 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurGen: Text-Guided Diffusion Model for Surgical Video Generation
Aug 26, 2024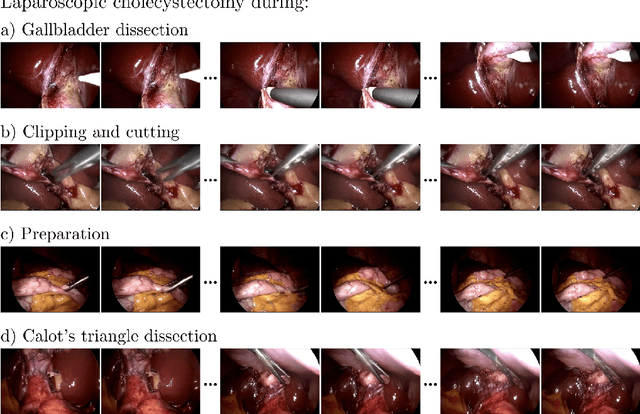
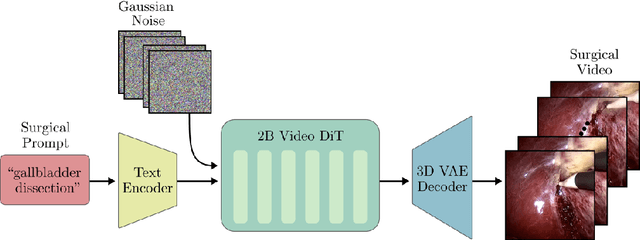
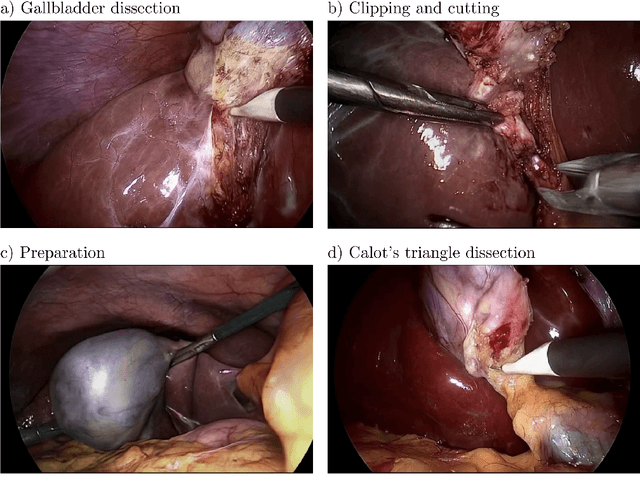

Diffusion-based video generation models have made significant strides, producing outputs with improved visual fidelity, temporal coherence, and user control. These advancements hold great promise for improving surgical education by enabling more realistic, diverse, and interactive simulation environments. In this study, we introduce SurGen, a text-guided diffusion model tailored for surgical video synthesis, producing the highest resolution and longest duration videos among existing surgical video generation models. We validate the visual and temporal quality of the outputs using standard image and video generation metrics. Additionally, we assess their alignment to the corresponding text prompts through a deep learning classifier trained on surgical data. Our results demonstrate the potential of diffusion models to serve as valuable educational tools for surgical trainees.
GP-VLS: A general-purpose vision language model for surgery
Jul 27, 2024Surgery requires comprehensive medical knowledge, visual assessment skills, and procedural expertise. While recent surgical AI models have focused on solving task-specific problems, there is a need for general-purpose systems that can understand surgical scenes and interact through natural language. This paper introduces GP-VLS, a general-purpose vision language model for surgery that integrates medical and surgical knowledge with visual scene understanding. For comprehensively evaluating general-purpose surgical models, we propose SurgiQual, which evaluates across medical and surgical knowledge benchmarks as well as surgical vision-language questions. To train GP-VLS, we develop six new datasets spanning medical knowledge, surgical textbooks, and vision-language pairs for tasks like phase recognition and tool identification. We show that GP-VLS significantly outperforms existing open- and closed-source models on surgical vision-language tasks, with 8-21% improvements in accuracy across SurgiQual benchmarks. GP-VLS also demonstrates strong performance on medical and surgical knowledge tests compared to open-source alternatives. Overall, GP-VLS provides an open-source foundation for developing AI assistants to support surgeons across a wide range of tasks and scenarios.
MediSyn: Text-Guided Diffusion Models for Broad Medical 2D and 3D Image Synthesis
May 16, 2024Diffusion models have recently gained significant traction due to their ability to generate high-fidelity and diverse images and videos conditioned on text prompts. In medicine, this application promises to address the critical challenge of data scarcity, a consequence of barriers in data sharing, stringent patient privacy regulations, and disparities in patient population and demographics. By generating realistic and varying medical 2D and 3D images, these models offer a rich, privacy-respecting resource for algorithmic training and research. To this end, we introduce MediSyn, a pair of instruction-tuned text-guided latent diffusion models with the ability to generate high-fidelity and diverse medical 2D and 3D images across specialties and modalities. Through established metrics, we show significant improvement in broad medical image and video synthesis guided by text prompts.
Almanac Copilot: Towards Autonomous Electronic Health Record Navigation
May 14, 2024



Clinicians spend large amounts of time on clinical documentation, and inefficiencies impact quality of care and increase clinician burnout. Despite the promise of electronic medical records (EMR), the transition from paper-based records has been negatively associated with clinician wellness, in part due to poor user experience, increased burden of documentation, and alert fatigue. In this study, we present Almanac Copilot, an autonomous agent capable of assisting clinicians with EMR-specific tasks such as information retrieval and order placement. On EHR-QA, a synthetic evaluation dataset of 300 common EHR queries based on real patient data, Almanac Copilot obtains a successful task completion rate of 74% (n = 221 tasks) with a mean score of 2.45 over 3 (95% CI:2.34-2.56). By automating routine tasks and streamlining the documentation process, our findings highlight the significant potential of autonomous agents to mitigate the cognitive load imposed on clinicians by current EMR systems.
A Generalizable Deep Learning System for Cardiac MRI
Dec 01, 2023



Cardiac MRI allows for a comprehensive assessment of myocardial structure, function, and tissue characteristics. Here we describe a foundational vision system for cardiac MRI, capable of representing the breadth of human cardiovascular disease and health. Our deep learning model is trained via self-supervised contrastive learning, by which visual concepts in cine-sequence cardiac MRI scans are learned from the raw text of the accompanying radiology reports. We train and evaluate our model on data from four large academic clinical institutions in the United States. We additionally showcase the performance of our models on the UK BioBank, and two additional publicly available external datasets. We explore emergent zero-shot capabilities of our system, and demonstrate remarkable performance across a range of tasks; including the problem of left ventricular ejection fraction regression, and the diagnosis of 35 different conditions such as cardiac amyloidosis and hypertrophic cardiomyopathy. We show that our deep learning system is capable of not only understanding the staggering complexity of human cardiovascular disease, but can be directed towards clinical problems of interest yielding impressive, clinical grade diagnostic accuracy with a fraction of the training data typically required for such tasks.
Echocardiogram Foundation Model -- Application 1: Estimating Ejection Fraction
Nov 21, 2023



Cardiovascular diseases stand as the primary global cause of mortality. Among the various imaging techniques available for visualising the heart and evaluating its function, echocardiograms emerge as the preferred choice due to their safety and low cost. Quantifying cardiac function based on echocardiograms is very laborious, time-consuming and subject to high interoperator variability. In this work, we introduce EchoAI, an echocardiogram foundation model, that is trained using self-supervised learning (SSL) on 1.5 million echocardiograms. We evaluate our approach by fine-tuning EchoAI to estimate the ejection fraction achieving a mean absolute percentage error of 9.40%. This level of accuracy aligns with the performance of expert sonographers.
Almanac: Knowledge-Grounded Language Models for Clinical Medicine
Mar 01, 2023Large-language models have recently demonstrated impressive zero-shot capabilities in a variety of natural language tasks such as summarization, dialogue generation, and question-answering. Despite many promising applications in clinical medicine (e.g. medical record documentation, treatment guideline-lookup), adoption of these models in real-world settings has been largely limited by their tendency to generate factually incorrect and sometimes even toxic statements. In this paper we explore the ability of large-language models to facilitate and streamline medical guidelines and recommendation referencing: by enabling these model to access external point-of-care tools in response to physician queries, we demonstrate significantly improved factual grounding, helpfulness, and safety in a variety of clinical scenarios.
Simulating time to event prediction with spatiotemporal echocardiography deep learning
Mar 03, 2021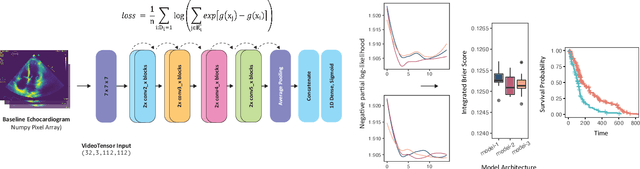
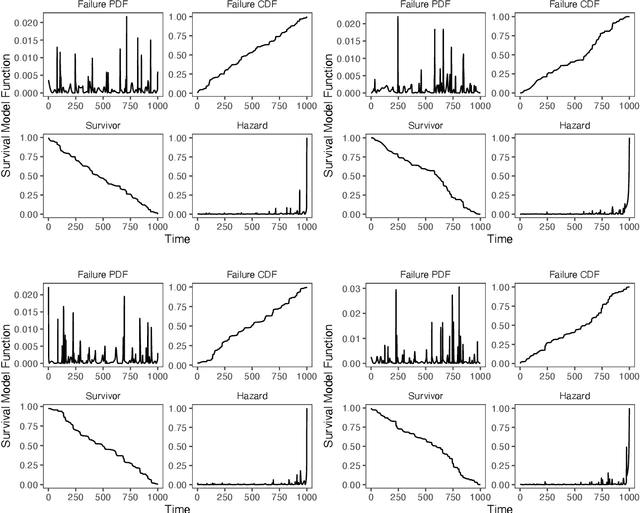
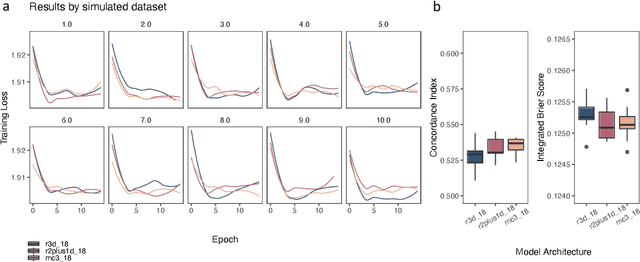
Integrating methods for time-to-event prediction with diagnostic imaging modalities is of considerable interest, as accurate estimates of survival requires accounting for censoring of individuals within the observation period. New methods for time-to-event prediction have been developed by extending the cox-proportional hazards model with neural networks. In this paper, to explore the feasibility of these methods when applied to deep learning with echocardiography videos, we utilize the Stanford EchoNet-Dynamic dataset with over 10,000 echocardiograms, and generate simulated survival datasets based on the expert annotated ejection fraction readings. By training on just the simulated survival outcomes, we show that spatiotemporal convolutional neural networks yield accurate survival estimates.
Medical Imaging and Machine Learning
Mar 02, 2021

Advances in computing power, deep learning architectures, and expert labelled datasets have spurred the development of medical imaging artificial intelligence systems that rival clinical experts in a variety of scenarios. The National Institutes of Health in 2018 identified key focus areas for the future of artificial intelligence in medical imaging, creating a foundational roadmap for research in image acquisition, algorithms, data standardization, and translatable clinical decision support systems. Among the key issues raised in the report: data availability, need for novel computing architectures and explainable AI algorithms, are still relevant despite the tremendous progress made over the past few years alone. Furthermore, translational goals of data sharing, validation of performance for regulatory approval, generalizability and mitigation of unintended bias must be accounted for early in the development process. In this perspective paper we explore challenges unique to high dimensional clinical imaging data, in addition to highlighting some of the technical and ethical considerations in developing high-dimensional, multi-modality, machine learning systems for clinical decision support.
Predicting post-operative right ventricular failure using video-based deep learning
Feb 28, 2021
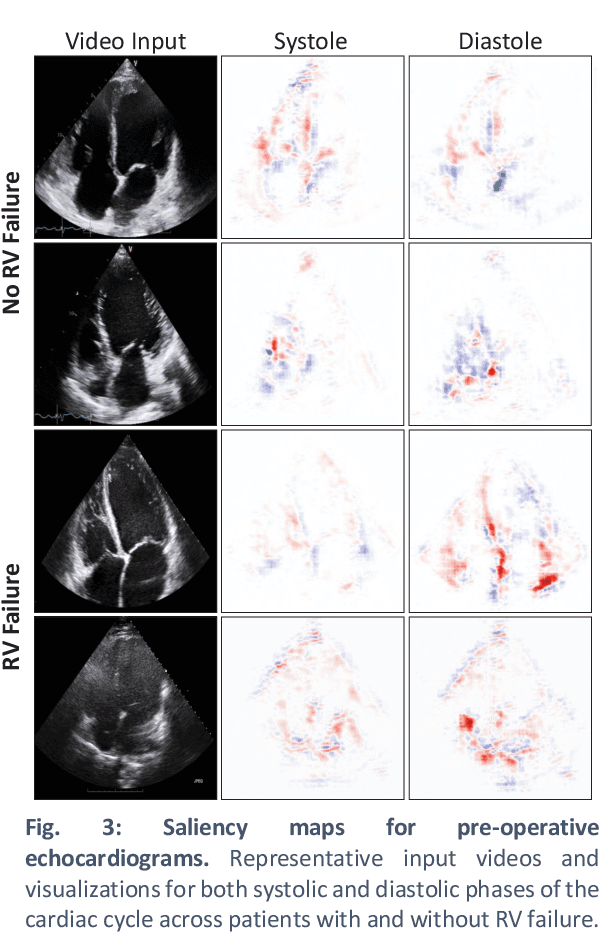
Non-invasive and cost effective in nature, the echocardiogram allows for a comprehensive assessment of the cardiac musculature and valves. Despite progressive improvements over the decades, the rich temporally resolved data in echocardiography videos remain underutilized. Human reads of echocardiograms reduce the complex patterns of cardiac wall motion, to a small list of measurements of heart function. Furthermore, all modern echocardiography artificial intelligence (AI) systems are similarly limited by design - automating measurements of the same reductionist metrics rather than utilizing the wealth of data embedded within each echo study. This underutilization is most evident in situations where clinical decision making is guided by subjective assessments of disease acuity, and tools that predict disease onset within clinically actionable timeframes are unavailable. Predicting the likelihood of developing post-operative right ventricular failure (RV failure) in the setting of mechanical circulatory support is one such clinical example. To address this, we developed a novel video AI system trained to predict post-operative right ventricular failure (RV failure), using the full spatiotemporal density of information from pre-operative echocardiography scans. We achieve an AUC of 0.729, specificity of 52% at 80% sensitivity and 46% sensitivity at 80% specificity. Furthermore, we show that our ML system significantly outperforms a team of human experts tasked with predicting RV failure on independent clinical evaluation. Finally, the methods we describe are generalizable to any cardiac clinical decision support application where treatment or patient selection is guided by qualitative echocardiography assessments.