 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinical Notes Reveal Physician Fatigue
Dec 05, 2023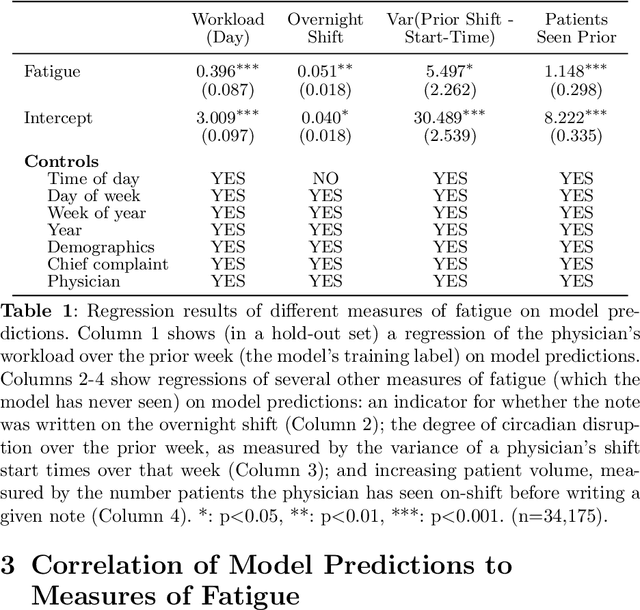
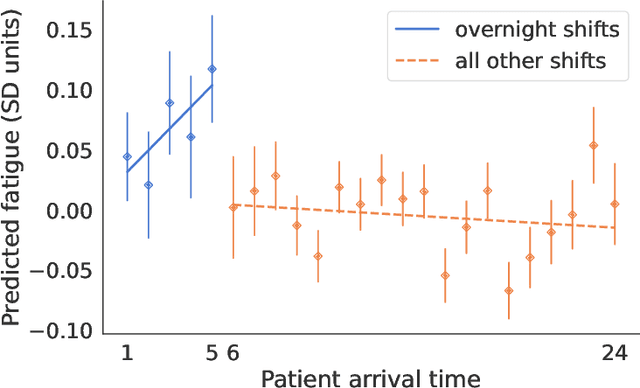
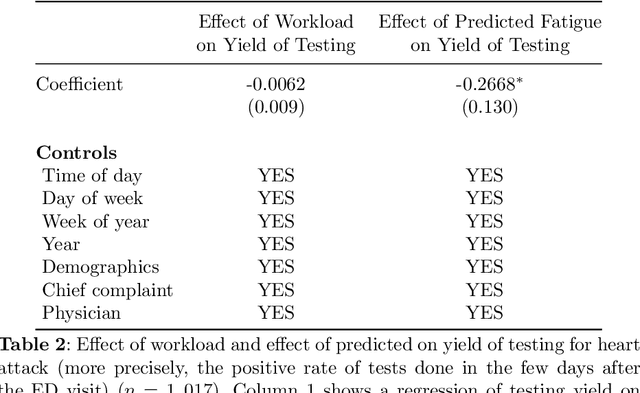
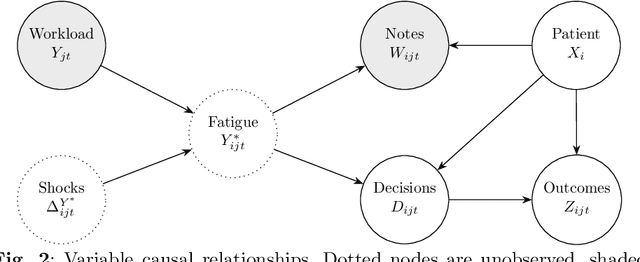
Physicians write notes about patients. In doing so, they reveal much about themselves. Using data from 129,228 emergency room visits, we train a model to identify notes written by fatigued physicians -- those who worked 5 or more of the prior 7 days. In a hold-out set, the model accurately identifies notes written by these high-workload physicians, and also flags notes written in other high-fatigue settings: on overnight shifts, and after high patient volumes. Model predictions also correlate with worse decision-making on at least one important metric: yield of testing for heart attack is 18% lower with each standard deviation increase in model-predicted fatigue. Finally, the model indicates that notes written about Black and Hispanic patients have 12% and 21% higher predicted fatigue than Whites -- larger than overnight vs. daytime differences. These results have an important implication for large language models (LLMs). Our model indicates that fatigued doctors write more predictable notes. Perhaps unsurprisingly, because word prediction is the core of how LLMs work, we find that LLM-written notes have 17% higher predicted fatigue than real physicians' notes. This indicates that LLMs may introduce distortions in generated text that are not yet fully understood.
Characterizing the Value of Information in Medical Notes
Oct 07, 2020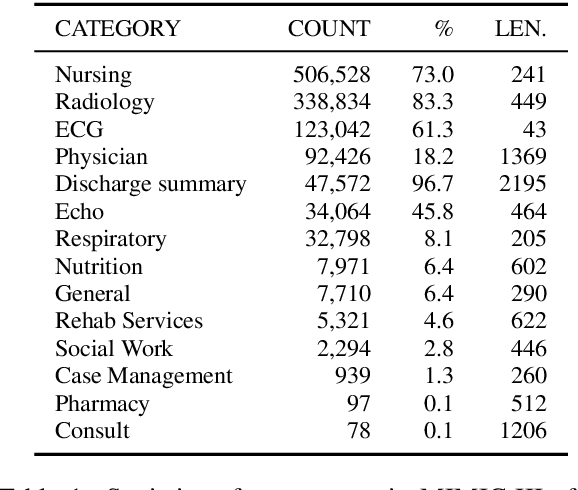
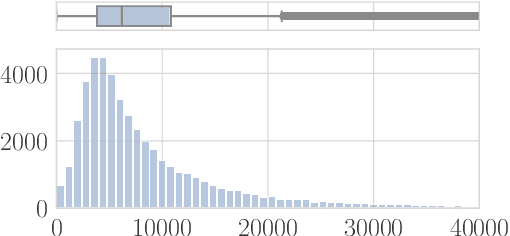
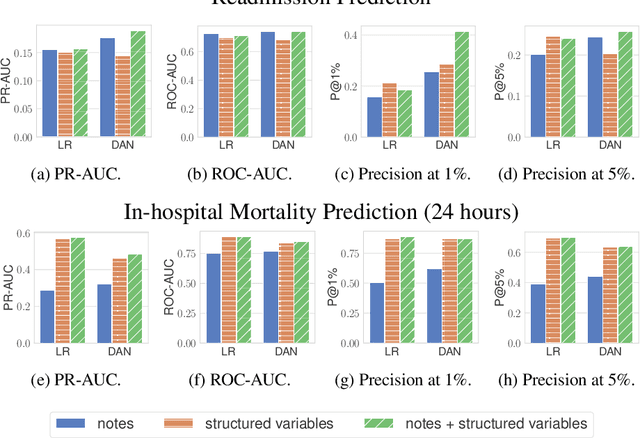

Machine learning models depend on the quality of input data. As electronic health records are widely adopted, the amount of data in health care is growing, along with complaints about the quality of medical notes. We use two prediction tasks, readmission prediction and in-hospital mortality prediction, to characterize the value of information in medical notes. We show that as a whole, medical notes only provide additional predictive power over structured information in readmission prediction. We further propose a probing framework to select parts of notes that enable more accurate predictions than using all notes, despite that the selected information leads to a distribution shift from the training data ("all notes"). Finally, we demonstrate that models trained on the selected valuable information achieve even better predictive performance, with only 6.8% of all the tokens for readmission prediction.
The Algorithmic Automation Problem: Prediction, Triage, and Human Effort
Mar 28, 2019
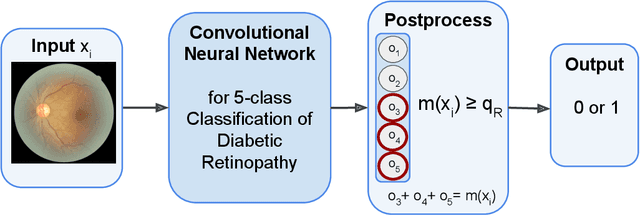
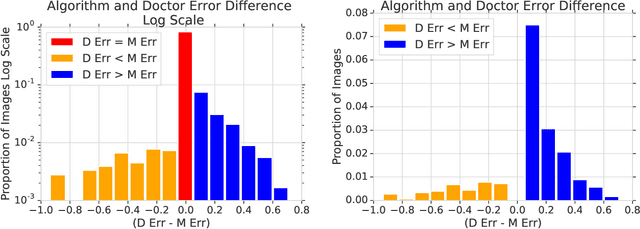
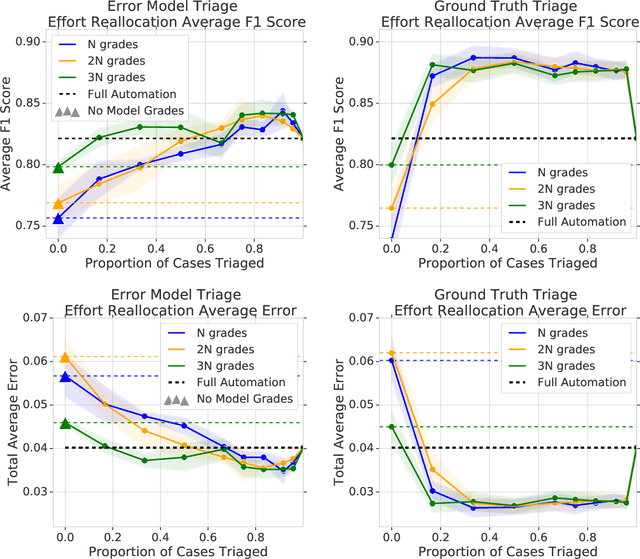
In a wide array of areas, algorithms are matching and surpassing the performance of human experts, leading to consideration of the roles of human judgment and algorithmic prediction in these domains. The discussion around these developments, however, has implicitly equated the specific task of prediction with the general task of automation. We argue here that automation is broader than just a comparison of human versus algorithmic performance on a task; it also involves the decision of which instances of the task to give to the algorithm in the first place. We develop a general framework that poses this latter decision as an optimization problem, and we show how basic heuristics for this optimization problem can lead to performance gains even on heavily-studied applications of AI in medicine. Our framework also serves to highlight how effective automation depends crucially on estimating both algorithmic and human error on an instance-by-instance basis, and our results show how improvements in these error estimation problems can yield significant gains for automation as well.
Measuring the Stability of EHR- and EKG-based Predictive Models
Dec 01, 2018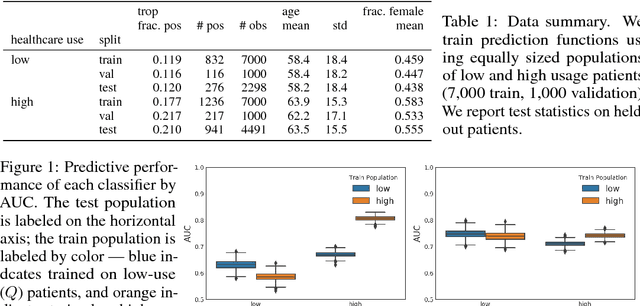
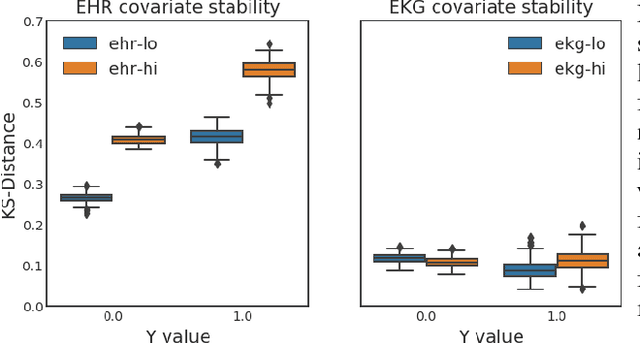
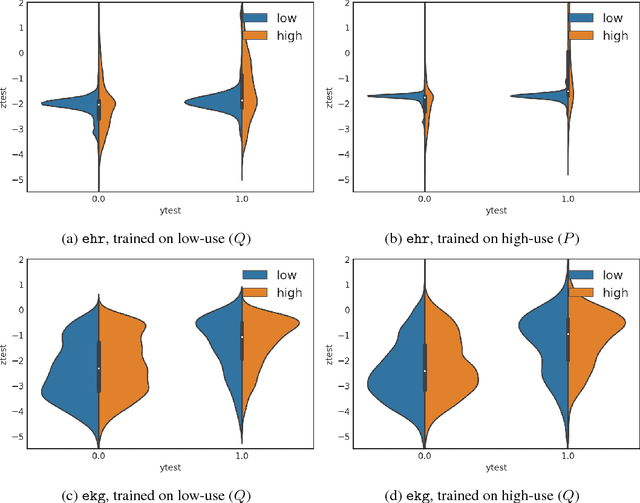
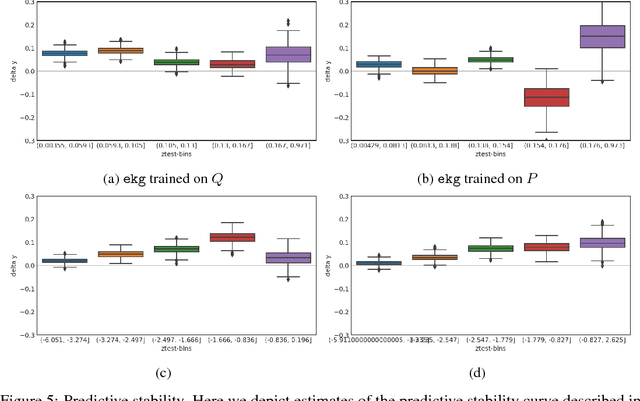
Databases of electronic health records (EHRs) are increasingly used to inform clinical decisions. Machine learning methods can find patterns in EHRs that are predictive of future adverse outcomes. However, statistical models may be built upon patterns of health-seeking behavior that vary across patient subpopulations, leading to poor predictive performance when training on one patient population and predicting on another. This note proposes two tests to better measure and understand model generalization. We use these tests to compare models derived from two data sources: (i) historical medical records, and (ii) electrocardiogram (EKG) waveforms. In a predictive task, we show that EKG-based models can be more stable than EHR-based models across different patient populations.
A Probabilistic Model of Cardiac Physiology and Electrocardiograms
Dec 01, 2018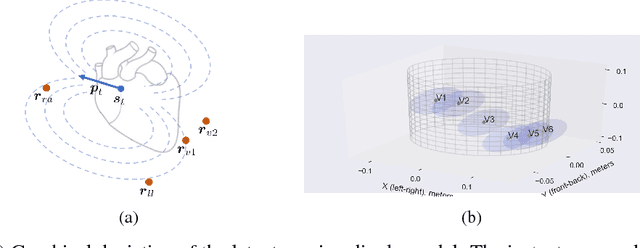
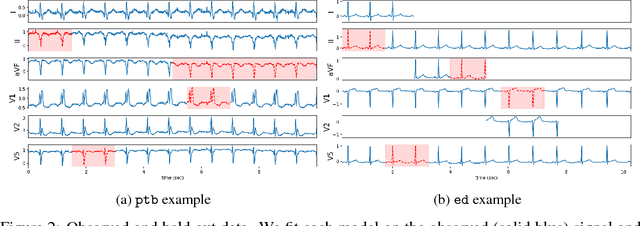
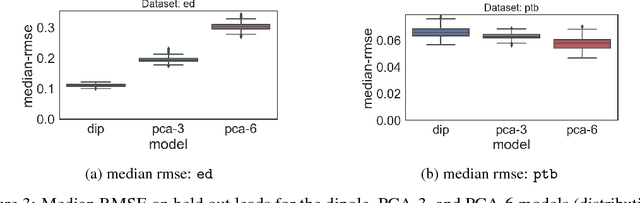
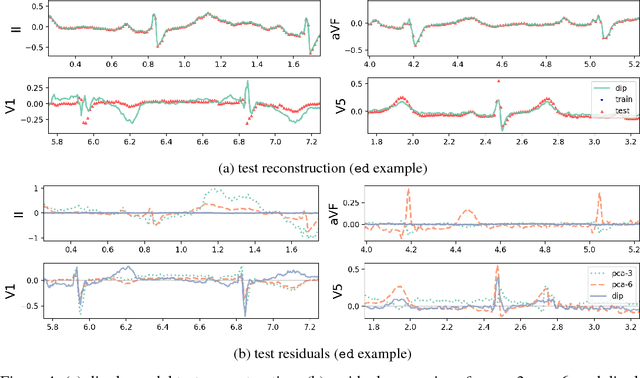
An electrocardiogram (EKG) is a common, non-invasive test that measures the electrical activity of a patient's heart. EKGs contain useful diagnostic information about patient health that may be absent from other electronic health record (EHR) data. As multi-dimensional waveforms, they could be modeled using generic machine learning tools, such as a linear factor model or a variational autoencoder. We take a different approach:~we specify a model that directly represents the underlying electrophysiology of the heart and the EKG measurement process. We apply our model to two datasets, including a sample of emergency department EKG reports with missing data. We show that our model can more accurately reconstruct missing data (measured by test reconstruction error) than a standard baseline when there is significant missing data. More broadly, this physiological representation of heart function may be useful in a variety of settings, including prediction, causal analysis, and discovery.
Direct Uncertainty Prediction for Medical Second Opinions
Sep 13, 2018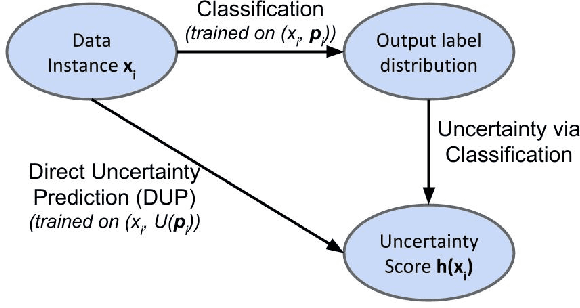

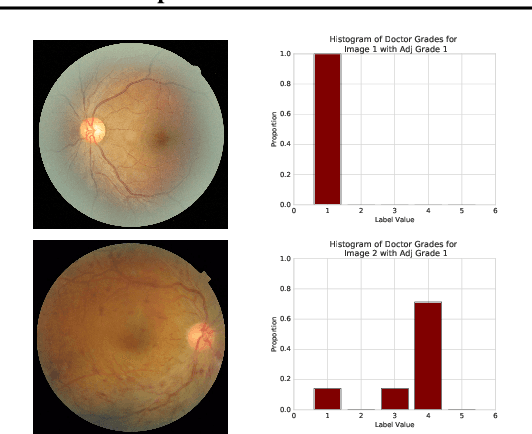

A persistent challenge in the practice of medicine (and machine learning) is the disagreement of highly trained human experts on data instances, such as patient image scans. We study the application of machine learning to predict which instances are likely to give rise to maximal expert disagreement. As necessitated by this, we develop predictors on datasets with noisy and scarce labels. Our central methodological finding is that direct prediction of a scalar uncertainty score performs better than the two-step process of (i) training a classifier (ii) using the classifier outputs to derive an uncertainty score. This is seen in both a synthetic setting whose parameters we can control, and a paradigmatic healthcare application involving multiple labels by medical domain experts. We evaluate these direct uncertainty models on a gold standard adjudicated set, where they accurately predict when an individual expert will disagree with an unknown ground truth. We explore the consequences for using these predictors to identify the need for a medical second opinion and a machine learning data curation application.
Short-term Mortality Prediction for Elderly Patients Using Medicare Claims Data
Dec 02, 2017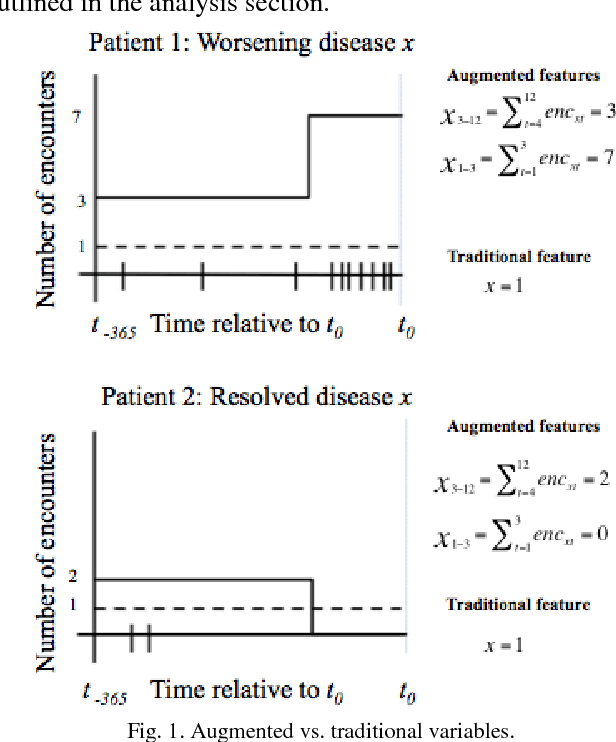
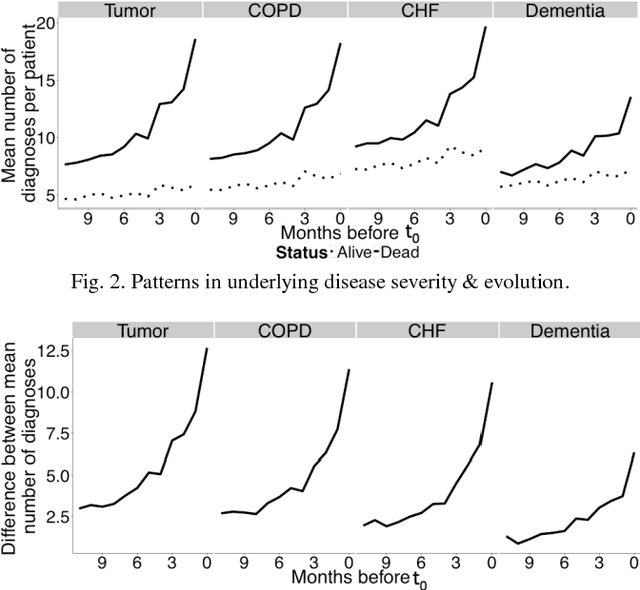
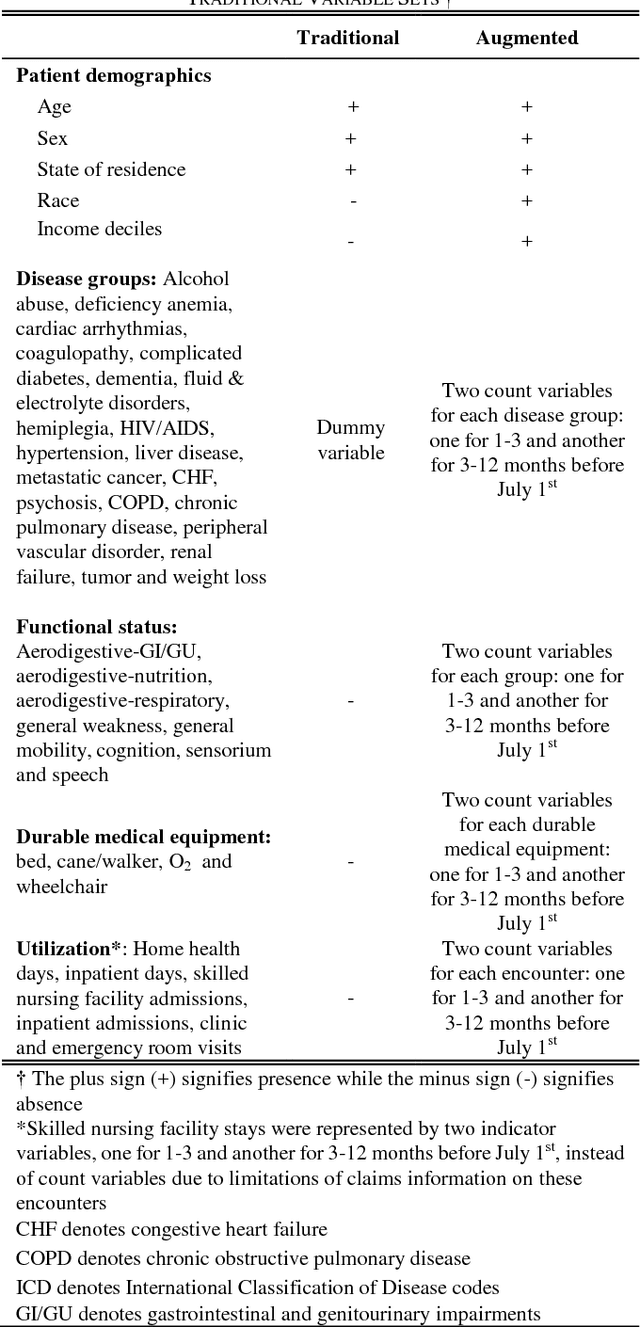
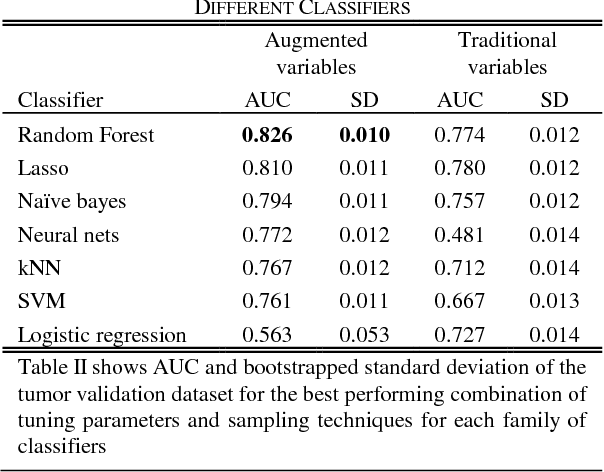
Risk prediction is central to both clinical medicine and public health. While many machine learning models have been developed to predict mortality, they are rarely applied in the clinical literature, where classification tasks typically rely on logistic regression. One reason for this is that existing machine learning models often seek to optimize predictions by incorporating features that are not present in the databases readily available to providers and policy makers, limiting generalizability and implementation. Here we tested a number of machine learning classifiers for prediction of six-month mortality in a population of elderly Medicare beneficiaries, using an administrative claims database of the kind available to the majority of health care payers and providers. We show that machine learning classifiers substantially outperform current widely-used methods of risk prediction but only when used with an improved feature set incorporating insights from clinical medicine, developed for this study. Our work has applications to supporting patient and provider decision making at the end of life, as well as population health-oriented efforts to identify patients at high risk of poor outcomes.