 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvariant Representation Learning for Treatment Effect Estimation
Paper and Code
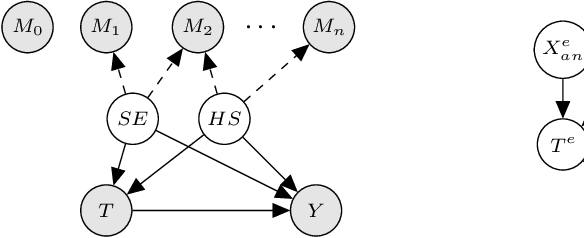
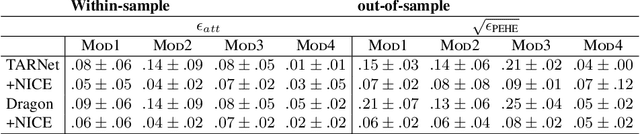
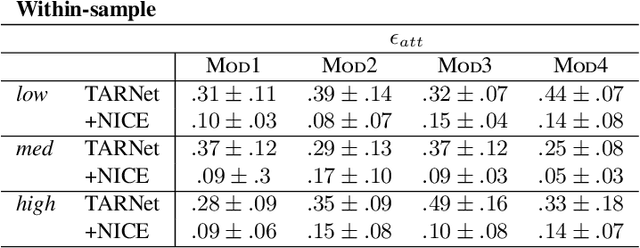
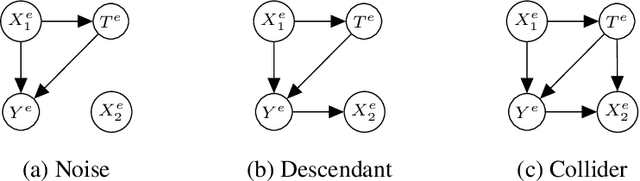
The defining challenge for causal inference from observational data is the presence of `confounders', covariates that affect both treatment assignment and the outcome. To address this challenge, practitioners collect and adjust for the covariates, hoping that they adequately correct for confounding. However, including every observed covariate in the adjustment runs the risk of including `bad controls', variables that \emph{induce} bias when they are conditioned on. The problem is that we do not always know which variables in the covariate set are safe to adjust for and which are not. To address this problem, we develop Nearly Invariant Causal Estimation (NICE). NICE uses invariant risk minimization (IRM) [Arj19] to learn a representation of the covariates that, under some assumptions, strips out bad controls but preserves sufficient information to adjust for confounding. Adjusting for the learned representation, rather than the covariates themselves, avoids the induced bias and provides valid causal inferences. NICE is appropriate in the following setting. i) We observe data from multiple environments that share a common causal mechanism for the outcome, but that differ in other ways. ii) In each environment, the collected covariates are a superset of the causal parents of the outcome, and contain sufficient information for causal identification. iii) But the covariates also may contain bad controls, and it is unknown which covariates are safe to adjust for and which ones induce bias. We evaluate NICE on both synthetic and semi-synthetic data. When the covariates contain unknown collider variables and other bad controls, NICE performs better than existing methods that adjust for all the covariates.