 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoNet-Voice: A Fine-Grained, Expert-Verified Benchmark for Speech Emotion Detection
Jun 11, 2025The advancement of text-to-speech and audio generation models necessitates robust benchmarks for evaluating the emotional understanding capabilities of AI systems. Current speech emotion recognition (SER) datasets often exhibit limitations in emotional granularity, privacy concerns, or reliance on acted portrayals. This paper introduces EmoNet-Voice, a new resource for speech emotion detection, which includes EmoNet-Voice Big, a large-scale pre-training dataset (featuring over 4,500 hours of speech across 11 voices, 40 emotions, and 4 languages), and EmoNet-Voice Bench, a novel benchmark dataset with human expert annotations. EmoNet-Voice is designed to evaluate SER models on a fine-grained spectrum of 40 emotion categories with different levels of intensities. Leveraging state-of-the-art voice generation, we curated synthetic audio snippets simulating actors portraying scenes designed to evoke specific emotions. Crucially, we conducted rigorous validation by psychology experts who assigned perceived intensity labels. This synthetic, privacy-preserving approach allows for the inclusion of sensitive emotional states often absent in existing datasets. Lastly, we introduce Empathic Insight Voice models that set a new standard in speech emotion recognition with high agreement with human experts. Our evaluations across the current model landscape exhibit valuable findings, such as high-arousal emotions like anger being much easier to detect than low-arousal states like concentration.
EmoNet-Face: An Expert-Annotated Benchmark for Synthetic Emotion Recognition
May 26, 2025Effective human-AI interaction relies on AI's ability to accurately perceive and interpret human emotions. Current benchmarks for vision and vision-language models are severely limited, offering a narrow emotional spectrum that overlooks nuanced states (e.g., bitterness, intoxication) and fails to distinguish subtle differences between related feelings (e.g., shame vs. embarrassment). Existing datasets also often use uncontrolled imagery with occluded faces and lack demographic diversity, risking significant bias. To address these critical gaps, we introduce EmoNet Face, a comprehensive benchmark suite. EmoNet Face features: (1) A novel 40-category emotion taxonomy, meticulously derived from foundational research to capture finer details of human emotional experiences. (2) Three large-scale, AI-generated datasets (EmoNet HQ, Binary, and Big) with explicit, full-face expressions and controlled demographic balance across ethnicity, age, and gender. (3) Rigorous, multi-expert annotations for training and high-fidelity evaluation. (4) We build Empathic Insight Face, a model achieving human-expert-level performance on our benchmark. The publicly released EmoNet Face suite - taxonomy, datasets, and model - provides a robust foundation for developing and evaluating AI systems with a deeper understanding of human emotions.
Project Alexandria: Towards Freeing Scientific Knowledge from Copyright Burdens via LLMs
Feb 26, 2025

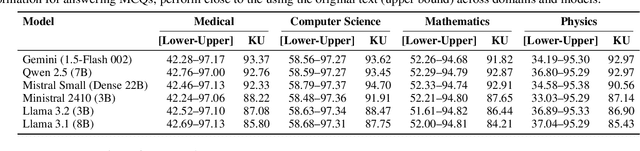

Paywalls, licenses and copyright rules often restrict the broad dissemination and reuse of scientific knowledge. We take the position that it is both legally and technically feasible to extract the scientific knowledge in scholarly texts. Current methods, like text embeddings, fail to reliably preserve factual content, and simple paraphrasing may not be legally sound. We urge the community to adopt a new idea: convert scholarly documents into Knowledge Units using LLMs. These units use structured data capturing entities, attributes and relationships without stylistic content. We provide evidence that Knowledge Units: (1) form a legally defensible framework for sharing knowledge from copyrighted research texts, based on legal analyses of German copyright law and U.S. Fair Use doctrine, and (2) preserve most (~95%) factual knowledge from original text, measured by MCQ performance on facts from the original copyrighted text across four research domains. Freeing scientific knowledge from copyright promises transformative benefits for scientific research and education by allowing language models to reuse important facts from copyrighted text. To support this, we share open-source tools for converting research documents into Knowledge Units. Overall, our work posits the feasibility of democratizing access to scientific knowledge while respecting copyright.
LAION-5B: An open large-scale dataset for training next generation image-text models
Oct 16, 2022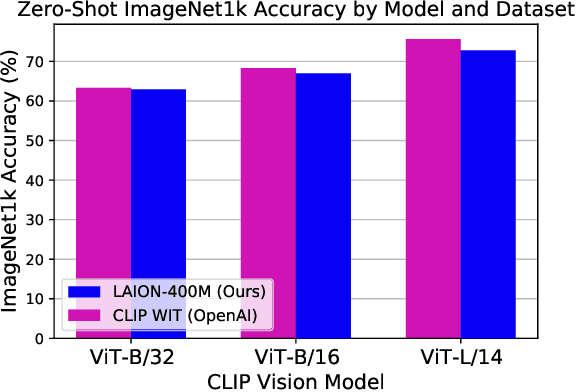
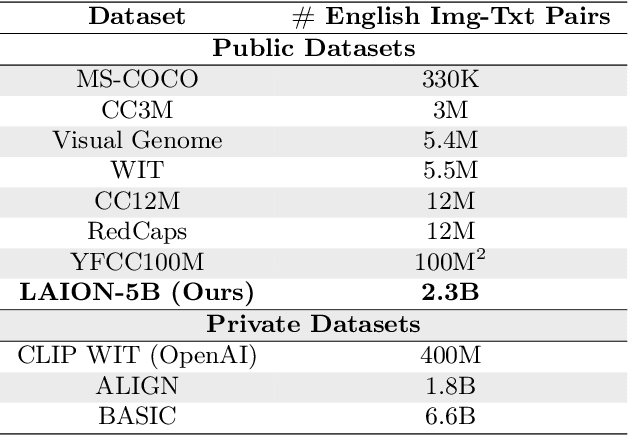
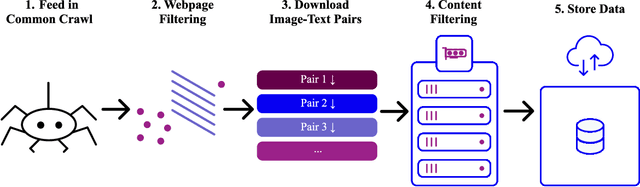
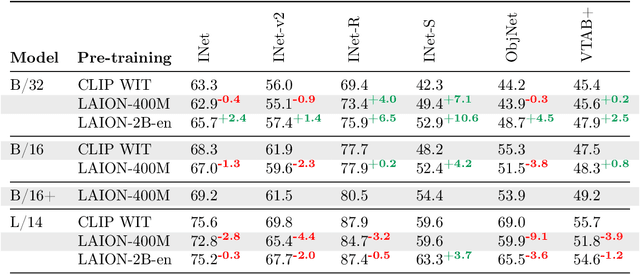
Groundbreaking language-vision architectures like CLIP and DALL-E proved the utility of training on large amounts of noisy image-text data, without relying on expensive accurate labels used in standard vision unimodal supervised learning. The resulting models showed capabilities of strong text-guided image generation and transfer to downstream tasks, while performing remarkably at zero-shot classification with noteworthy out-of-distribution robustness. Since then, large-scale language-vision models like ALIGN, BASIC, GLIDE, Flamingo and Imagen made further improvements. Studying the training and capabilities of such models requires datasets containing billions of image-text pairs. Until now, no datasets of this size have been made openly available for the broader research community. To address this problem and democratize research on large-scale multi-modal models, we present LAION-5B - a dataset consisting of 5.85 billion CLIP-filtered image-text pairs, of which 2.32B contain English language. We show successful replication and fine-tuning of foundational models like CLIP, GLIDE and Stable Diffusion using the dataset, and discuss further experiments enabled with an openly available dataset of this scale. Additionally we provide several nearest neighbor indices, an improved web-interface for dataset exploration and subset generation, and detection scores for watermark, NSFW, and toxic content detection. Announcement page https://laion.ai/laion-5b-a-new-era-of-open-large-scale-multi-modal-datasets/
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
Nov 03, 2021

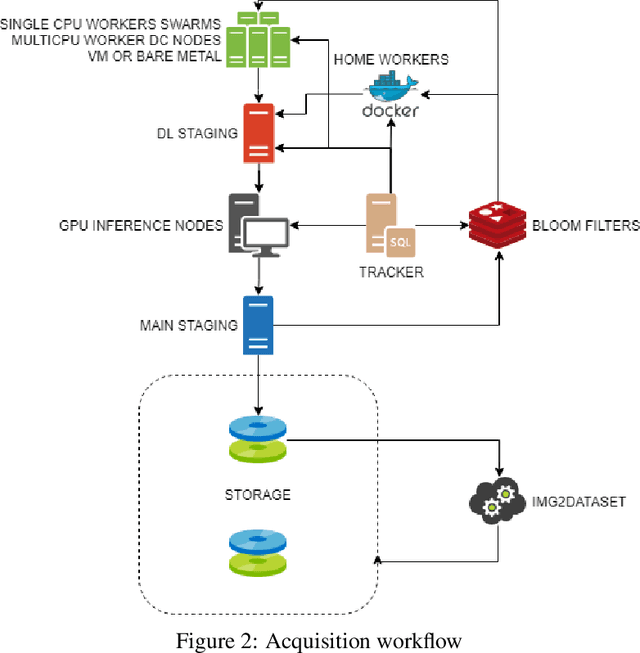
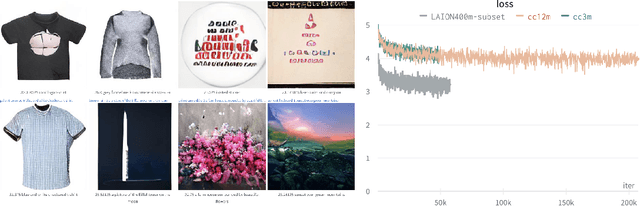
Multi-modal language-vision models trained on hundreds of millions of image-text pairs (e.g. CLIP, DALL-E) gained a recent surge, showing remarkable capability to perform zero- or few-shot learning and transfer even in absence of per-sample labels on target image data. Despite this trend, to date there has been no publicly available datasets of sufficient scale for training such models from scratch. To address this issue, in a community effort we build and release for public LAION-400M, a dataset with CLIP-filtered 400 million image-text pairs, their CLIP embeddings and kNN indices that allow efficient similarity search.