 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMediSyn: Text-Guided Diffusion Models for Broad Medical 2D and 3D Image Synthesis
May 16, 2024Diffusion models have recently gained significant traction due to their ability to generate high-fidelity and diverse images and videos conditioned on text prompts. In medicine, this application promises to address the critical challenge of data scarcity, a consequence of barriers in data sharing, stringent patient privacy regulations, and disparities in patient population and demographics. By generating realistic and varying medical 2D and 3D images, these models offer a rich, privacy-respecting resource for algorithmic training and research. To this end, we introduce MediSyn, a pair of instruction-tuned text-guided latent diffusion models with the ability to generate high-fidelity and diverse medical 2D and 3D images across specialties and modalities. Through established metrics, we show significant improvement in broad medical image and video synthesis guided by text prompts.
Reproducible scaling laws for contrastive language-image learning
Dec 14, 2022Scaling up neural networks has led to remarkable performance across a wide range of tasks. Moreover, performance often follows reliable scaling laws as a function of training set size, model size, and compute, which offers valuable guidance as large-scale experiments are becoming increasingly expensive. However, previous work on scaling laws has primarily used private data \& models or focused on uni-modal language or vision learning. To address these limitations, we investigate scaling laws for contrastive language-image pre-training (CLIP) with the public LAION dataset and the open-source OpenCLIP repository. Our large-scale experiments involve models trained on up to two billion image-text pairs and identify power law scaling for multiple downstream tasks including zero-shot classification, retrieval, linear probing, and end-to-end fine-tuning. We find that the training distribution plays a key role in scaling laws as the OpenAI and OpenCLIP models exhibit different scaling behavior despite identical model architectures and similar training recipes. We open-source our evaluation workflow and all models, including the largest public CLIP models, to ensure reproducibility and make scaling laws research more accessible. Source code and instructions to reproduce this study will be available at https://github.com/LAION-AI/scaling-laws-openclip
LAION-5B: An open large-scale dataset for training next generation image-text models
Oct 16, 2022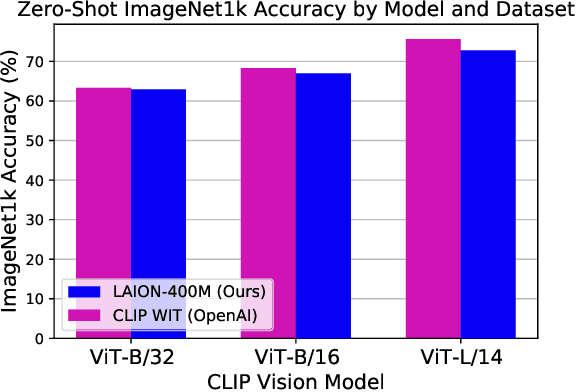
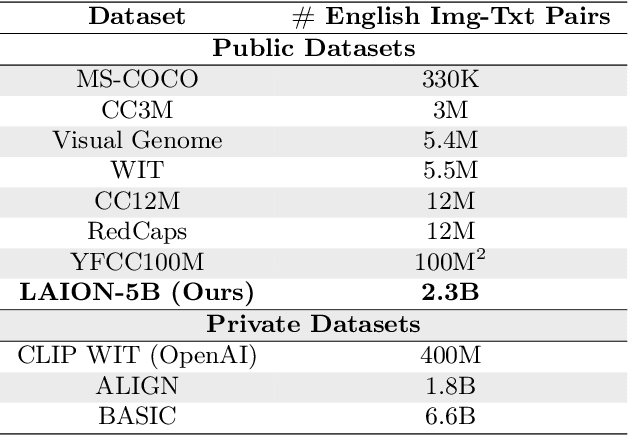
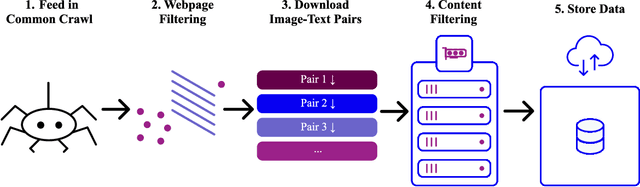
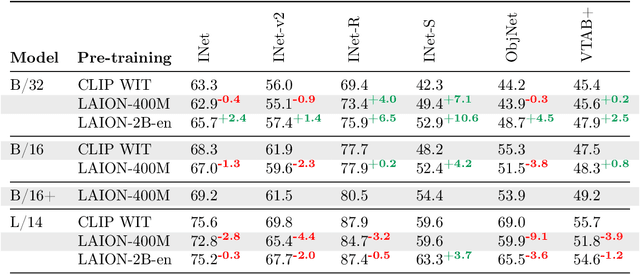
Groundbreaking language-vision architectures like CLIP and DALL-E proved the utility of training on large amounts of noisy image-text data, without relying on expensive accurate labels used in standard vision unimodal supervised learning. The resulting models showed capabilities of strong text-guided image generation and transfer to downstream tasks, while performing remarkably at zero-shot classification with noteworthy out-of-distribution robustness. Since then, large-scale language-vision models like ALIGN, BASIC, GLIDE, Flamingo and Imagen made further improvements. Studying the training and capabilities of such models requires datasets containing billions of image-text pairs. Until now, no datasets of this size have been made openly available for the broader research community. To address this problem and democratize research on large-scale multi-modal models, we present LAION-5B - a dataset consisting of 5.85 billion CLIP-filtered image-text pairs, of which 2.32B contain English language. We show successful replication and fine-tuning of foundational models like CLIP, GLIDE and Stable Diffusion using the dataset, and discuss further experiments enabled with an openly available dataset of this scale. Additionally we provide several nearest neighbor indices, an improved web-interface for dataset exploration and subset generation, and detection scores for watermark, NSFW, and toxic content detection. Announcement page https://laion.ai/laion-5b-a-new-era-of-open-large-scale-multi-modal-datasets/
ResNet strikes back: An improved training procedure in timm
Oct 01, 2021
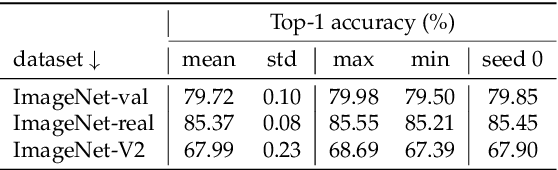


The influential Residual Networks designed by He et al. remain the gold-standard architecture in numerous scientific publications. They typically serve as the default architecture in studies, or as baselines when new architectures are proposed. Yet there has been significant progress on best practices for training neural networks since the inception of the ResNet architecture in 2015. Novel optimization & data-augmentation have increased the effectiveness of the training recipes. In this paper, we re-evaluate the performance of the vanilla ResNet-50 when trained with a procedure that integrates such advances. We share competitive training settings and pre-trained models in the timm open-source library, with the hope that they will serve as better baselines for future work. For instance, with our more demanding training setting, a vanilla ResNet-50 reaches 80.4% top-1 accuracy at resolution 224x224 on ImageNet-val without extra data or distillation. We also report the performance achieved with popular models with our training procedure.
How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers
Jun 18, 2021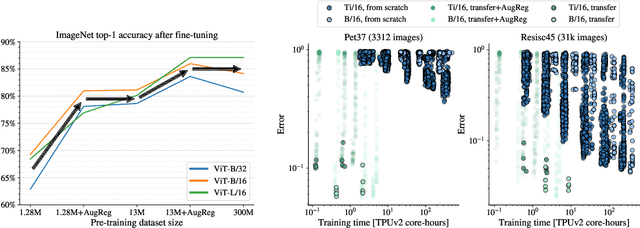
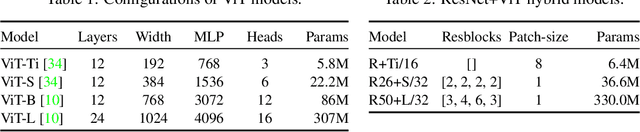
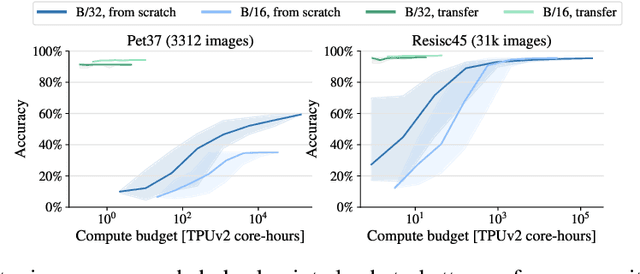
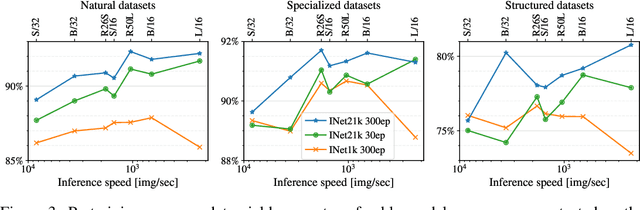
Vision Transformers (ViT) have been shown to attain highly competitive performance for a wide range of vision applications, such as image classification, object detection and semantic image segmentation. In comparison to convolutional neural networks, the Vision Transformer's weaker inductive bias is generally found to cause an increased reliance on model regularization or data augmentation (``AugReg'' for short) when training on smaller training datasets. We conduct a systematic empirical study in order to better understand the interplay between the amount of training data, AugReg, model size and compute budget. As one result of this study we find that the combination of increased compute and AugReg can yield models with the same performance as models trained on an order of magnitude more training data: we train ViT models of various sizes on the public ImageNet-21k dataset which either match or outperform their counterparts trained on the larger, but not publicly available JFT-300M dataset.