 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalability of Reinforcement Learning Methods for Dispatching in Semiconductor Frontend Fabs: A Comparison of Open-Source Models with Real Industry Datasets
May 16, 2025Benchmark datasets are crucial for evaluating approaches to scheduling or dispatching in the semiconductor industry during the development and deployment phases. However, commonly used benchmark datasets like the Minifab or SMT2020 lack the complex details and constraints found in real-world scenarios. To mitigate this shortcoming, we compare open-source simulation models with a real industry dataset to evaluate how optimization methods scale with different levels of complexity. Specifically, we focus on Reinforcement Learning methods, performing optimization based on policy-gradient and Evolution Strategies. Our research provides insights into the effectiveness of these optimization methods and their applicability to realistic semiconductor frontend fab simulations. We show that our proposed Evolution Strategies-based method scales much better than a comparable policy-gradient-based approach. Moreover, we identify the selection and combination of relevant bottleneck tools to control by the agent as crucial for an efficient optimization. For the generalization across different loading scenarios and stochastic tool failure patterns, we achieve advantages when utilizing a diverse training dataset. While the overall approach is computationally expensive, it manages to scale well with the number of CPU cores used for training. For the real industry dataset, we achieve an improvement of up to 4% regarding tardiness and up to 1% regarding throughput. For the less complex open-source models Minifab and SMT2020, we observe double-digit percentage improvement in tardiness and single digit percentage improvement in throughput by use of Evolution Strategies.
A review of systematic selection of clustering algorithms and their evaluation
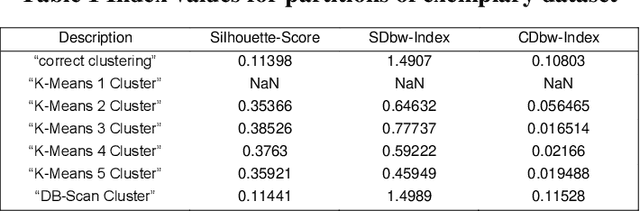
Jun 24, 2021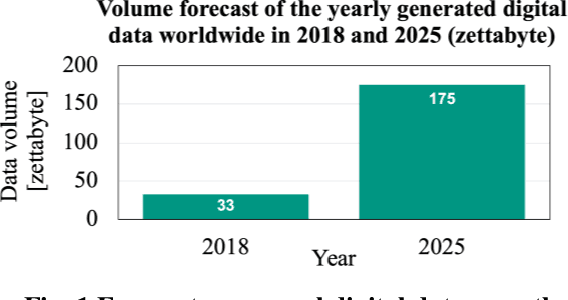

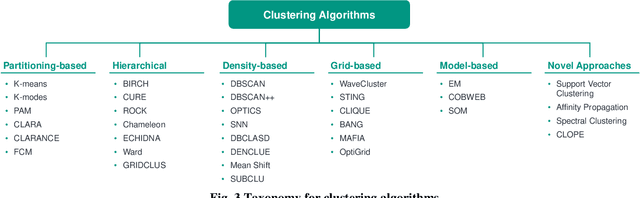
Data analysis plays an indispensable role for value creation in industry. Cluster analysis in this context is able to explore given datasets with little or no prior knowledge and to identify unknown patterns. As (big) data complexity increases in the dimensions volume, variety, and velocity, this becomes even more important. Many tools for cluster analysis have been developed from early on and the variety of different clustering algorithms is huge. As the selection of the right clustering procedure is crucial to the results of the data analysis, users are in need for support on their journey of extracting knowledge from raw data. Thus, the objective of this paper lies in the identification of a systematic selection logic for clustering algorithms and corresponding validation concepts. The goal is to enable potential users to choose an algorithm that fits best to their needs and the properties of their underlying data clustering problem. Moreover, users are supported in selecting the right validation concepts to make sense of the clustering results. Based on a comprehensive literature review, this paper provides assessment criteria for clustering method evaluation and validation concept selection. The criteria are applied to several common algorithms and the selection process of an algorithm is supported by the introduction of pseudocode-based routines that consider the underlying data structure.