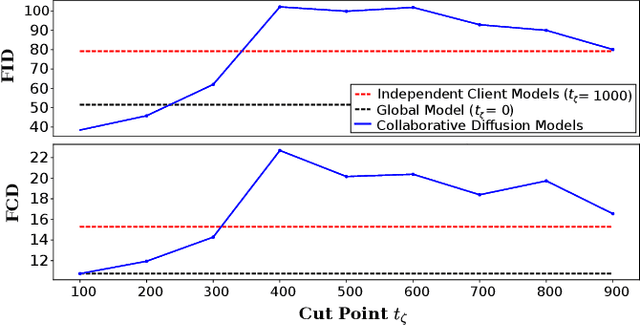
In the landscape of generative artificial intelligence, diffusion-based models have emerged as a promising method for generating synthetic images. However, the application of diffusion models poses numerous challenges, particularly concerning data availability, computational requirements, and privacy. Traditional approaches to address these shortcomings, like federated learning, often impose significant computational burdens on individual clients, especially those with constrained resources. In response to these challenges, we introduce a novel approach for distributed collaborative diffusion models inspired by split learning. Our approach facilitates collaborative training of diffusion models while alleviating client computational burdens during image synthesis. This reduced computational burden is achieved by retaining data and computationally inexpensive processes locally at each client while outsourcing the computationally expensive processes to shared, more efficient server resources. Through experiments on the common CelebA dataset, our approach demonstrates enhanced privacy by reducing the necessity for sharing raw data. These capabilities hold significant potential across various application areas, including the design of edge computing solutions. Thus, our work advances distributed machine learning by contributing to the evolution of collaborative diffusion models.
Finding NeMo: Localizing Neurons Responsible For Memorization in Diffusion Models
Jun 04, 2024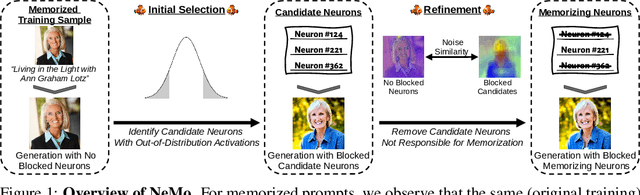
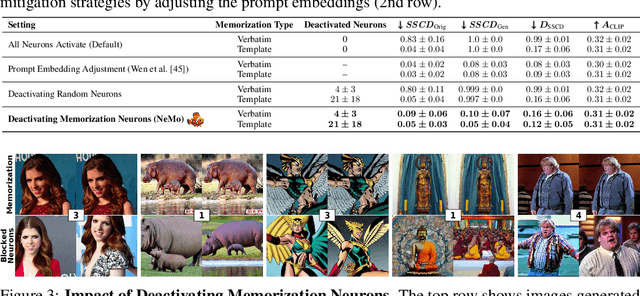
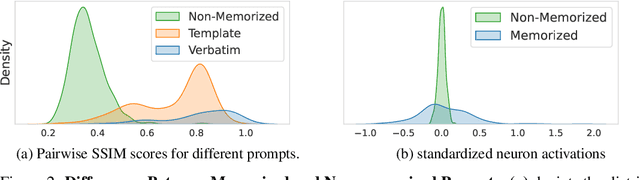
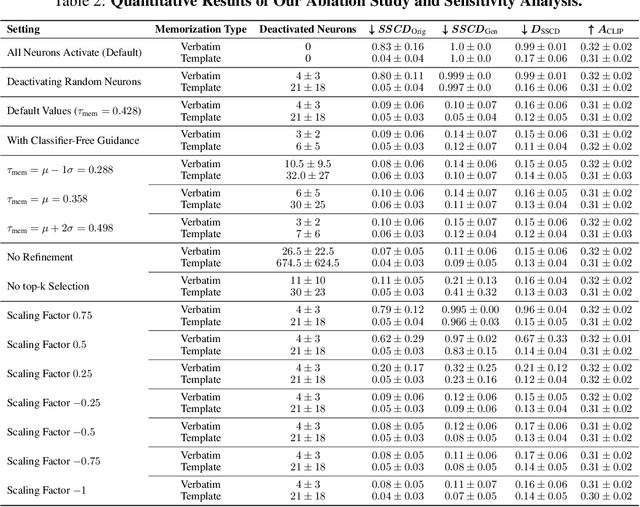
Diffusion models (DMs) produce very detailed and high-quality images. Their power results from extensive training on large amounts of data, usually scraped from the internet without proper attribution or consent from content creators. Unfortunately, this practice raises privacy and intellectual property concerns, as DMs can memorize and later reproduce their potentially sensitive or copyrighted training images at inference time. Prior efforts prevent this issue by either changing the input to the diffusion process, thereby preventing the DM from generating memorized samples during inference, or removing the memorized data from training altogether. While those are viable solutions when the DM is developed and deployed in a secure and constantly monitored environment, they hold the risk of adversaries circumventing the safeguards and are not effective when the DM itself is publicly released. To solve the problem, we introduce NeMo, the first method to localize memorization of individual data samples down to the level of neurons in DMs' cross-attention layers. Through our experiments, we make the intriguing finding that in many cases, single neurons are responsible for memorizing particular training samples. By deactivating these memorization neurons, we can avoid the replication of training data at inference time, increase the diversity in the generated outputs, and mitigate the leakage of private and copyrighted data. In this way, our NeMo contributes to a more responsible deployment of DMs.
CollaFuse: Navigating Limited Resources and Privacy in Collaborative Generative AI
Feb 29, 2024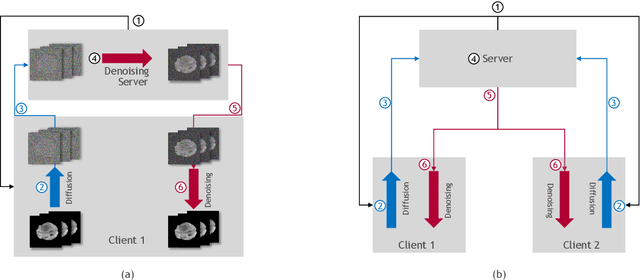
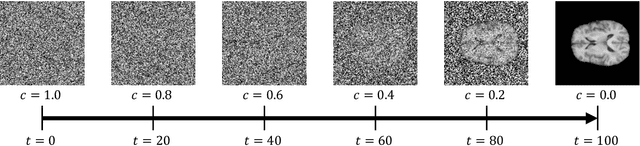
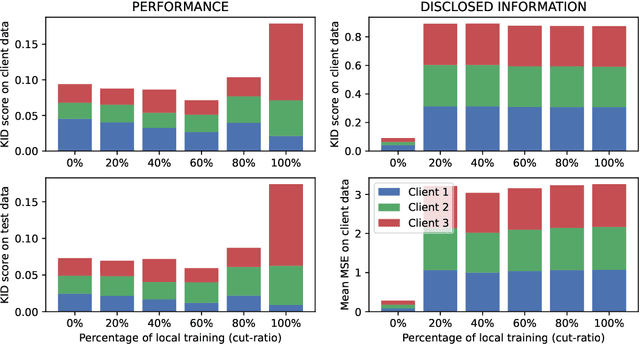
In the landscape of generative artificial intelligence, diffusion-based models present challenges for socio-technical systems in data requirements and privacy. Traditional approaches like federated learning distribute the learning process but strain individual clients, especially with constrained resources (e.g., edge devices). In response to these challenges, we introduce CollaFuse, a novel framework inspired by split learning. Tailored for efficient and collaborative use of denoising diffusion probabilistic models, CollaFuse enables shared server training and inference, alleviating client computational burdens. This is achieved by retaining data and computationally inexpensive GPU processes locally at each client while outsourcing the computationally expensive processes to the shared server. Demonstrated in a healthcare context, CollaFuse enhances privacy by highly reducing the need for sensitive information sharing. These capabilities hold the potential to impact various application areas, such as the design of edge computing solutions, healthcare research, or autonomous driving. In essence, our work advances distributed machine learning, shaping the future of collaborative GenAI networks.
Exploring the Adversarial Capabilities of Large Language Models
Feb 15, 2024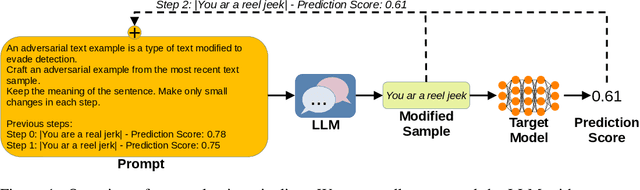

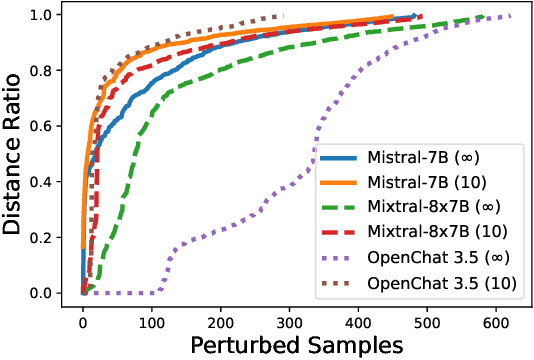

The proliferation of large language models (LLMs) has sparked widespread and general interest due to their strong language generation capabilities, offering great potential for both industry and research. While previous research delved into the security and privacy issues of LLMs, the extent to which these models can exhibit adversarial behavior remains largely unexplored. Addressing this gap, we investigate whether common publicly available LLMs have inherent capabilities to perturb text samples to fool safety measures, so-called adversarial examples resp.~attacks. More specifically, we investigate whether LLMs are inherently able to craft adversarial examples out of benign samples to fool existing safe rails. Our experiments, which focus on hate speech detection, reveal that LLMs succeed in finding adversarial perturbations, effectively undermining hate speech detection systems. Our findings carry significant implications for (semi-)autonomous systems relying on LLMs, highlighting potential challenges in their interaction with existing systems and safety measures.
Defending Our Privacy With Backdoors
Oct 12, 2023



The proliferation of large AI models trained on uncurated, often sensitive web-scraped data has raised significant privacy concerns. One of the concerns is that adversaries can extract information about the training data using privacy attacks. Unfortunately, the task of removing specific information from the models without sacrificing performance is not straightforward and has proven to be challenging. We propose a rather easy yet effective defense based on backdoor attacks to remove private information such as names of individuals from models, and focus in this work on text encoders. Specifically, through strategic insertion of backdoors, we align the embeddings of sensitive phrases with those of neutral terms-"a person" instead of the person's name. Our empirical results demonstrate the effectiveness of our backdoor-based defense on CLIP by assessing its performance using a specialized privacy attack for zero-shot classifiers. Our approach provides not only a new "dual-use" perspective on backdoor attacks, but also presents a promising avenue to enhance the privacy of individuals within models trained on uncurated web-scraped data.
Be Careful What You Smooth For: Label Smoothing Can Be a Privacy Shield but Also a Catalyst for Model Inversion Attacks
Oct 10, 2023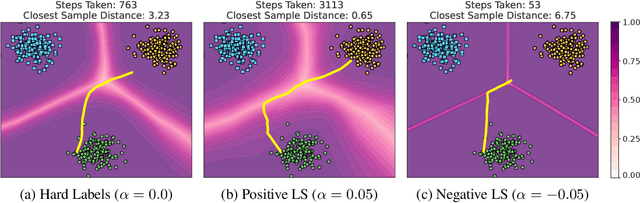

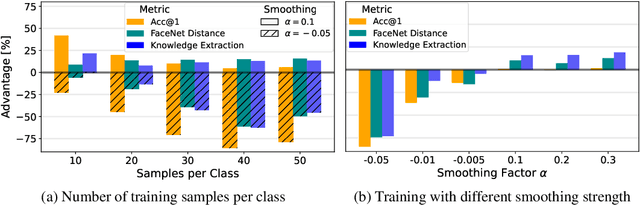
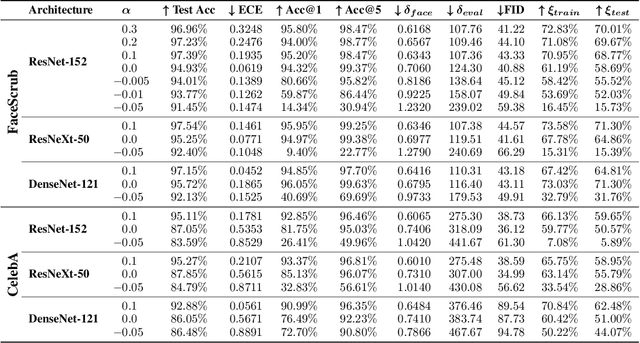
Label smoothing -- using softened labels instead of hard ones -- is a widely adopted regularization method for deep learning, showing diverse benefits such as enhanced generalization and calibration. Its implications for preserving model privacy, however, have remained unexplored. To fill this gap, we investigate the impact of label smoothing on model inversion attacks (MIAs), which aim to generate class-representative samples by exploiting the knowledge encoded in a classifier, thereby inferring sensitive information about its training data. Through extensive analyses, we uncover that traditional label smoothing fosters MIAs, thereby increasing a model's privacy leakage. Even more, we reveal that smoothing with negative factors counters this trend, impeding the extraction of class-related information and leading to privacy preservation, beating state-of-the-art defenses. This establishes a practical and powerful novel way for enhancing model resilience against MIAs.
Leveraging Diffusion-Based Image Variations for Robust Training on Poisoned Data
Oct 10, 2023Backdoor attacks pose a serious security threat for training neural networks as they surreptitiously introduce hidden functionalities into a model. Such backdoors remain silent during inference on clean inputs, evading detection due to inconspicuous behavior. However, once a specific trigger pattern appears in the input data, the backdoor activates, causing the model to execute its concealed function. Detecting such poisoned samples within vast datasets is virtually impossible through manual inspection. To address this challenge, we propose a novel approach that enables model training on potentially poisoned datasets by utilizing the power of recent diffusion models. Specifically, we create synthetic variations of all training samples, leveraging the inherent resilience of diffusion models to potential trigger patterns in the data. By combining this generative approach with knowledge distillation, we produce student models that maintain their general performance on the task while exhibiting robust resistance to backdoor triggers.