 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Causal Machine Learning into Clinical Decision Support Systems: Insights from Literature and Practice
Mar 25, 2026Current clinical decision support systems (CDSSs) typically base their predictions on correlation, not causation. In recent years, causal machine learning (ML) has emerged as a promising way to improve decision-making with CDSSs by offering interpretable, treatment-specific reasoning. However, existing research often emphasizes model development rather than designing clinician-facing interfaces. To address this gap, we investigated how CDSSs based on causal ML should be designed to effectively support collaborative clinical decision-making. Using a design science research methodology, we conducted a structured literature review and interviewed experienced physicians. From these, we derived eight empirically grounded design requirements, developed seven design principles, and proposed nine practical design features. Our results establish guidance for designing CDSSs that deliver causal insights, integrate seamlessly into clinical workflows, and support trust, usability, and human-AI collaboration. We also reveal tensions around automation, responsibility, and regulation, highlighting the need for an adaptive certification process for ML-based medical products.
A Multivocal Literature Review on Privacy and Fairness in Federated Learning
Aug 16, 2024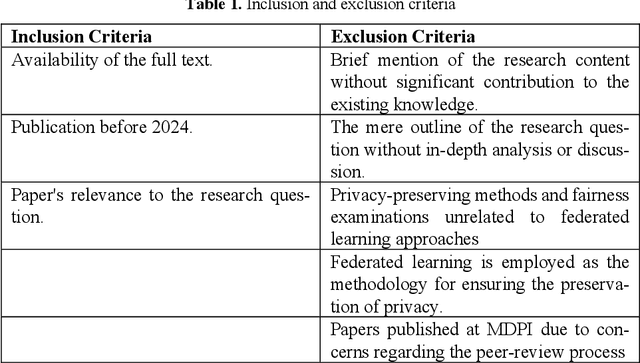
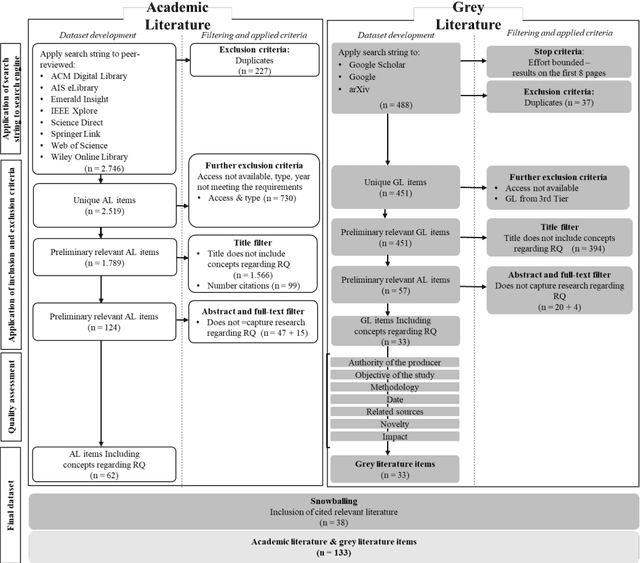
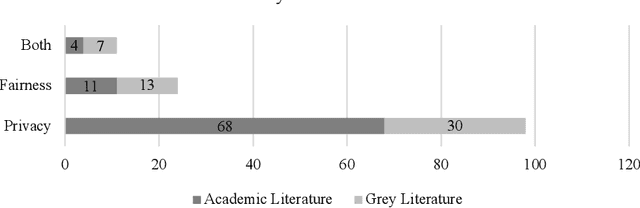
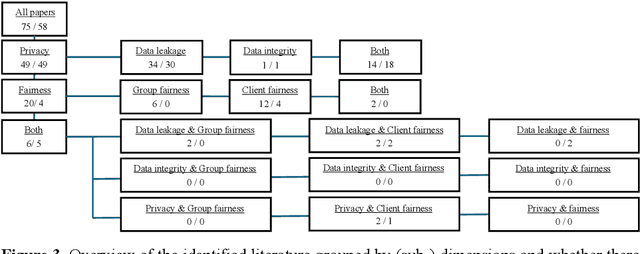
Federated Learning presents a way to revolutionize AI applications by eliminating the necessity for data sharing. Yet, research has shown that information can still be extracted during training, making additional privacy-preserving measures such as differential privacy imperative. To implement real-world federated learning applications, fairness, ranging from a fair distribution of performance to non-discriminative behaviour, must be considered. Particularly in high-risk applications (e.g. healthcare), avoiding the repetition of past discriminatory errors is paramount. As recent research has demonstrated an inherent tension between privacy and fairness, we conduct a multivocal literature review to examine the current methods to integrate privacy and fairness in federated learning. Our analyses illustrate that the relationship between privacy and fairness has been neglected, posing a critical risk for real-world applications. We highlight the need to explore the relationship between privacy, fairness, and performance, advocating for the creation of integrated federated learning frameworks.
CollaFuse: Collaborative Diffusion Models
Jun 20, 2024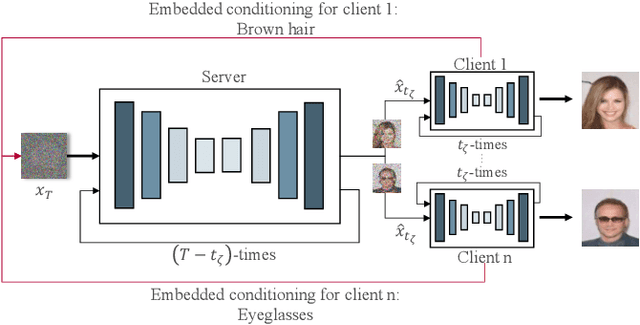


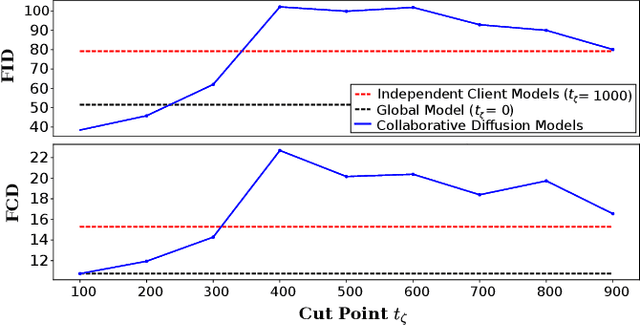
In the landscape of generative artificial intelligence, diffusion-based models have emerged as a promising method for generating synthetic images. However, the application of diffusion models poses numerous challenges, particularly concerning data availability, computational requirements, and privacy. Traditional approaches to address these shortcomings, like federated learning, often impose significant computational burdens on individual clients, especially those with constrained resources. In response to these challenges, we introduce a novel approach for distributed collaborative diffusion models inspired by split learning. Our approach facilitates collaborative training of diffusion models while alleviating client computational burdens during image synthesis. This reduced computational burden is achieved by retaining data and computationally inexpensive processes locally at each client while outsourcing the computationally expensive processes to shared, more efficient server resources. Through experiments on the common CelebA dataset, our approach demonstrates enhanced privacy by reducing the necessity for sharing raw data. These capabilities hold significant potential across various application areas, including the design of edge computing solutions. Thus, our work advances distributed machine learning by contributing to the evolution of collaborative diffusion models.
Implications of the AI Act for Non-Discrimination Law and Algorithmic Fairness
Mar 29, 2024

The topic of fairness in AI, as debated in the FATE (Fairness, Accountability, Transparency, and Ethics in AI) communities, has sparked meaningful discussions in the past years. However, from a legal perspective, particularly from European Union law, many open questions remain. Whereas algorithmic fairness aims to mitigate structural inequalities at the design level, European non-discrimination law is tailored to individual cases of discrimination after an AI model has been deployed. The AI Act might present a tremendous step towards bridging these two concepts by shifting non-discrimination responsibilities into the design stage of AI models. Based on an integrative reading of the AI Act, we comment on legal as well as technical enforcement problems and propose practical implications on bias detection and bias correction in order to specify and comply with specific technical requirements.
CollaFuse: Navigating Limited Resources and Privacy in Collaborative Generative AI
Feb 29, 2024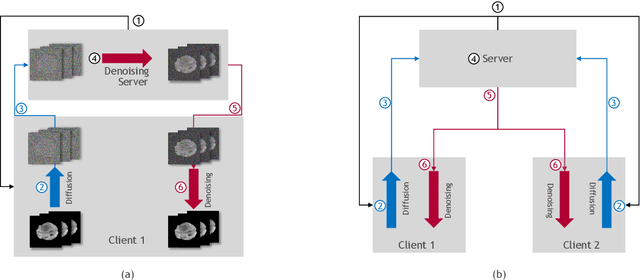
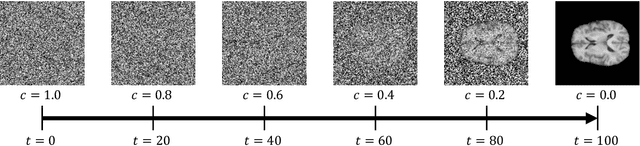
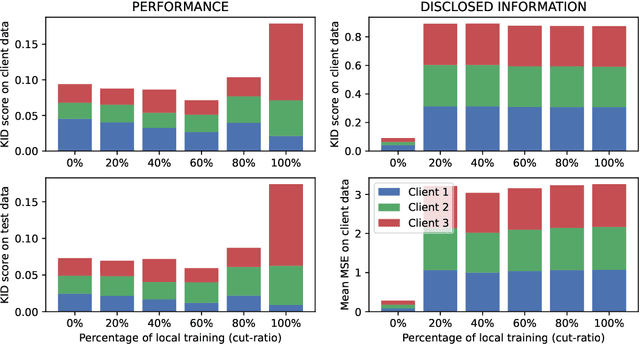
In the landscape of generative artificial intelligence, diffusion-based models present challenges for socio-technical systems in data requirements and privacy. Traditional approaches like federated learning distribute the learning process but strain individual clients, especially with constrained resources (e.g., edge devices). In response to these challenges, we introduce CollaFuse, a novel framework inspired by split learning. Tailored for efficient and collaborative use of denoising diffusion probabilistic models, CollaFuse enables shared server training and inference, alleviating client computational burdens. This is achieved by retaining data and computationally inexpensive GPU processes locally at each client while outsourcing the computationally expensive processes to the shared server. Demonstrated in a healthcare context, CollaFuse enhances privacy by highly reducing the need for sensitive information sharing. These capabilities hold the potential to impact various application areas, such as the design of edge computing solutions, healthcare research, or autonomous driving. In essence, our work advances distributed machine learning, shaping the future of collaborative GenAI networks.
A review of systematic selection of clustering algorithms and their evaluation
Jun 24, 2021
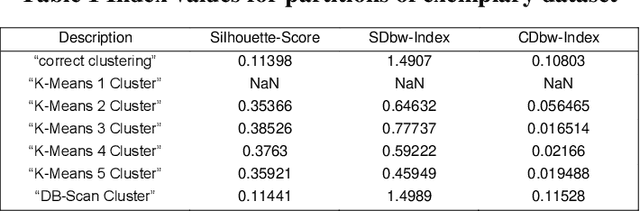

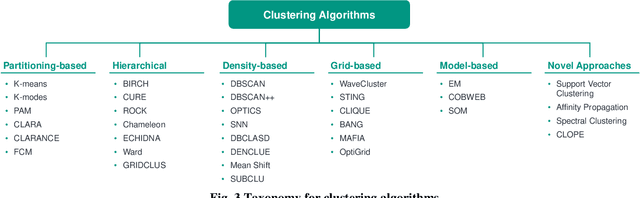
Data analysis plays an indispensable role for value creation in industry. Cluster analysis in this context is able to explore given datasets with little or no prior knowledge and to identify unknown patterns. As (big) data complexity increases in the dimensions volume, variety, and velocity, this becomes even more important. Many tools for cluster analysis have been developed from early on and the variety of different clustering algorithms is huge. As the selection of the right clustering procedure is crucial to the results of the data analysis, users are in need for support on their journey of extracting knowledge from raw data. Thus, the objective of this paper lies in the identification of a systematic selection logic for clustering algorithms and corresponding validation concepts. The goal is to enable potential users to choose an algorithm that fits best to their needs and the properties of their underlying data clustering problem. Moreover, users are supported in selecting the right validation concepts to make sense of the clustering results. Based on a comprehensive literature review, this paper provides assessment criteria for clustering method evaluation and validation concept selection. The criteria are applied to several common algorithms and the selection process of an algorithm is supported by the introduction of pseudocode-based routines that consider the underlying data structure.