 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Has a Foundation Model Found? Using Inductive Bias to Probe for World Models
Jul 09, 2025Foundation models are premised on the idea that sequence prediction can uncover deeper domain understanding, much like how Kepler's predictions of planetary motion later led to the discovery of Newtonian mechanics. However, evaluating whether these models truly capture deeper structure remains a challenge. We develop a technique for evaluating foundation models that examines how they adapt to synthetic datasets generated from some postulated world model. Our technique measures whether the foundation model's inductive bias aligns with the world model, and so we refer to it as an inductive bias probe. Across multiple domains, we find that foundation models can excel at their training tasks yet fail to develop inductive biases towards the underlying world model when adapted to new tasks. We particularly find that foundation models trained on orbital trajectories consistently fail to apply Newtonian mechanics when adapted to new physics tasks. Further analysis reveals that these models behave as if they develop task-specific heuristics that fail to generalize.
Potemkin Understanding in Large Language Models
Jun 26, 2025Large language models (LLMs) are regularly evaluated using benchmark datasets. But what justifies making inferences about an LLM's capabilities based on its answers to a curated set of questions? This paper first introduces a formal framework to address this question. The key is to note that the benchmarks used to test LLMs -- such as AP exams -- are also those used to test people. However, this raises an implication: these benchmarks are only valid tests if LLMs misunderstand concepts in ways that mirror human misunderstandings. Otherwise, success on benchmarks only demonstrates potemkin understanding: the illusion of understanding driven by answers irreconcilable with how any human would interpret a concept. We present two procedures for quantifying the existence of potemkins: one using a specially designed benchmark in three domains, the other using a general procedure that provides a lower-bound on their prevalence. We find that potemkins are ubiquitous across models, tasks, and domains. We also find that these failures reflect not just incorrect understanding, but deeper internal incoherence in concept representations.
Critical Thinking: Which Kinds of Complexity Govern Optimal Reasoning Length?
Apr 02, 2025Large language models (LLMs) often benefit from verbalized reasoning at inference time, but it remains unclear which aspects of task difficulty these extra reasoning tokens address. To investigate this question, we formalize a framework using deterministic finite automata (DFAs). DFAs offer a formalism through which we can characterize task complexity through measurable properties such as run length (number of reasoning steps required) and state-space size (decision complexity). We first show that across different tasks and models of different sizes and training paradigms, there exists an optimal amount of reasoning tokens such that the probability of producing a correct solution is maximized. We then investigate which properties of complexity govern this critical length: we find that task instances with longer corresponding underlying DFA runs (i.e. demand greater latent state-tracking requirements) correlate with longer reasoning lengths, but, surprisingly, that DFA size (i.e. state-space complexity) does not. We then demonstrate an implication of these findings: being able to predict the optimal number of reasoning tokens for new problems and filtering out non-optimal length answers results in consistent accuracy improvements.
Estimating Wage Disparities Using Foundation Models
Sep 15, 2024



One thread of empirical work in social science focuses on decomposing group differences in outcomes into unexplained components and components explained by observable factors. In this paper, we study gender wage decompositions, which require estimating the portion of the gender wage gap explained by career histories of workers. Classical methods for decomposing the wage gap employ simple predictive models of wages which condition on a small set of simple summaries of labor history. The problem is that these predictive models cannot take advantage of the full complexity of a worker's history, and the resulting decompositions thus suffer from omitted variable bias (OVB), where covariates that are correlated with both gender and wages are not included in the model. Here we explore an alternative methodology for wage gap decomposition that employs powerful foundation models, such as large language models, as the predictive engine. Foundation models excel at making accurate predictions from complex, high-dimensional inputs. We use a custom-built foundation model, designed to predict wages from full labor histories, to decompose the gender wage gap. We prove that the way such models are usually trained might still lead to OVB, but develop fine-tuning algorithms that empirically mitigate this issue. Our model captures a richer representation of career history than simple models and predicts wages more accurately. In detail, we first provide a novel set of conditions under which an estimator of the wage gap based on a fine-tuned foundation model is $\sqrt{n}$-consistent. Building on the theory, we then propose methods for fine-tuning foundation models that minimize OVB. Using data from the Panel Study of Income Dynamics, we find that history explains more of the gender wage gap than standard econometric models can measure, and we identify elements of history that are important for reducing OVB.
LABOR-LLM: Language-Based Occupational Representations with Large Language Models
Jun 25, 2024Many empirical studies of labor market questions rely on estimating relatively simple predictive models using small, carefully constructed longitudinal survey datasets based on hand-engineered features. Large Language Models (LLMs), trained on massive datasets, encode vast quantities of world knowledge and can be used for the next job prediction problem. However, while an off-the-shelf LLM produces plausible career trajectories when prompted, the probability with which an LLM predicts a particular job transition conditional on career history will not, in general, align with the true conditional probability in a given population. Recently, Vafa et al. (2024) introduced a transformer-based "foundation model", CAREER, trained using a large, unrepresentative resume dataset, that predicts transitions between jobs; it further demonstrated how transfer learning techniques can be used to leverage the foundation model to build better predictive models of both transitions and wages that reflect conditional transition probabilities found in nationally representative survey datasets. This paper considers an alternative where the fine-tuning of the CAREER foundation model is replaced by fine-tuning LLMs. For the task of next job prediction, we demonstrate that models trained with our approach outperform several alternatives in terms of predictive performance on the survey data, including traditional econometric models, CAREER, and LLMs with in-context learning, even though the LLM can in principle predict job titles that are not allowed in the survey data. Further, we show that our fine-tuned LLM-based models' predictions are more representative of the career trajectories of various workforce subpopulations than off-the-shelf LLM models and CAREER. We conduct experiments and analyses that highlight the sources of the gains in the performance of our models for representative predictions.
Evaluating the World Model Implicit in a Generative Model
Jun 06, 2024Recent work suggests that large language models may implicitly learn world models. How should we assess this possibility? We formalize this question for the case where the underlying reality is governed by a deterministic finite automaton. This includes problems as diverse as simple logical reasoning, geographic navigation, game-playing, and chemistry. We propose new evaluation metrics for world model recovery inspired by the classic Myhill-Nerode theorem from language theory. We illustrate their utility in three domains: game playing, logic puzzles, and navigation. In all domains, the generative models we consider do well on existing diagnostics for assessing world models, but our evaluation metrics reveal their world models to be far less coherent than they appear. Such incoherence creates fragility: using a generative model to solve related but subtly different tasks can lead it to fail badly. Building generative models that meaningfully capture the underlying logic of the domains they model would be immensely valuable; our results suggest new ways to assess how close a given model is to that goal.
Do Large Language Models Perform the Way People Expect? Measuring the Human Generalization Function
Jun 03, 2024What makes large language models (LLMs) impressive is also what makes them hard to evaluate: their diversity of uses. To evaluate these models, we must understand the purposes they will be used for. We consider a setting where these deployment decisions are made by people, and in particular, people's beliefs about where an LLM will perform well. We model such beliefs as the consequence of a human generalization function: having seen what an LLM gets right or wrong, people generalize to where else it might succeed. We collect a dataset of 19K examples of how humans make generalizations across 79 tasks from the MMLU and BIG-Bench benchmarks. We show that the human generalization function can be predicted using NLP methods: people have consistent structured ways to generalize. We then evaluate LLM alignment with the human generalization function. Our results show that -- especially for cases where the cost of mistakes is high -- more capable models (e.g. GPT-4) can do worse on the instances people choose to use them for, exactly because they are not aligned with the human generalization function.
Revisiting Topic-Guided Language Models
Dec 04, 2023
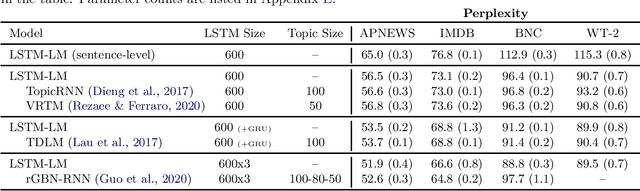

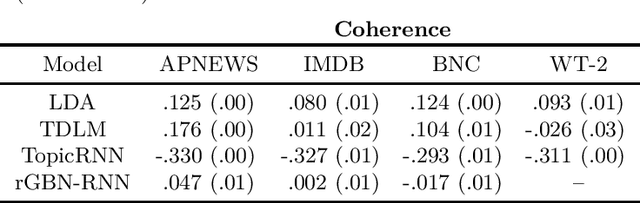
A recent line of work in natural language processing has aimed to combine language models and topic models. These topic-guided language models augment neural language models with topic models, unsupervised learning methods that can discover document-level patterns of word use. This paper compares the effectiveness of these methods in a standardized setting. We study four topic-guided language models and two baselines, evaluating the held-out predictive performance of each model on four corpora. Surprisingly, we find that none of these methods outperform a standard LSTM language model baseline, and most fail to learn good topics. Further, we train a probe of the neural language model that shows that the baseline's hidden states already encode topic information. We make public all code used for this study.
An Invariant Learning Characterization of Controlled Text Generation
May 31, 2023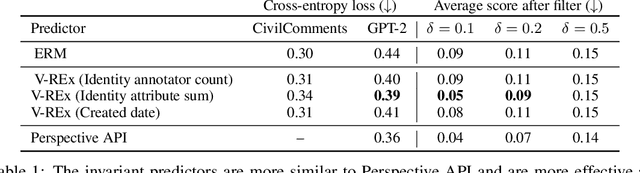
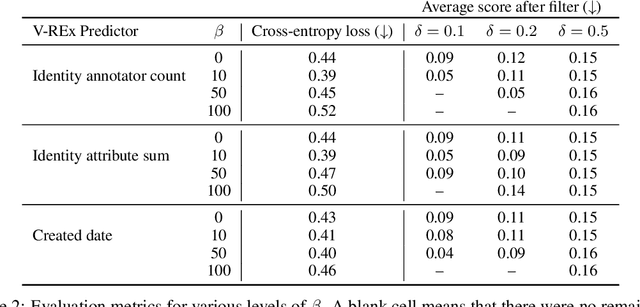
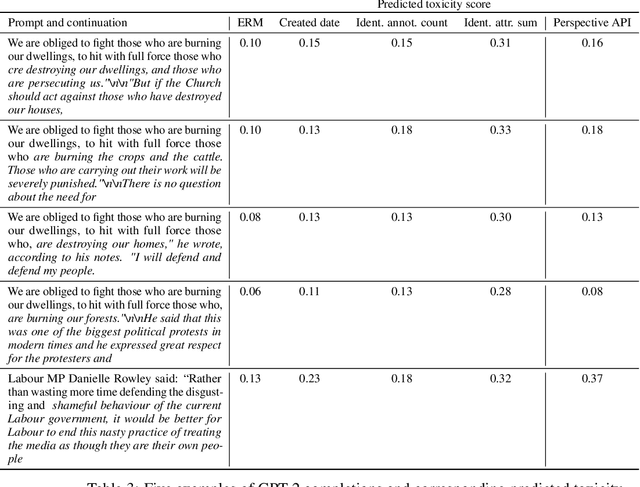
Controlled generation refers to the problem of creating text that contains stylistic or semantic attributes of interest. Many approaches reduce this problem to training a predictor of the desired attribute. For example, researchers hoping to deploy a large language model to produce non-toxic content may use a toxicity classifier to filter generated text. In practice, the generated text to classify, which is determined by user prompts, may come from a wide range of distributions. In this paper, we show that the performance of controlled generation may be poor if the distributions of text in response to user prompts differ from the distribution the predictor was trained on. To address this problem, we cast controlled generation under distribution shift as an invariant learning problem: the most effective predictor should be invariant across multiple text environments. We then discuss a natural solution that arises from this characterization and propose heuristics for selecting natural environments. We study this characterization and the proposed method empirically using both synthetic and real data. Experiments demonstrate both the challenge of distribution shift in controlled generation and the potential of invariance methods in this setting.
Learning Transferrable Representations of Career Trajectories for Economic Prediction
Mar 10, 2022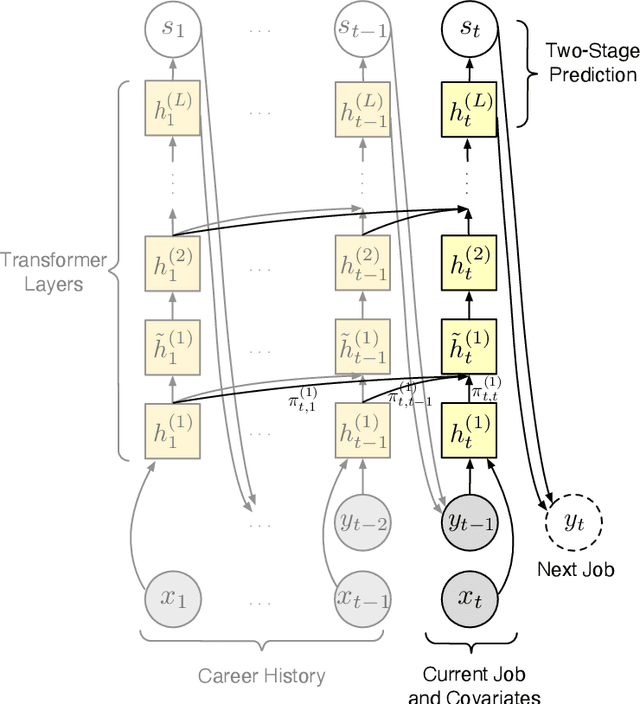
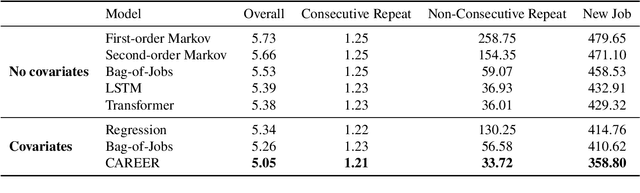

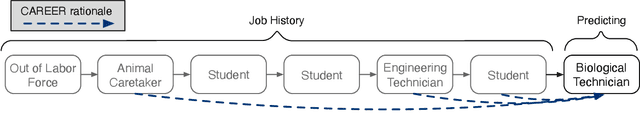
Understanding career trajectories -- the sequences of jobs that individuals hold over their working lives -- is important to economists for studying labor markets. In the past, economists have estimated relevant quantities by fitting predictive models to small surveys, but in recent years large datasets of online resumes have also become available. These new datasets provide job sequences of many more individuals, but they are too large and complex for standard econometric modeling. To this end, we adapt ideas from modern language modeling to the analysis of large-scale job sequence data. We develop CAREER, a transformer-based model that learns a low-dimensional representation of an individual's job history. This representation can be used to predict jobs directly on a large dataset, or can be "transferred" to represent jobs in smaller and better-curated datasets. We fit the model to a large dataset of resumes, 24 million people who are involved in more than a thousand unique occupations. It forms accurate predictions on held-out data, and it learns useful career representations that can be fine-tuned to make accurate predictions on common economics datasets.