 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputation-Aware Kalman Filtering with Model Selection for Neural Dynamics
May 31, 2026Due to their explicit priors and ability to model uncertainty, Bayesian methods have played a major role in dynamical latent variable modeling of single-cell neural recordings. However, modern-sized datasets have made overparameterized deep networks the preferred methods of choice due to their predictive power and favorable computational scaling. While many posterior approximations exist, all incur approximation errors. Recent work accounts for this error in the form of computational uncertainty but comes at the cost of quadratic complexity and assumes fixed model hyperparameters. Here we extend this development to model selection, including a novel training loss and optimization scheme, which yields tractable inference in large state-spaces. We introduce a framework, the Computation-Aware State-Space Model (CASSM), specifically designed for the scale-imbalanced regime, where the number of trials is significantly lower than the number of recorded neurons. In this regime, for both synthetic and real data, we show that our method is competitive with data-hungry deep networks, with significantly improved uncertainty calibration over previous attempts to scale Bayesian methods. Our experiments provide a roadmap to neuroscience researchers in choosing from a host of potential dynamical latent variable models given key dataset properties and constraints.
Variational Deep Learning via Implicit Regularization
May 26, 2025Modern deep learning models generalize remarkably well in-distribution, despite being overparametrized and trained with little to no explicit regularization. Instead, current theory credits implicit regularization imposed by the choice of architecture, hyperparameters and optimization procedure. However, deploying deep learning models out-of-distribution, in sequential decision-making tasks, or in safety-critical domains, necessitates reliable uncertainty quantification, not just a point estimate. The machinery of modern approximate inference -- Bayesian deep learning -- should answer the need for uncertainty quantification, but its effectiveness has been challenged by our inability to define useful explicit inductive biases through priors, as well as the associated computational burden. Instead, in this work we demonstrate, both theoretically and empirically, how to regularize a variational deep network implicitly via the optimization procedure, just as for standard deep learning. We fully characterize the inductive bias of (stochastic) gradient descent in the case of an overparametrized linear model as generalized variational inference and demonstrate the importance of the choice of parametrization. Finally, we show empirically that our approach achieves strong in- and out-of-distribution performance without tuning of additional hyperparameters and with minimal time and memory overhead over standard deep learning.
Scalable Differentially Private Bayesian Optimization
Feb 09, 2025In recent years, there has been much work on scaling Bayesian Optimization to high-dimensional problems, for example hyperparameter tuning in large neural network models. These scalable methods have been successful, finding high objective values much more quickly than traditional global Bayesian Optimization or random search-based methods. At the same time, these large neural network models often use sensitive data, but preservation of Differential Privacy has not scaled alongside these modern Bayesian Optimization procedures. Here we develop a method to privately estimate potentially high-dimensional parameter spaces using Gradient Informative Bayesian Optimization. Our theoretical results prove that under suitable conditions, our method converges exponentially fast to a ball around the optimal parameter configuration. Moreover, regardless of whether the assumptions are satisfied, we show that our algorithm maintains privacy and empirically demonstrates superior performance to existing methods in the high-dimensional hyperparameter setting.
Computation-Aware Gaussian Processes: Model Selection And Linear-Time Inference
Nov 01, 2024



Model selection in Gaussian processes scales prohibitively with the size of the training dataset, both in time and memory. While many approximations exist, all incur inevitable approximation error. Recent work accounts for this error in the form of computational uncertainty, which enables -- at the cost of quadratic complexity -- an explicit tradeoff between computation and precision. Here we extend this development to model selection, which requires significant enhancements to the existing approach, including linear-time scaling in the size of the dataset. We propose a novel training loss for hyperparameter optimization and demonstrate empirically that the resulting method can outperform SGPR, CGGP and SVGP, state-of-the-art methods for GP model selection, on medium to large-scale datasets. Our experiments show that model selection for computation-aware GPs trained on 1.8 million data points can be done within a few hours on a single GPU. As a result of this work, Gaussian processes can be trained on large-scale datasets without significantly compromising their ability to quantify uncertainty -- a fundamental prerequisite for optimal decision-making.
Theoretical Limitations of Ensembles in the Age of Overparameterization
Oct 21, 2024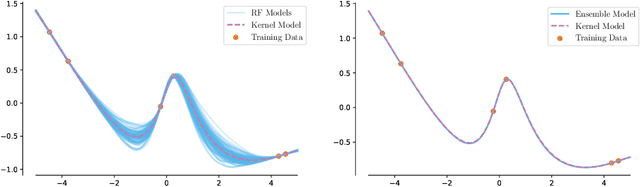
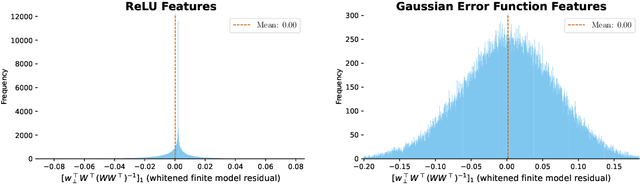
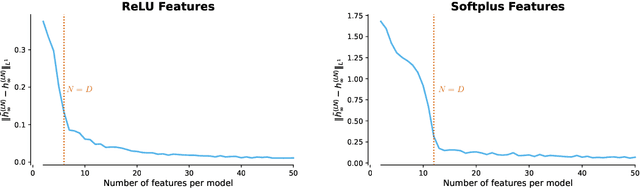
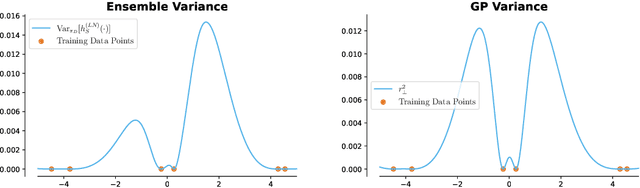
Classic tree-based ensembles generalize better than any single decision tree. In contrast, recent empirical studies find that modern ensembles of (overparameterized) neural networks may not provide any inherent generalization advantage over single but larger neural networks. This paper clarifies how modern overparameterized ensembles differ from their classic underparameterized counterparts, using ensembles of random feature (RF) regressors as a basis for developing theory. In contrast to the underparameterized regime, where ensembling typically induces regularization and increases generalization, we prove that infinite ensembles of overparameterized RF regressors become pointwise equivalent to (single) infinite-width RF regressors. This equivalence, which is exact for ridgeless models and approximate for small ridge penalties, implies that overparameterized ensembles and single large models exhibit nearly identical generalization. As a consequence, we can characterize the predictive variance amongst ensemble members, and demonstrate that it quantifies the expected effects of increasing capacity rather than capturing any conventional notion of uncertainty. Our results challenge common assumptions about the advantages of ensembles in overparameterized settings, prompting a reconsideration of how well intuitions from underparameterized ensembles transfer to deep ensembles and the overparameterized regime.
Estimating the Hallucination Rate of Generative AI
Jun 11, 2024



This work is about estimating the hallucination rate for in-context learning (ICL) with Generative AI. In ICL, a conditional generative model (CGM) is prompted with a dataset and asked to make a prediction based on that dataset. The Bayesian interpretation of ICL assumes that the CGM is calculating a posterior predictive distribution over an unknown Bayesian model of a latent parameter and data. With this perspective, we define a \textit{hallucination} as a generated prediction that has low-probability under the true latent parameter. We develop a new method that takes an ICL problem -- that is, a CGM, a dataset, and a prediction question -- and estimates the probability that a CGM will generate a hallucination. Our method only requires generating queries and responses from the model and evaluating its response log probability. We empirically evaluate our method on synthetic regression and natural language ICL tasks using large language models.
Approximation-Aware Bayesian Optimization
Jun 06, 2024High-dimensional Bayesian optimization (BO) tasks such as molecular design often require 10,000 function evaluations before obtaining meaningful results. While methods like sparse variational Gaussian processes (SVGPs) reduce computational requirements in these settings, the underlying approximations result in suboptimal data acquisitions that slow the progress of optimization. In this paper we modify SVGPs to better align with the goals of BO: targeting informed data acquisition rather than global posterior fidelity. Using the framework of utility-calibrated variational inference, we unify GP approximation and data acquisition into a joint optimization problem, thereby ensuring optimal decisions under a limited computational budget. Our approach can be used with any decision-theoretic acquisition function and is compatible with trust region methods like TuRBO. We derive efficient joint objectives for the expected improvement and knowledge gradient acquisition functions in both the standard and batch BO settings. Our approach outperforms standard SVGPs on high-dimensional benchmark tasks in control and molecular design.
LoRA Learns Less and Forgets Less
May 15, 2024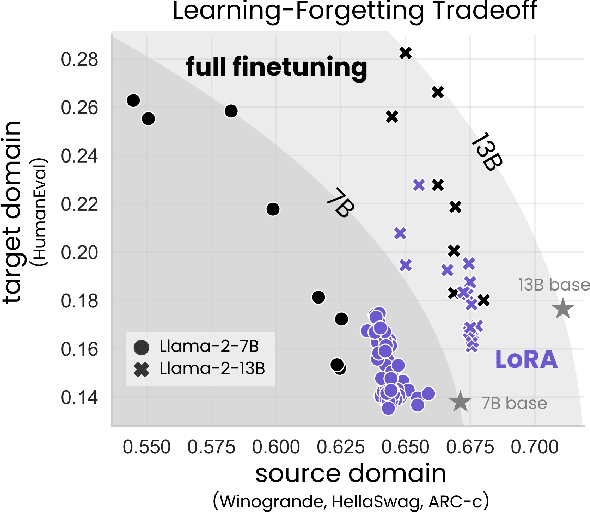

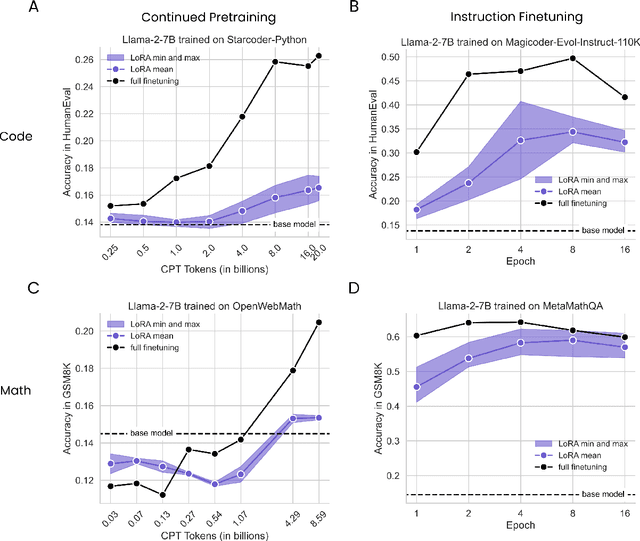

Low-Rank Adaptation (LoRA) is a widely-used parameter-efficient finetuning method for large language models. LoRA saves memory by training only low rank perturbations to selected weight matrices. In this work, we compare the performance of LoRA and full finetuning on two target domains, programming and mathematics. We consider both the instruction finetuning ($\approx$100K prompt-response pairs) and continued pretraining ($\approx$10B unstructured tokens) data regimes. Our results show that, in most settings, LoRA substantially underperforms full finetuning. Nevertheless, LoRA exhibits a desirable form of regularization: it better maintains the base model's performance on tasks outside the target domain. We show that LoRA provides stronger regularization compared to common techniques such as weight decay and dropout; it also helps maintain more diverse generations. We show that full finetuning learns perturbations with a rank that is 10-100X greater than typical LoRA configurations, possibly explaining some of the reported gaps. We conclude by proposing best practices for finetuning with LoRA.
Practical and Asymptotically Exact Conditional Sampling in Diffusion Models
Jun 30, 2023Diffusion models have been successful on a range of conditional generation tasks including molecular design and text-to-image generation. However, these achievements have primarily depended on task-specific conditional training or error-prone heuristic approximations. Ideally, a conditional generation method should provide exact samples for a broad range of conditional distributions without requiring task-specific training. To this end, we introduce the Twisted Diffusion Sampler, or TDS. TDS is a sequential Monte Carlo (SMC) algorithm that targets the conditional distributions of diffusion models. The main idea is to use twisting, an SMC technique that enjoys good computational efficiency, to incorporate heuristic approximations without compromising asymptotic exactness. We first find in simulation and on MNIST image inpainting and class-conditional generation tasks that TDS provides a computational statistical trade-off, yielding more accurate approximations with many particles but with empirical improvements over heuristics with as few as two particles. We then turn to motif-scaffolding, a core task in protein design, using a TDS extension to Riemannian diffusion models. On benchmark test cases, TDS allows flexible conditioning criteria and often outperforms the state of the art.
Pathologies of Predictive Diversity in Deep Ensembles
Feb 03, 2023



Classical results establish that ensembles of small models benefit when predictive diversity is encouraged, through bagging, boosting, and similar. Here we demonstrate that this intuition does not carry over to ensembles of deep neural networks used for classification, and in fact the opposite can be true. Unlike regression models or small (unconfident) classifiers, predictions from large (confident) neural networks concentrate in vertices of the probability simplex. Thus, decorrelating these points necessarily moves the ensemble prediction away from vertices, harming confidence and moving points across decision boundaries. Through large scale experiments, we demonstrate that diversity-encouraging regularizers hurt the performance of high-capacity deep ensembles used for classification. Even more surprisingly, discouraging predictive diversity can be beneficial. Together this work strongly suggests that the best strategy for deep ensembles is utilizing more accurate, but likely less diverse, component models.