 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Has a Foundation Model Found? Using Inductive Bias to Probe for World Models
Jul 09, 2025Foundation models are premised on the idea that sequence prediction can uncover deeper domain understanding, much like how Kepler's predictions of planetary motion later led to the discovery of Newtonian mechanics. However, evaluating whether these models truly capture deeper structure remains a challenge. We develop a technique for evaluating foundation models that examines how they adapt to synthetic datasets generated from some postulated world model. Our technique measures whether the foundation model's inductive bias aligns with the world model, and so we refer to it as an inductive bias probe. Across multiple domains, we find that foundation models can excel at their training tasks yet fail to develop inductive biases towards the underlying world model when adapted to new tasks. We particularly find that foundation models trained on orbital trajectories consistently fail to apply Newtonian mechanics when adapted to new physics tasks. Further analysis reveals that these models behave as if they develop task-specific heuristics that fail to generalize.
Potemkin Understanding in Large Language Models
Jun 26, 2025Large language models (LLMs) are regularly evaluated using benchmark datasets. But what justifies making inferences about an LLM's capabilities based on its answers to a curated set of questions? This paper first introduces a formal framework to address this question. The key is to note that the benchmarks used to test LLMs -- such as AP exams -- are also those used to test people. However, this raises an implication: these benchmarks are only valid tests if LLMs misunderstand concepts in ways that mirror human misunderstandings. Otherwise, success on benchmarks only demonstrates potemkin understanding: the illusion of understanding driven by answers irreconcilable with how any human would interpret a concept. We present two procedures for quantifying the existence of potemkins: one using a specially designed benchmark in three domains, the other using a general procedure that provides a lower-bound on their prevalence. We find that potemkins are ubiquitous across models, tasks, and domains. We also find that these failures reflect not just incorrect understanding, but deeper internal incoherence in concept representations.
Large Language Models: An Applied Econometric Framework
Dec 09, 2024



Large language models (LLMs) are being used in economics research to form predictions, label text, simulate human responses, generate hypotheses, and even produce data for times and places where such data don't exist. While these uses are creative, are they valid? When can we abstract away from the inner workings of an LLM and simply rely on their outputs? We develop an econometric framework to answer this question. Our framework distinguishes between two types of empirical tasks. Using LLM outputs for prediction problems (including hypothesis generation) is valid under one condition: no "leakage" between the LLM's training dataset and the researcher's sample. Using LLM outputs for estimation problems to automate the measurement of some economic concept (expressed by some text or from human subjects) requires an additional assumption: LLM outputs must be as good as the gold standard measurements they replace. Otherwise estimates can be biased, even if LLM outputs are highly accurate but not perfectly so. We document the extent to which these conditions are violated and the implications for research findings in illustrative applications to finance and political economy. We also provide guidance to empirical researchers. The only way to ensure no training leakage is to use open-source LLMs with documented training data and published weights. The only way to deal with LLM measurement error is to collect validation data and model the error structure. A corollary is that if such conditions can't be met for a candidate LLM application, our strong advice is: don't.
Evaluating the World Model Implicit in a Generative Model
Jun 06, 2024Recent work suggests that large language models may implicitly learn world models. How should we assess this possibility? We formalize this question for the case where the underlying reality is governed by a deterministic finite automaton. This includes problems as diverse as simple logical reasoning, geographic navigation, game-playing, and chemistry. We propose new evaluation metrics for world model recovery inspired by the classic Myhill-Nerode theorem from language theory. We illustrate their utility in three domains: game playing, logic puzzles, and navigation. In all domains, the generative models we consider do well on existing diagnostics for assessing world models, but our evaluation metrics reveal their world models to be far less coherent than they appear. Such incoherence creates fragility: using a generative model to solve related but subtly different tasks can lead it to fail badly. Building generative models that meaningfully capture the underlying logic of the domains they model would be immensely valuable; our results suggest new ways to assess how close a given model is to that goal.
Do Large Language Models Perform the Way People Expect? Measuring the Human Generalization Function
Jun 03, 2024What makes large language models (LLMs) impressive is also what makes them hard to evaluate: their diversity of uses. To evaluate these models, we must understand the purposes they will be used for. We consider a setting where these deployment decisions are made by people, and in particular, people's beliefs about where an LLM will perform well. We model such beliefs as the consequence of a human generalization function: having seen what an LLM gets right or wrong, people generalize to where else it might succeed. We collect a dataset of 19K examples of how humans make generalizations across 79 tasks from the MMLU and BIG-Bench benchmarks. We show that the human generalization function can be predicted using NLP methods: people have consistent structured ways to generalize. We then evaluate LLM alignment with the human generalization function. Our results show that -- especially for cases where the cost of mistakes is high -- more capable models (e.g. GPT-4) can do worse on the instances people choose to use them for, exactly because they are not aligned with the human generalization function.
Language Generation in the Limit
Apr 10, 2024Although current large language models are complex, the most basic specifications of the underlying language generation problem itself are simple to state: given a finite set of training samples from an unknown language, produce valid new strings from the language that don't already appear in the training data. Here we ask what we can conclude about language generation using only this specification, without further assumptions. In particular, suppose that an adversary enumerates the strings of an unknown target language L that is known only to come from one of a possibly infinite list of candidates. A computational agent is trying to learn to generate from this language; we say that the agent generates from L in the limit if after some finite point in the enumeration of L, the agent is able to produce new elements that come exclusively from L and that have not yet been presented by the adversary. Our main result is that there is an agent that is able to generate in the limit for every countable list of candidate languages. This contrasts dramatically with negative results due to Gold and Angluin in a well-studied model of language learning where the goal is to identify an unknown language from samples; the difference between these results suggests that identifying a language is a fundamentally different problem than generating from it.
Characterizing the Value of Information in Medical Notes
Oct 07, 2020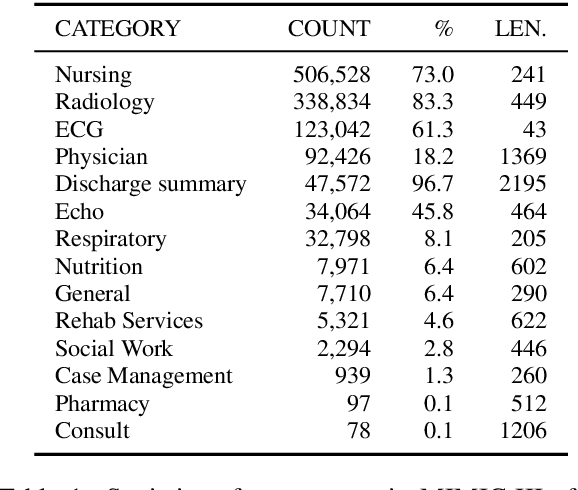
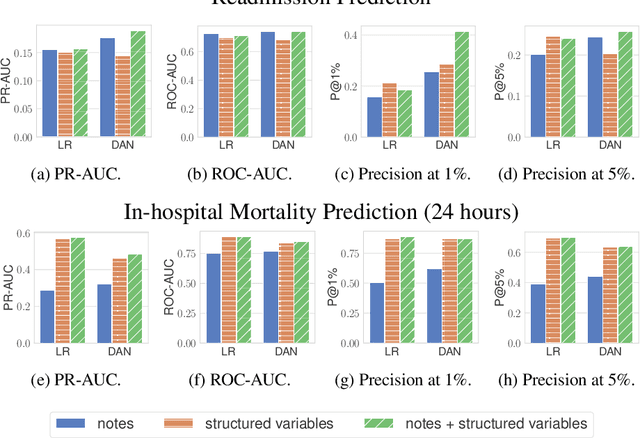

Machine learning models depend on the quality of input data. As electronic health records are widely adopted, the amount of data in health care is growing, along with complaints about the quality of medical notes. We use two prediction tasks, readmission prediction and in-hospital mortality prediction, to characterize the value of information in medical notes. We show that as a whole, medical notes only provide additional predictive power over structured information in readmission prediction. We further propose a probing framework to select parts of notes that enable more accurate predictions than using all notes, despite that the selected information leads to a distribution shift from the training data ("all notes"). Finally, we demonstrate that models trained on the selected valuable information achieve even better predictive performance, with only 6.8% of all the tokens for readmission prediction.
Quantifying the Causal Effects of Conversational Tendencies
Sep 08, 2020
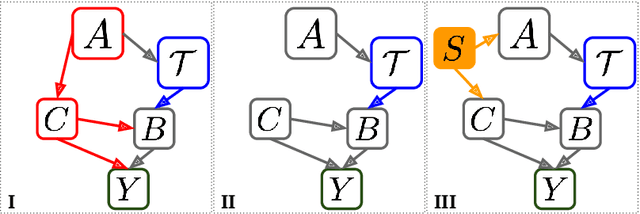
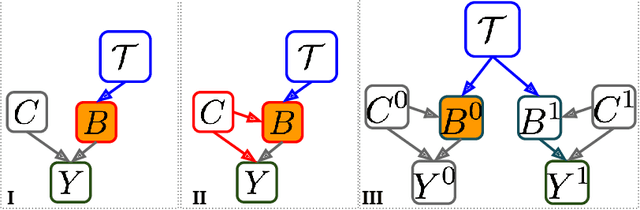
Understanding what leads to effective conversations can aid the design of better computer-mediated communication platforms. In particular, prior observational work has sought to identify behaviors of individuals that correlate to their conversational efficiency. However, translating such correlations to causal interpretations is a necessary step in using them in a prescriptive fashion to guide better designs and policies. In this work, we formally describe the problem of drawing causal links between conversational behaviors and outcomes. We focus on the task of determining a particular type of policy for a text-based crisis counseling platform: how best to allocate counselors based on their behavioral tendencies exhibited in their past conversations. We apply arguments derived from causal inference to underline key challenges that arise in conversational settings where randomized trials are hard to implement. Finally, we show how to circumvent these inference challenges in our particular domain, and illustrate the potential benefits of an allocation policy informed by the resulting prescriptive information.
Measuring the Completeness of Theories
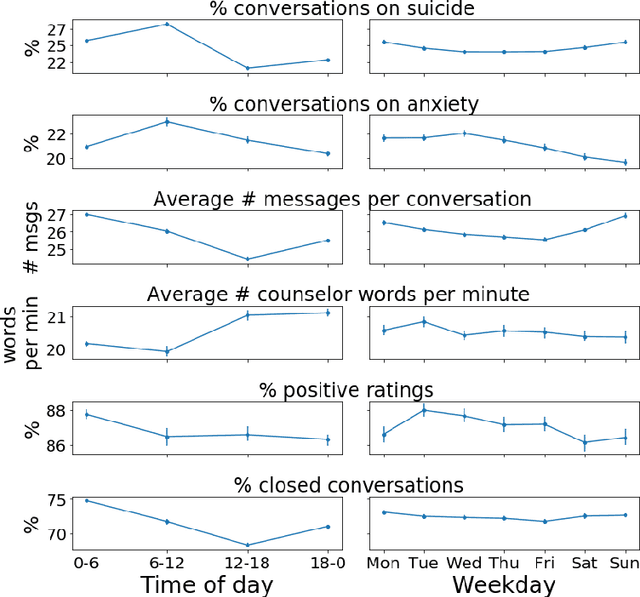
Oct 15, 2019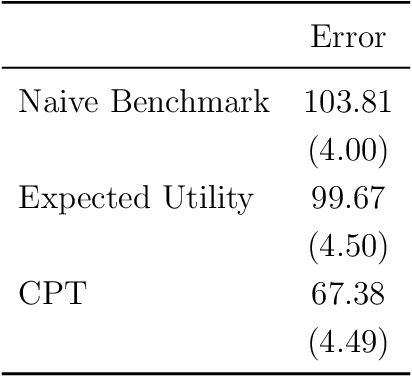
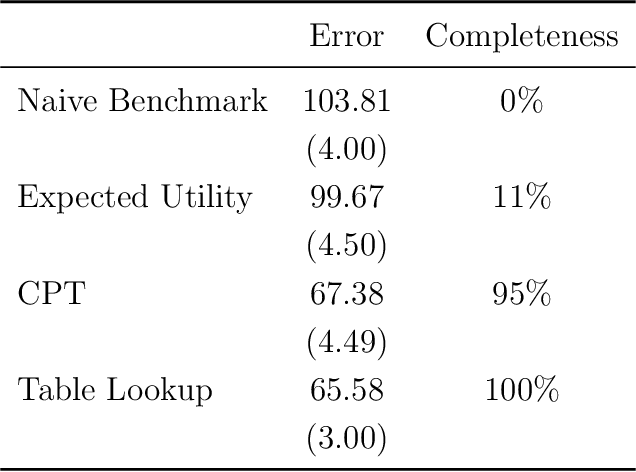

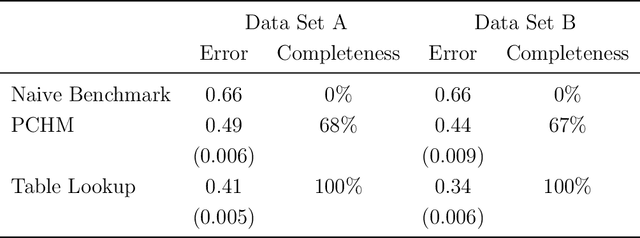
We use machine learning to provide a tractable measure of the amount of predictable variation in the data that a theory captures, which we call its "completeness." We apply this measure to three problems: assigning certain equivalents to lotteries, initial play in games, and human generation of random sequences. We discover considerable variation in the completeness of existing models, which sheds light on whether to focus on developing better models with the same features or instead to look for new features that will improve predictions. We also illustrate how and why completeness varies with the experiments considered, which highlights the role played in choosing which experiments to run.
The Algorithmic Automation Problem: Prediction, Triage, and Human Effort
Mar 28, 2019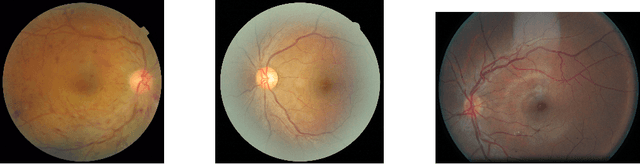
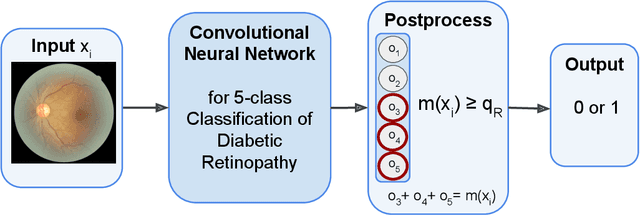
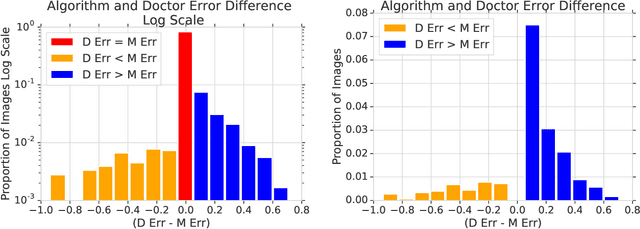
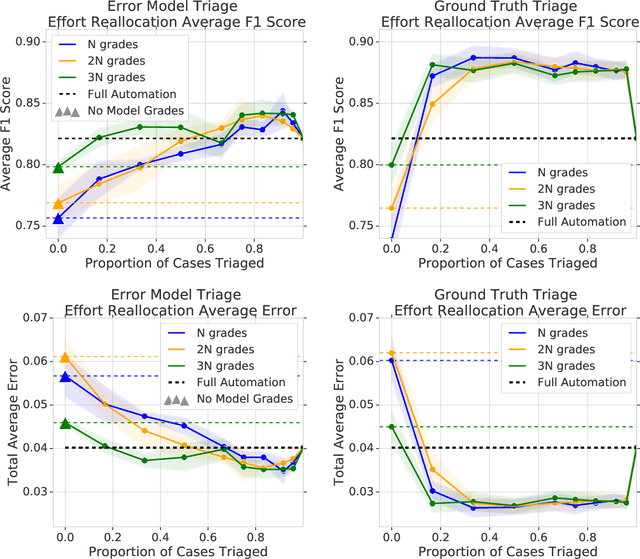
In a wide array of areas, algorithms are matching and surpassing the performance of human experts, leading to consideration of the roles of human judgment and algorithmic prediction in these domains. The discussion around these developments, however, has implicitly equated the specific task of prediction with the general task of automation. We argue here that automation is broader than just a comparison of human versus algorithmic performance on a task; it also involves the decision of which instances of the task to give to the algorithm in the first place. We develop a general framework that poses this latter decision as an optimization problem, and we show how basic heuristics for this optimization problem can lead to performance gains even on heavily-studied applications of AI in medicine. Our framework also serves to highlight how effective automation depends crucially on estimating both algorithmic and human error on an instance-by-instance basis, and our results show how improvements in these error estimation problems can yield significant gains for automation as well.