 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuAnTS: Question Answering on Time Series
Nov 07, 2025Text offers intuitive access to information. This can, in particular, complement the density of numerical time series, thereby allowing improved interactions with time series models to enhance accessibility and decision-making. While the creation of question-answering datasets and models has recently seen remarkable growth, most research focuses on question answering (QA) on vision and text, with time series receiving minute attention. To bridge this gap, we propose a challenging novel time series QA (TSQA) dataset, QuAnTS, for Question Answering on Time Series data. Specifically, we pose a wide variety of questions and answers about human motion in the form of tracked skeleton trajectories. We verify that the large-scale QuAnTS dataset is well-formed and comprehensive through extensive experiments. Thoroughly evaluating existing and newly proposed baselines then lays the groundwork for a deeper exploration of TSQA using QuAnTS. Additionally, we provide human performances as a key reference for gauging the practical usability of such models. We hope to encourage future research on interacting with time series models through text, enabling better decision-making and more transparent systems.
EmoNet-Voice: A Fine-Grained, Expert-Verified Benchmark for Speech Emotion Detection
Jun 11, 2025The advancement of text-to-speech and audio generation models necessitates robust benchmarks for evaluating the emotional understanding capabilities of AI systems. Current speech emotion recognition (SER) datasets often exhibit limitations in emotional granularity, privacy concerns, or reliance on acted portrayals. This paper introduces EmoNet-Voice, a new resource for speech emotion detection, which includes EmoNet-Voice Big, a large-scale pre-training dataset (featuring over 4,500 hours of speech across 11 voices, 40 emotions, and 4 languages), and EmoNet-Voice Bench, a novel benchmark dataset with human expert annotations. EmoNet-Voice is designed to evaluate SER models on a fine-grained spectrum of 40 emotion categories with different levels of intensities. Leveraging state-of-the-art voice generation, we curated synthetic audio snippets simulating actors portraying scenes designed to evoke specific emotions. Crucially, we conducted rigorous validation by psychology experts who assigned perceived intensity labels. This synthetic, privacy-preserving approach allows for the inclusion of sensitive emotional states often absent in existing datasets. Lastly, we introduce Empathic Insight Voice models that set a new standard in speech emotion recognition with high agreement with human experts. Our evaluations across the current model landscape exhibit valuable findings, such as high-arousal emotions like anger being much easier to detect than low-arousal states like concentration.
Judging Quality Across Languages: A Multilingual Approach to Pretraining Data Filtering with Language Models
May 28, 2025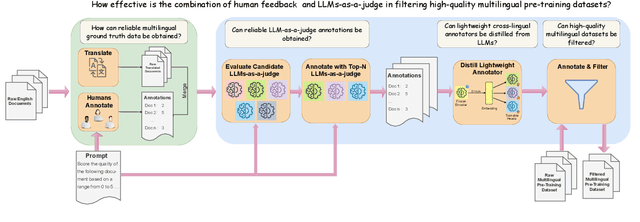
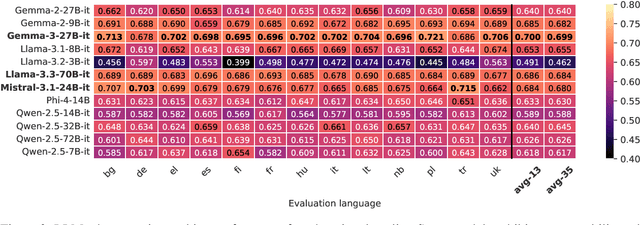

High-quality multilingual training data is essential for effectively pretraining large language models (LLMs). Yet, the availability of suitable open-source multilingual datasets remains limited. Existing state-of-the-art datasets mostly rely on heuristic filtering methods, restricting both their cross-lingual transferability and scalability. Here, we introduce JQL, a systematic approach that efficiently curates diverse and high-quality multilingual data at scale while significantly reducing computational demands. JQL distills LLMs' annotation capabilities into lightweight annotators based on pretrained multilingual embeddings. These models exhibit robust multilingual and cross-lingual performance, even for languages and scripts unseen during training. Evaluated empirically across 35 languages, the resulting annotation pipeline substantially outperforms current heuristic filtering methods like Fineweb2. JQL notably enhances downstream model training quality and increases data retention rates. Our research provides practical insights and valuable resources for multilingual data curation, raising the standards of multilingual dataset development.
EmoNet-Face: An Expert-Annotated Benchmark for Synthetic Emotion Recognition
May 26, 2025Effective human-AI interaction relies on AI's ability to accurately perceive and interpret human emotions. Current benchmarks for vision and vision-language models are severely limited, offering a narrow emotional spectrum that overlooks nuanced states (e.g., bitterness, intoxication) and fails to distinguish subtle differences between related feelings (e.g., shame vs. embarrassment). Existing datasets also often use uncontrolled imagery with occluded faces and lack demographic diversity, risking significant bias. To address these critical gaps, we introduce EmoNet Face, a comprehensive benchmark suite. EmoNet Face features: (1) A novel 40-category emotion taxonomy, meticulously derived from foundational research to capture finer details of human emotional experiences. (2) Three large-scale, AI-generated datasets (EmoNet HQ, Binary, and Big) with explicit, full-face expressions and controlled demographic balance across ethnicity, age, and gender. (3) Rigorous, multi-expert annotations for training and high-fidelity evaluation. (4) We build Empathic Insight Face, a model achieving human-expert-level performance on our benchmark. The publicly released EmoNet Face suite - taxonomy, datasets, and model - provides a robust foundation for developing and evaluating AI systems with a deeper understanding of human emotions.
Navigating Shortcuts, Spurious Correlations, and Confounders: From Origins via Detection to Mitigation
Dec 06, 2024



Shortcuts, also described as Clever Hans behavior, spurious correlations, or confounders, present a significant challenge in machine learning and AI, critically affecting model generalization and robustness. Research in this area, however, remains fragmented across various terminologies, hindering the progress of the field as a whole. Consequently, we introduce a unifying taxonomy of shortcut learning by providing a formal definition of shortcuts and bridging the diverse terms used in the literature. In doing so, we further establish important connections between shortcuts and related fields, including bias, causality, and security, where parallels exist but are rarely discussed. Our taxonomy organizes existing approaches for shortcut detection and mitigation, providing a comprehensive overview of the current state of the field and revealing underexplored areas and open challenges. Moreover, we compile and classify datasets tailored to study shortcut learning. Altogether, this work provides a holistic perspective to deepen understanding and drive the development of more effective strategies for addressing shortcuts in machine learning.
xLSTM-Mixer: Multivariate Time Series Forecasting by Mixing via Scalar Memories
Oct 23, 2024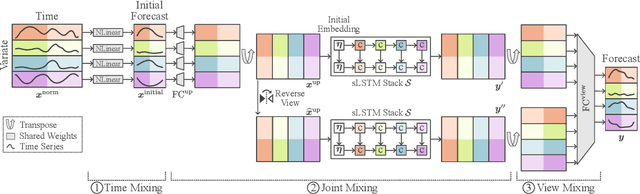

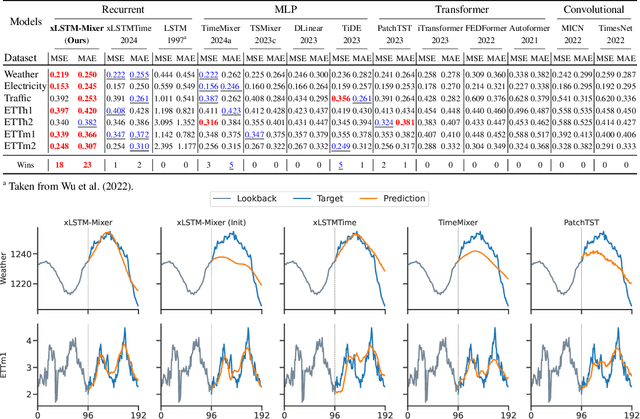
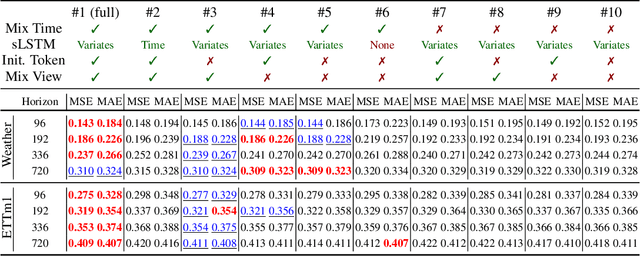
Time series data is prevalent across numerous fields, necessitating the development of robust and accurate forecasting models. Capturing patterns both within and between temporal and multivariate components is crucial for reliable predictions. We introduce xLSTM-Mixer, a model designed to effectively integrate temporal sequences, joint time-variate information, and multiple perspectives for robust forecasting. Our approach begins with a linear forecast shared across variates, which is then refined by xLSTM blocks. These blocks serve as key elements for modeling the complex dynamics of challenging time series data. xLSTM-Mixer ultimately reconciles two distinct views to produce the final forecast. Our extensive evaluations demonstrate xLSTM-Mixer's superior long-term forecasting performance compared to recent state-of-the-art methods. A thorough model analysis provides further insights into its key components and confirms its robustness and effectiveness. This work contributes to the resurgence of recurrent models in time series forecasting.
Right on Time: Revising Time Series Models by Constraining their Explanations
Feb 28, 2024



The reliability of deep time series models is often compromised by their tendency to rely on confounding factors, which may lead to misleading results. Our newly recorded, naturally confounded dataset named P2S from a real mechanical production line emphasizes this. To tackle the challenging problem of mitigating confounders in time series data, we introduce Right on Time (RioT). Our method enables interactions with model explanations across both the time and frequency domain. Feedback on explanations in both domains is then used to constrain the model, steering it away from the annotated confounding factors. The dual-domain interaction strategy is crucial for effectively addressing confounders in time series datasets. We empirically demonstrate that RioT can effectively guide models away from the wrong reasons in P2S as well as popular time series classification and forecasting datasets.
United We Pretrain, Divided We Fail! Representation Learning for Time Series by Pretraining on 75 Datasets at Once
Feb 23, 2024In natural language processing and vision, pretraining is utilized to learn effective representations. Unfortunately, the success of pretraining does not easily carry over to time series due to potential mismatch between sources and target. Actually, common belief is that multi-dataset pretraining does not work for time series! Au contraire, we introduce a new self-supervised contrastive pretraining approach to learn one encoding from many unlabeled and diverse time series datasets, so that the single learned representation can then be reused in several target domains for, say, classification. Specifically, we propose the XD-MixUp interpolation method and the Soft Interpolation Contextual Contrasting (SICC) loss. Empirically, this outperforms both supervised training and other self-supervised pretraining methods when finetuning on low-data regimes. This disproves the common belief: We can actually learn from multiple time series datasets, even from 75 at once.