 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-time Physics Alignment of Video Generative Models with Latent World Models
Jan 15, 2026State-of-the-art video generative models produce promising visual content yet often violate basic physics principles, limiting their utility. While some attribute this deficiency to insufficient physics understanding from pre-training, we find that the shortfall in physics plausibility also stems from suboptimal inference strategies. We therefore introduce WMReward and treat improving physics plausibility of video generation as an inference-time alignment problem. In particular, we leverage the strong physics prior of a latent world model (here, VJEPA-2) as a reward to search and steer multiple candidate denoising trajectories, enabling scaling test-time compute for better generation performance. Empirically, our approach substantially improves physics plausibility across image-conditioned, multiframe-conditioned, and text-conditioned generation settings, with validation from human preference study. Notably, in the ICCV 2025 Perception Test PhysicsIQ Challenge, we achieve a final score of 62.64%, winning first place and outperforming the previous state of the art by 7.42%. Our work demonstrates the viability of using latent world models to improve physics plausibility of video generation, beyond this specific instantiation or parameterization.
Can Generative AI Solve Your In-Context Learning Problem? A Martingale Perspective
Dec 08, 2024
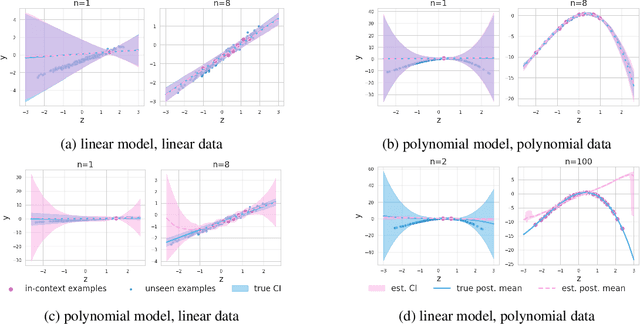
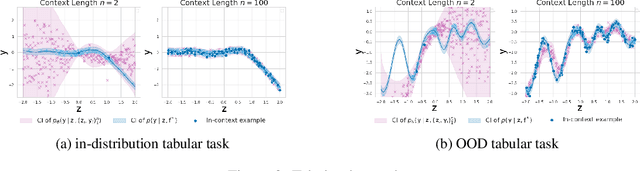
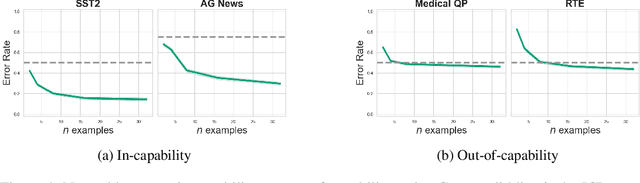
This work is about estimating when a conditional generative model (CGM) can solve an in-context learning (ICL) problem. An in-context learning (ICL) problem comprises a CGM, a dataset, and a prediction task. The CGM could be a multi-modal foundation model; the dataset, a collection of patient histories, test results, and recorded diagnoses; and the prediction task to communicate a diagnosis to a new patient. A Bayesian interpretation of ICL assumes that the CGM computes a posterior predictive distribution over an unknown Bayesian model defining a joint distribution over latent explanations and observable data. From this perspective, Bayesian model criticism is a reasonable approach to assess the suitability of a given CGM for an ICL problem. However, such approaches -- like posterior predictive checks (PPCs) -- often assume that we can sample from the likelihood and posterior defined by the Bayesian model, which are not explicitly given for contemporary CGMs. To address this, we show when ancestral sampling from the predictive distribution of a CGM is equivalent to sampling datasets from the posterior predictive of the assumed Bayesian model. Then we develop the generative predictive $p$-value, which enables PPCs and their cousins for contemporary CGMs. The generative predictive $p$-value can then be used in a statistical decision procedure to determine when the model is appropriate for an ICL problem. Our method only requires generating queries and responses from a CGM and evaluating its response log probability. We empirically evaluate our method on synthetic tabular, imaging, and natural language ICL tasks using large language models.
Hypothesis Testing the Circuit Hypothesis in LLMs
Oct 16, 2024Large language models (LLMs) demonstrate surprising capabilities, but we do not understand how they are implemented. One hypothesis suggests that these capabilities are primarily executed by small subnetworks within the LLM, known as circuits. But how can we evaluate this hypothesis? In this paper, we formalize a set of criteria that a circuit is hypothesized to meet and develop a suite of hypothesis tests to evaluate how well circuits satisfy them. The criteria focus on the extent to which the LLM's behavior is preserved, the degree of localization of this behavior, and whether the circuit is minimal. We apply these tests to six circuits described in the research literature. We find that synthetic circuits -- circuits that are hard-coded in the model -- align with the idealized properties. Circuits discovered in Transformer models satisfy the criteria to varying degrees. To facilitate future empirical studies of circuits, we created the \textit{circuitry} package, a wrapper around the \textit{TransformerLens} library, which abstracts away lower-level manipulations of hooks and activations. The software is available at \url{https://github.com/blei-lab/circuitry}.
Estimating the Hallucination Rate of Generative AI
Jun 11, 2024



This work is about estimating the hallucination rate for in-context learning (ICL) with Generative AI. In ICL, a conditional generative model (CGM) is prompted with a dataset and asked to make a prediction based on that dataset. The Bayesian interpretation of ICL assumes that the CGM is calculating a posterior predictive distribution over an unknown Bayesian model of a latent parameter and data. With this perspective, we define a \textit{hallucination} as a generated prediction that has low-probability under the true latent parameter. We develop a new method that takes an ICL problem -- that is, a CGM, a dataset, and a prediction question -- and estimates the probability that a CGM will generate a hallucination. Our method only requires generating queries and responses from the model and evaluating its response log probability. We empirically evaluate our method on synthetic regression and natural language ICL tasks using large language models.
Treeffuser: Probabilistic Predictions via Conditional Diffusions with Gradient-Boosted Trees
Jun 11, 2024Probabilistic prediction aims to compute predictive distributions rather than single-point predictions. These distributions enable practitioners to quantify uncertainty, compute risk, and detect outliers. However, most probabilistic methods assume parametric responses, such as Gaussian or Poisson distributions. When these assumptions fail, such models lead to bad predictions and poorly calibrated uncertainty. In this paper, we propose Treeffuser, an easy-to-use method for probabilistic prediction on tabular data. The idea is to learn a conditional diffusion model where the score function is estimated using gradient-boosted trees. The conditional diffusion model makes Treeffuser flexible and non-parametric, while the gradient-boosted trees make it robust and easy to train on CPUs. Treeffuser learns well-calibrated predictive distributions and can handle a wide range of regression tasks -- including those with multivariate, multimodal, and skewed responses. % , as well as categorical predictors and missing data We study Treeffuser on synthetic and real data and show that it outperforms existing methods, providing better-calibrated probabilistic predictions. We further demonstrate its versatility with an application to inventory allocation under uncertainty using sales data from Walmart. We implement Treeffuser in \href{https://github.com/blei-lab/treeffuser}{https://github.com/blei-lab/treeffuser}.