 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypothesis Testing the Circuit Hypothesis in LLMs
Oct 16, 2024Large language models (LLMs) demonstrate surprising capabilities, but we do not understand how they are implemented. One hypothesis suggests that these capabilities are primarily executed by small subnetworks within the LLM, known as circuits. But how can we evaluate this hypothesis? In this paper, we formalize a set of criteria that a circuit is hypothesized to meet and develop a suite of hypothesis tests to evaluate how well circuits satisfy them. The criteria focus on the extent to which the LLM's behavior is preserved, the degree of localization of this behavior, and whether the circuit is minimal. We apply these tests to six circuits described in the research literature. We find that synthetic circuits -- circuits that are hard-coded in the model -- align with the idealized properties. Circuits discovered in Transformer models satisfy the criteria to varying degrees. To facilitate future empirical studies of circuits, we created the \textit{circuitry} package, a wrapper around the \textit{TransformerLens} library, which abstracts away lower-level manipulations of hooks and activations. The software is available at \url{https://github.com/blei-lab/circuitry}.
Causal-structure Driven Augmentations for Text OOD Generalization
Oct 19, 2023



The reliance of text classifiers on spurious correlations can lead to poor generalization at deployment, raising concerns about their use in safety-critical domains such as healthcare. In this work, we propose to use counterfactual data augmentation, guided by knowledge of the causal structure of the data, to simulate interventions on spurious features and to learn more robust text classifiers. We show that this strategy is appropriate in prediction problems where the label is spuriously correlated with an attribute. Under the assumptions of such problems, we discuss the favorable sample complexity of counterfactual data augmentation, compared to importance re-weighting. Pragmatically, we match examples using auxiliary data, based on diff-in-diff methodology, and use a large language model (LLM) to represent a conditional probability of text. Through extensive experimentation on learning caregiver-invariant predictors of clinical diagnoses from medical narratives and on semi-synthetic data, we demonstrate that our method for simulating interventions improves out-of-distribution (OOD) accuracy compared to baseline invariant learning algorithms.
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Jul 27, 2023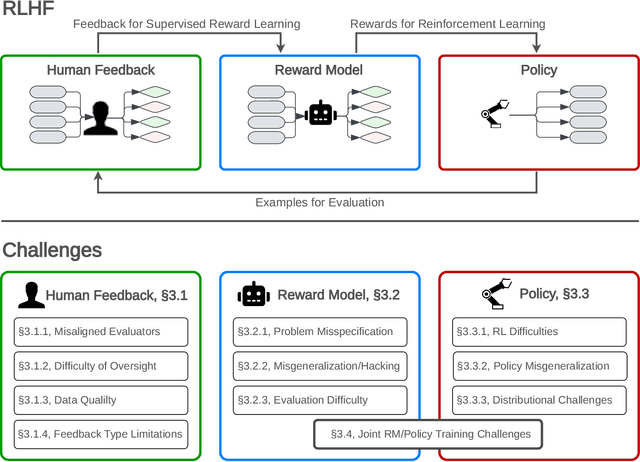
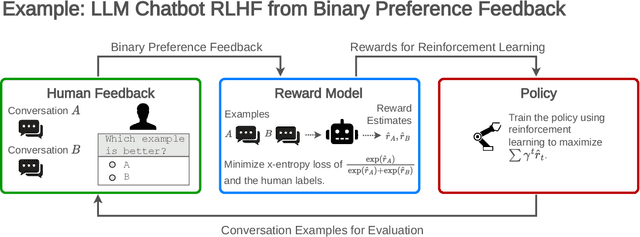
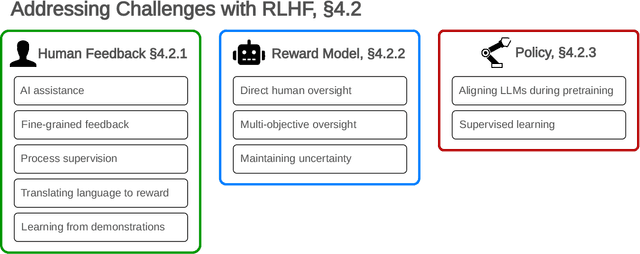

Reinforcement learning from human feedback (RLHF) is a technique for training AI systems to align with human goals. RLHF has emerged as the central method used to finetune state-of-the-art large language models (LLMs). Despite this popularity, there has been relatively little public work systematizing its flaws. In this paper, we (1) survey open problems and fundamental limitations of RLHF and related methods; (2) overview techniques to understand, improve, and complement RLHF in practice; and (3) propose auditing and disclosure standards to improve societal oversight of RLHF systems. Our work emphasizes the limitations of RLHF and highlights the importance of a multi-faceted approach to the development of safer AI systems.
Evaluating the Moral Beliefs Encoded in LLMs
Jul 26, 2023This paper presents a case study on the design, administration, post-processing, and evaluation of surveys on large language models (LLMs). It comprises two components: (1) A statistical method for eliciting beliefs encoded in LLMs. We introduce statistical measures and evaluation metrics that quantify the probability of an LLM "making a choice", the associated uncertainty, and the consistency of that choice. (2) We apply this method to study what moral beliefs are encoded in different LLMs, especially in ambiguous cases where the right choice is not obvious. We design a large-scale survey comprising 680 high-ambiguity moral scenarios (e.g., "Should I tell a white lie?") and 687 low-ambiguity moral scenarios (e.g., "Should I stop for a pedestrian on the road?"). Each scenario includes a description, two possible actions, and auxiliary labels indicating violated rules (e.g., "do not kill"). We administer the survey to 28 open- and closed-source LLMs. We find that (a) in unambiguous scenarios, most models "choose" actions that align with commonsense. In ambiguous cases, most models express uncertainty. (b) Some models are uncertain about choosing the commonsense action because their responses are sensitive to the question-wording. (c) Some models reflect clear preferences in ambiguous scenarios. Specifically, closed-source models tend to agree with each other.
An Invariant Learning Characterization of Controlled Text Generation
May 31, 2023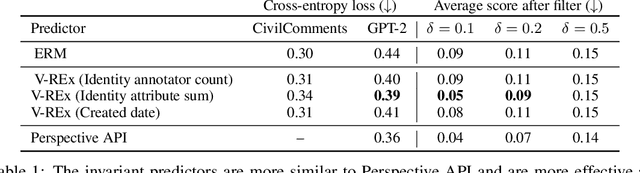
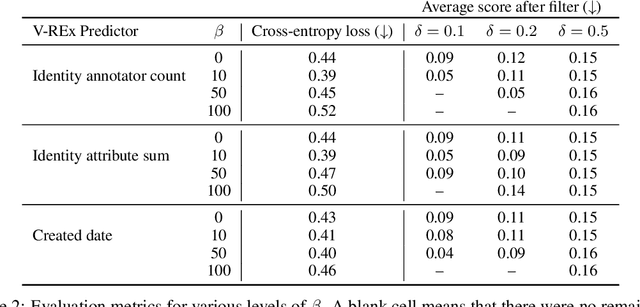
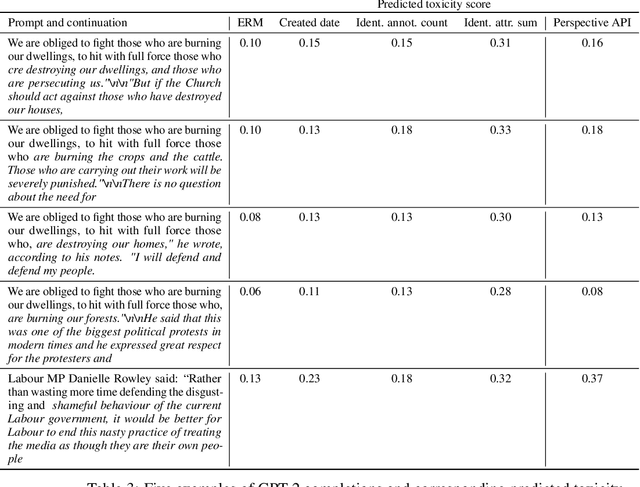
Controlled generation refers to the problem of creating text that contains stylistic or semantic attributes of interest. Many approaches reduce this problem to training a predictor of the desired attribute. For example, researchers hoping to deploy a large language model to produce non-toxic content may use a toxicity classifier to filter generated text. In practice, the generated text to classify, which is determined by user prompts, may come from a wide range of distributions. In this paper, we show that the performance of controlled generation may be poor if the distributions of text in response to user prompts differ from the distribution the predictor was trained on. To address this problem, we cast controlled generation under distribution shift as an invariant learning problem: the most effective predictor should be invariant across multiple text environments. We then discuss a natural solution that arises from this characterization and propose heuristics for selecting natural environments. We study this characterization and the proposed method empirically using both synthetic and real data. Experiments demonstrate both the challenge of distribution shift in controlled generation and the potential of invariance methods in this setting.
Invariant Representation Learning for Treatment Effect Estimation
Nov 24, 2020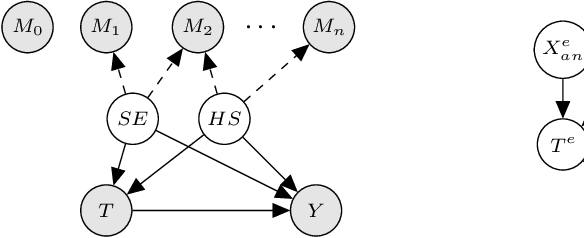
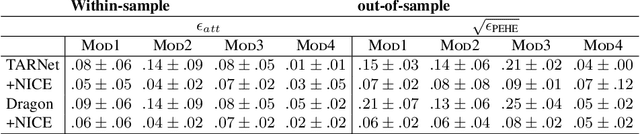
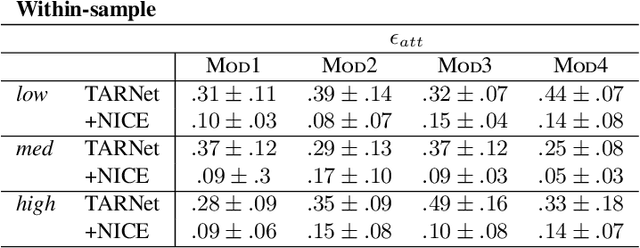
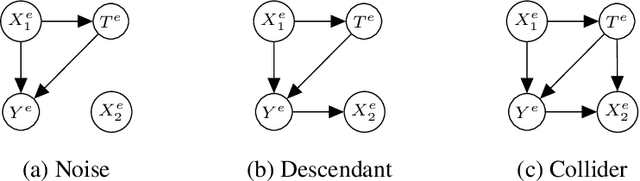
The defining challenge for causal inference from observational data is the presence of `confounders', covariates that affect both treatment assignment and the outcome. To address this challenge, practitioners collect and adjust for the covariates, hoping that they adequately correct for confounding. However, including every observed covariate in the adjustment runs the risk of including `bad controls', variables that \emph{induce} bias when they are conditioned on. The problem is that we do not always know which variables in the covariate set are safe to adjust for and which are not. To address this problem, we develop Nearly Invariant Causal Estimation (NICE). NICE uses invariant risk minimization (IRM) [Arj19] to learn a representation of the covariates that, under some assumptions, strips out bad controls but preserves sufficient information to adjust for confounding. Adjusting for the learned representation, rather than the covariates themselves, avoids the induced bias and provides valid causal inferences. NICE is appropriate in the following setting. i) We observe data from multiple environments that share a common causal mechanism for the outcome, but that differ in other ways. ii) In each environment, the collected covariates are a superset of the causal parents of the outcome, and contain sufficient information for causal identification. iii) But the covariates also may contain bad controls, and it is unknown which covariates are safe to adjust for and which ones induce bias. We evaluate NICE on both synthetic and semi-synthetic data. When the covariates contain unknown collider variables and other bad controls, NICE performs better than existing methods that adjust for all the covariates.
Adapting Neural Networks for the Estimation of Treatment Effects
Jun 05, 2019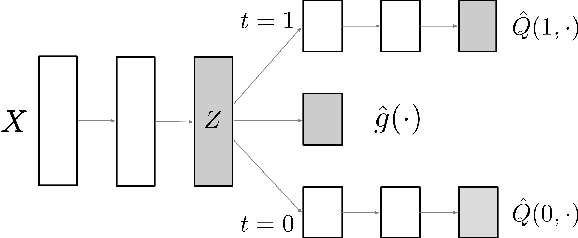
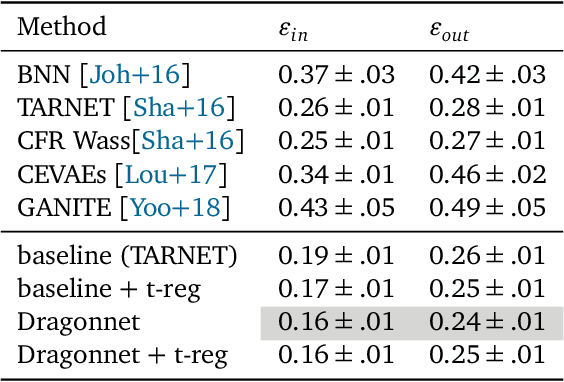

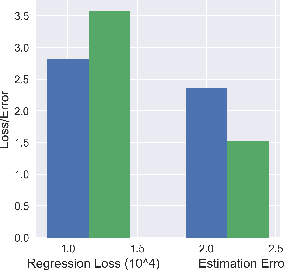
This paper addresses the use of neural networks for the estimation of treatment effects from observational data. Generally, estimation proceeds in two stages. First, we fit models for the expected outcome and the probability of treatment (propensity score) for each unit. Second, we plug these fitted models into a downstream estimator of the effect. Neural networks are a natural choice for the models in the first step. The question we address is: how can we adapt the design and training of the neural networks used in the first step in order to improve the quality of the final estimate of the treatment effect? We propose two adaptations based on insights from the statistical literature on the estimation of treatment effects. The first is a new architecture, the Dragonnet, that exploits the sufficiency of the propensity score for estimation adjustment. The second is a regularization procedure, targeted regularization, that induces a bias towards models that have non-parametrically optimal asymptotic properties `out-of-the-box`. Studies on benchmark datasets for causal inference show these adaptations outperform existing methods. Code is available at github.com/claudiashi57/dragonnet