 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing the Value of Information in Medical Notes
Paper and Code
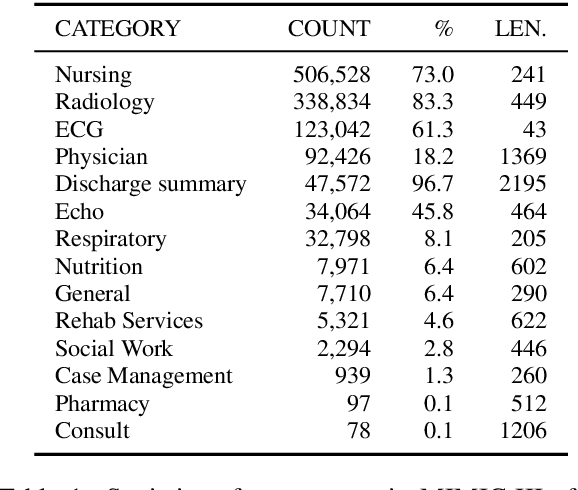
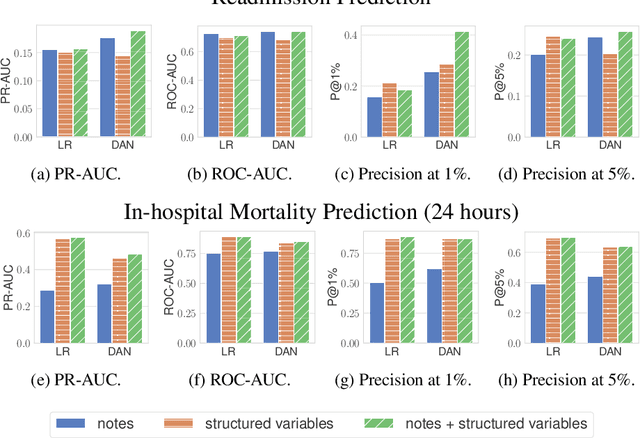

Machine learning models depend on the quality of input data. As electronic health records are widely adopted, the amount of data in health care is growing, along with complaints about the quality of medical notes. We use two prediction tasks, readmission prediction and in-hospital mortality prediction, to characterize the value of information in medical notes. We show that as a whole, medical notes only provide additional predictive power over structured information in readmission prediction. We further propose a probing framework to select parts of notes that enable more accurate predictions than using all notes, despite that the selected information leads to a distribution shift from the training data ("all notes"). Finally, we demonstrate that models trained on the selected valuable information achieve even better predictive performance, with only 6.8% of all the tokens for readmission prediction.