 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurGen: Text-Guided Diffusion Model for Surgical Video Generation
Aug 26, 2024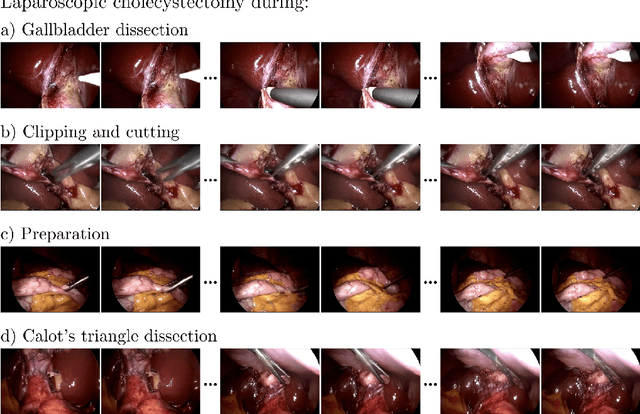
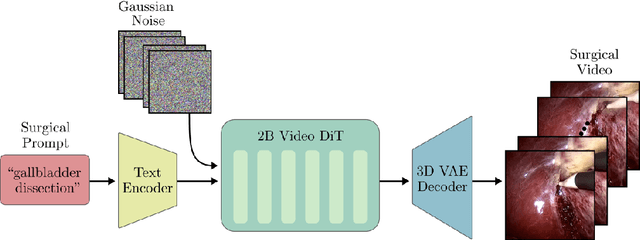
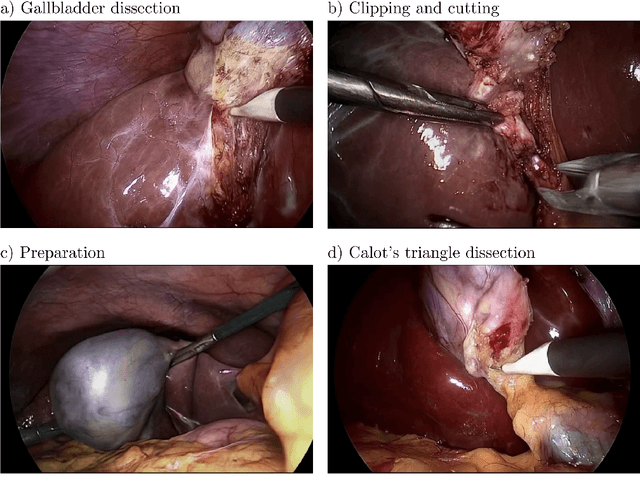

Diffusion-based video generation models have made significant strides, producing outputs with improved visual fidelity, temporal coherence, and user control. These advancements hold great promise for improving surgical education by enabling more realistic, diverse, and interactive simulation environments. In this study, we introduce SurGen, a text-guided diffusion model tailored for surgical video synthesis, producing the highest resolution and longest duration videos among existing surgical video generation models. We validate the visual and temporal quality of the outputs using standard image and video generation metrics. Additionally, we assess their alignment to the corresponding text prompts through a deep learning classifier trained on surgical data. Our results demonstrate the potential of diffusion models to serve as valuable educational tools for surgical trainees.