 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHIME: LLM-Assisted Hierarchical Organization of Scientific Studies for Literature Review Support
Jul 23, 2024



Literature review requires researchers to synthesize a large amount of information and is increasingly challenging as the scientific literature expands. In this work, we investigate the potential of LLMs for producing hierarchical organizations of scientific studies to assist researchers with literature review. We define hierarchical organizations as tree structures where nodes refer to topical categories and every node is linked to the studies assigned to that category. Our naive LLM-based pipeline for hierarchy generation from a set of studies produces promising yet imperfect hierarchies, motivating us to collect CHIME, an expert-curated dataset for this task focused on biomedicine. Given the challenging and time-consuming nature of building hierarchies from scratch, we use a human-in-the-loop process in which experts correct errors (both links between categories and study assignment) in LLM-generated hierarchies. CHIME contains 2,174 LLM-generated hierarchies covering 472 topics, and expert-corrected hierarchies for a subset of 100 topics. Expert corrections allow us to quantify LLM performance, and we find that while they are quite good at generating and organizing categories, their assignment of studies to categories could be improved. We attempt to train a corrector model with human feedback which improves study assignment by 12.6 F1 points. We release our dataset and models to encourage research on developing better assistive tools for literature review.
Clinical Notes Reveal Physician Fatigue
Dec 05, 2023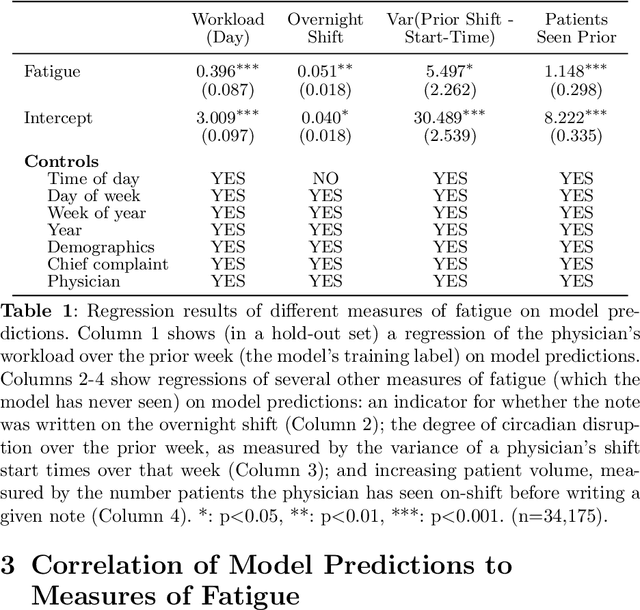
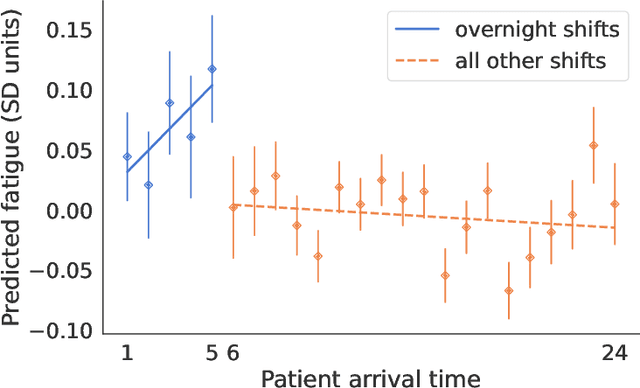
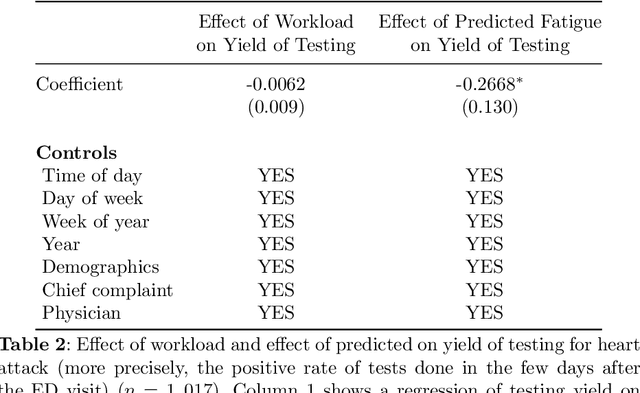
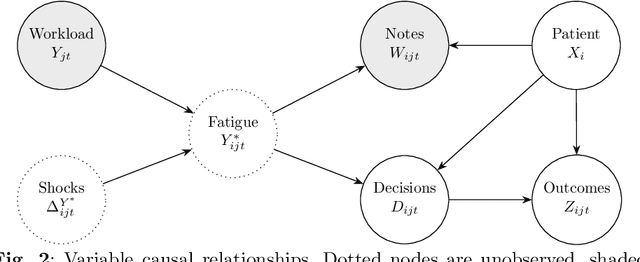
Physicians write notes about patients. In doing so, they reveal much about themselves. Using data from 129,228 emergency room visits, we train a model to identify notes written by fatigued physicians -- those who worked 5 or more of the prior 7 days. In a hold-out set, the model accurately identifies notes written by these high-workload physicians, and also flags notes written in other high-fatigue settings: on overnight shifts, and after high patient volumes. Model predictions also correlate with worse decision-making on at least one important metric: yield of testing for heart attack is 18% lower with each standard deviation increase in model-predicted fatigue. Finally, the model indicates that notes written about Black and Hispanic patients have 12% and 21% higher predicted fatigue than Whites -- larger than overnight vs. daytime differences. These results have an important implication for large language models (LLMs). Our model indicates that fatigued doctors write more predictable notes. Perhaps unsurprisingly, because word prediction is the core of how LLMs work, we find that LLM-written notes have 17% higher predicted fatigue than real physicians' notes. This indicates that LLMs may introduce distortions in generated text that are not yet fully understood.
Decision-Focused Summarization
Sep 14, 2021



Relevance in summarization is typically defined based on textual information alone, without incorporating insights about a particular decision. As a result, to support risk analysis of pancreatic cancer, summaries of medical notes may include irrelevant information such as a knee injury. We propose a novel problem, decision-focused summarization, where the goal is to summarize relevant information for a decision. We leverage a predictive model that makes the decision based on the full text to provide valuable insights on how a decision can be inferred from text. To build a summary, we then select representative sentences that lead to similar model decisions as using the full text while accounting for textual non-redundancy. To evaluate our method (DecSum), we build a testbed where the task is to summarize the first ten reviews of a restaurant in support of predicting its future rating on Yelp. DecSum substantially outperforms text-only summarization methods and model-based explanation methods in decision faithfulness and representativeness. We further demonstrate that DecSum is the only method that enables humans to outperform random chance in predicting which restaurant will be better rated in the future.
Answer Generation for Retrieval-based Question Answering Systems
Jun 02, 2021
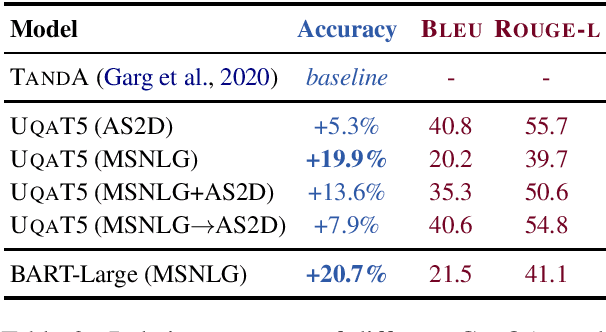
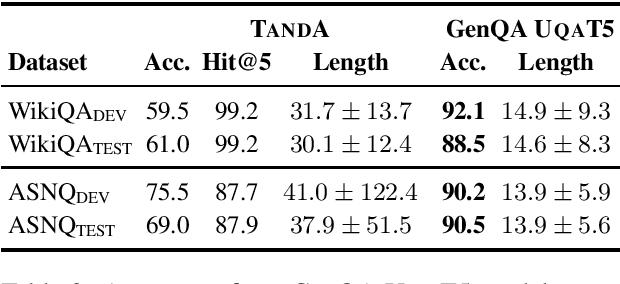
Recent advancements in transformer-based models have greatly improved the ability of Question Answering (QA) systems to provide correct answers; in particular, answer sentence selection (AS2) models, core components of retrieval-based systems, have achieved impressive results. While generally effective, these models fail to provide a satisfying answer when all retrieved candidates are of poor quality, even if they contain correct information. In AS2, models are trained to select the best answer sentence among a set of candidates retrieved for a given question. In this work, we propose to generate answers from a set of AS2 top candidates. Rather than selecting the best candidate, we train a sequence to sequence transformer model to generate an answer from a candidate set. Our tests on three English AS2 datasets show improvement up to 32 absolute points in accuracy over the state of the art.
Cross-Modal Contrastive Learning of Representations for Navigation using Lightweight, Low-Cost Millimeter Wave Radar for Adverse Environmental Conditions
Jan 10, 2021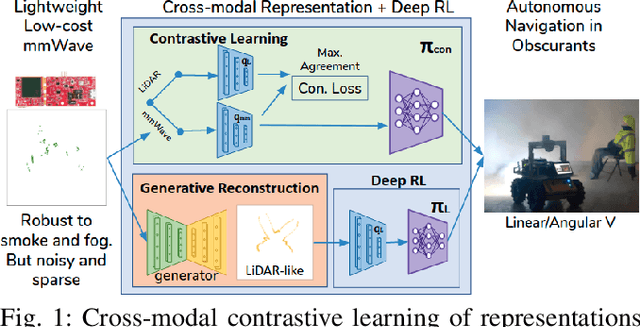
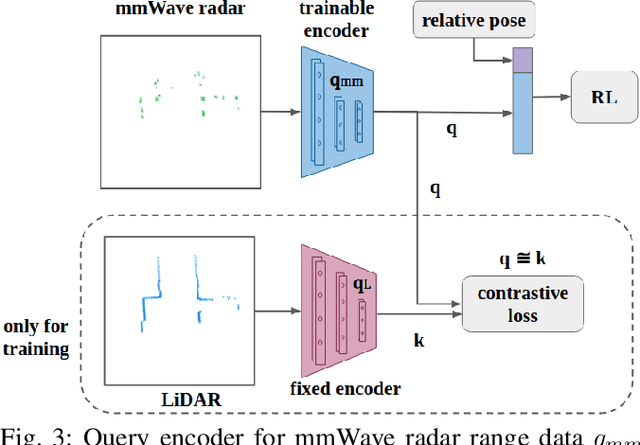
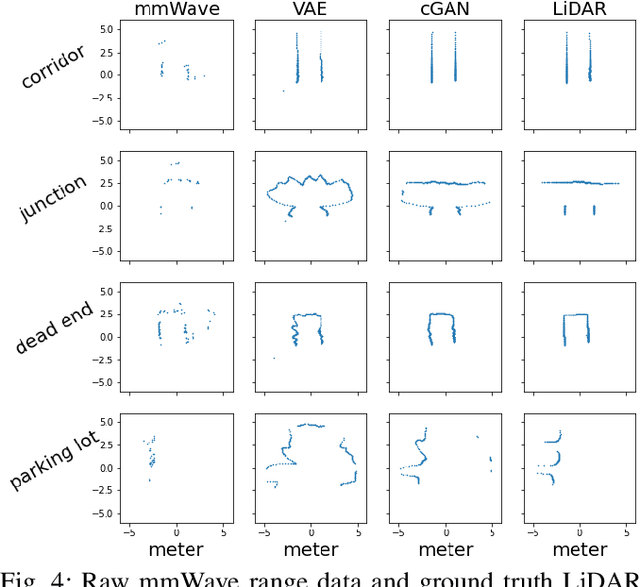
Deep reinforcement learning (RL), where the agent learns from mistakes, has been successfully applied to a variety of tasks. With the aim of learning collision-free policies for unmanned vehicles, deep RL has been used for training with various types of data, such as colored images, depth images, and LiDAR point clouds, without the use of classic map--localize--plan approaches. However, existing methods are limited by their reliance on cameras and LiDAR devices, which have degraded sensing under adverse environmental conditions (e.g., smoky environments). In response, we propose the use of single-chip millimeter-wave (mmWave) radar, which is lightweight and inexpensive, for learning-based autonomous navigation. However, because mmWave radar signals are often noisy and sparse, we propose a cross-modal contrastive learning for representation (CM-CLR) method that maximizes the agreement between mmWave radar data and LiDAR data in the training stage. We evaluated our method in real-world robot compared with 1) a method with two separate networks using cross-modal generative reconstruction and an RL policy and 2) a baseline RL policy without cross-modal representation. Our proposed end-to-end deep RL policy with contrastive learning successfully navigated the robot through smoke-filled maze environments and achieved better performance compared with generative reconstruction methods, in which noisy artifact walls or obstacles were produced. All pretrained models and hardware settings are open access for reproducing this study and can be obtained at https://arg-nctu.github.io/projects/deeprl-mmWave.html
Characterizing the Value of Information in Medical Notes
Oct 07, 2020
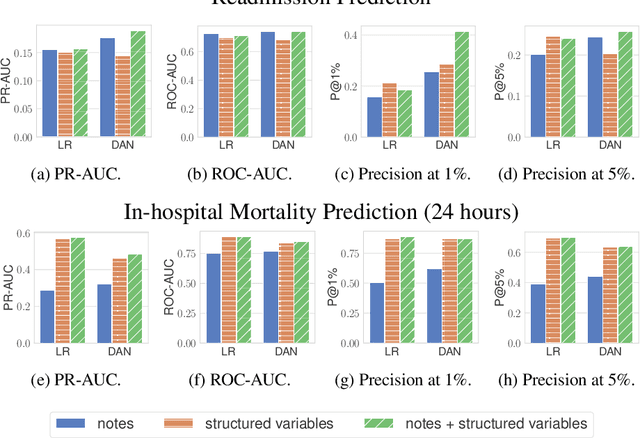

Machine learning models depend on the quality of input data. As electronic health records are widely adopted, the amount of data in health care is growing, along with complaints about the quality of medical notes. We use two prediction tasks, readmission prediction and in-hospital mortality prediction, to characterize the value of information in medical notes. We show that as a whole, medical notes only provide additional predictive power over structured information in readmission prediction. We further propose a probing framework to select parts of notes that enable more accurate predictions than using all notes, despite that the selected information leads to a distribution shift from the training data ("all notes"). Finally, we demonstrate that models trained on the selected valuable information achieve even better predictive performance, with only 6.8% of all the tokens for readmission prediction.
Multi-step Joint-Modality Attention Network for Scene-Aware Dialogue System
Jan 17, 2020
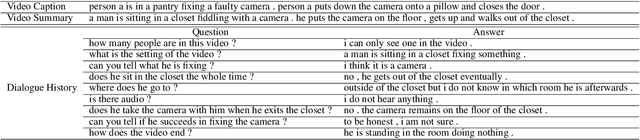

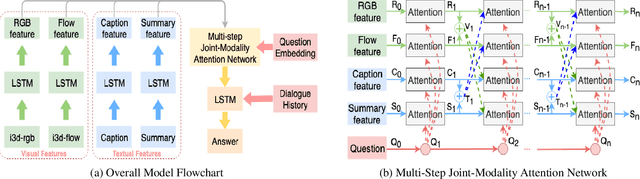
Understanding dynamic scenes and dialogue contexts in order to converse with users has been challenging for multimodal dialogue systems. The 8-th Dialog System Technology Challenge (DSTC8) proposed an Audio Visual Scene-Aware Dialog (AVSD) task, which contains multiple modalities including audio, vision, and language, to evaluate how dialogue systems understand different modalities and response to users. In this paper, we proposed a multi-step joint-modality attention network (JMAN) based on recurrent neural network (RNN) to reason on videos. Our model performs a multi-step attention mechanism and jointly considers both visual and textual representations in each reasoning process to better integrate information from the two different modalities. Compared to the baseline released by AVSD organizers, our model achieves a relative 12.1% and 22.4% improvement over the baseline on ROUGE-L score and CIDEr score.
Knowledge-Enriched Visual Storytelling
Dec 03, 2019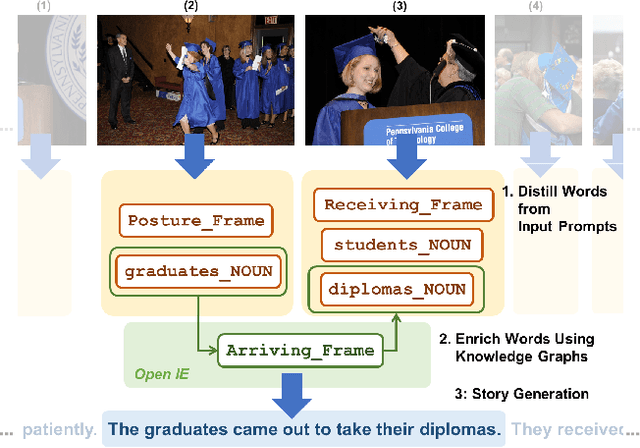



Stories are diverse and highly personalized, resulting in a large possible output space for story generation. Existing end-to-end approaches produce monotonous stories because they are limited to the vocabulary and knowledge in a single training dataset. This paper introduces KG-Story, a three-stage framework that allows the story generation model to take advantage of external Knowledge Graphs to produce interesting stories. KG-Story distills a set of representative words from the input prompts, enriches the word set by using external knowledge graphs, and finally generates stories based on the enriched word set. This distill-enrich-generate framework allows the use of external resources not only for the enrichment phase, but also for the distillation and generation phases. In this paper, we show the superiority of KG-Story for visual storytelling, where the input prompt is a sequence of five photos and the output is a short story. Per the human ranking evaluation, stories generated by KG-Story are on average ranked better than that of the state-of-the-art systems. Our code and output stories are available at https://github.com/zychen423/KE-VIST.
Team NCTU: Toward AI-Driving for Autonomous Surface Vehicles -- From Duckietown to RobotX
Oct 31, 2019



Robotic software and hardware systems of autonomous surface vehicles have been developed in transportation, military, and ocean researches for decades. Previous efforts in RobotX Challenges 2014 and 2016 facilitates the developments for important tasks such as obstacle avoidance and docking. Team NCTU is motivated by the AI Driving Olympics (AI-DO) developed by the Duckietown community, and adopts the principles to RobotX challenge. With the containerization (Docker) and uniformed AI agent (with observations and actions), we could better 1) integrate solutions developed in different middlewares (ROS and MOOS), 2) develop essential functionalities of from simulation (Gazebo) to real robots (either miniaturized or full-sized WAM-V), and 3) compare different approaches either from classic model-based or learning-based. Finally, we setup an outdoor on-surface platform with localization services for evaluation. Some of the preliminary results will be presented for the Team NCTU participations of the RobotX competition in Hawaii in 2018.
Entropy-Enhanced Multimodal Attention Model for Scene-Aware Dialogue Generation
Aug 22, 2019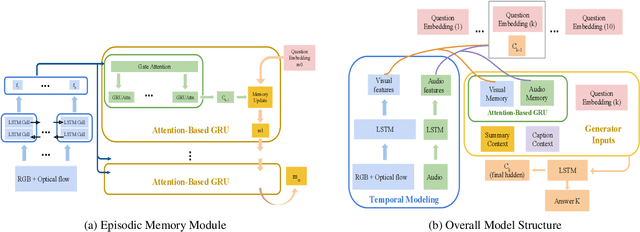
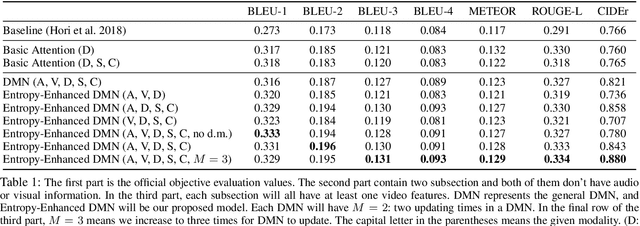

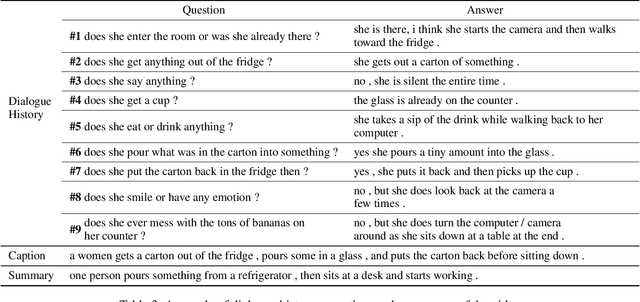
With increasing information from social media, there are more and more videos available. Therefore, the ability to reason on a video is important and deserves to be discussed. TheDialog System Technology Challenge (DSTC7) (Yoshino et al. 2018) proposed an Audio Visual Scene-aware Dialog (AVSD) task, which contains five modalities including video, dialogue history, summary, and caption, as a scene-aware environment. In this paper, we propose the entropy-enhanced dynamic memory network (DMN) to effectively model video modality. The attention-based GRU in the proposed model can improve the model's ability to comprehend and memorize sequential information. The entropy mechanism can control the attention distribution higher, so each to-be-answered question can focus more specifically on a small set of video segments. After the entropy-enhanced DMN secures the video context, we apply an attention model that in-corporates summary and caption to generate an accurate answer given the question about the video. In the official evaluation, our system can achieve improved performance against the released baseline model for both subjective and objective evaluation metrics.