 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing a Cross-Task Grid of Linear Probes to Interpret CNN Model Predictions On Retinal Images
Jul 23, 2021
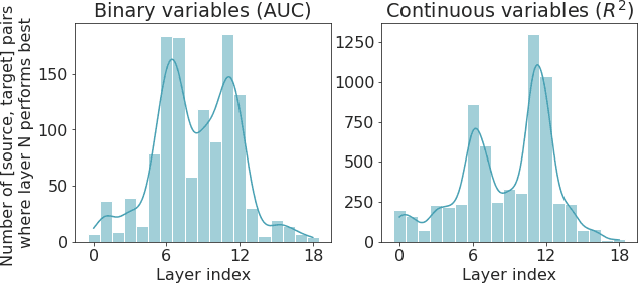


We analyze a dataset of retinal images using linear probes: linear regression models trained on some "target" task, using embeddings from a deep convolutional (CNN) model trained on some "source" task as input. We use this method across all possible pairings of 93 tasks in the UK Biobank dataset of retinal images, leading to ~164k different models. We analyze the performance of these linear probes by source and target task and by layer depth. We observe that representations from the middle layers of the network are more generalizable. We find that some target tasks are easily predicted irrespective of the source task, and that some other target tasks are more accurately predicted from correlated source tasks than from embeddings trained on the same task.
The Algorithmic Automation Problem: Prediction, Triage, and Human Effort
Mar 28, 2019
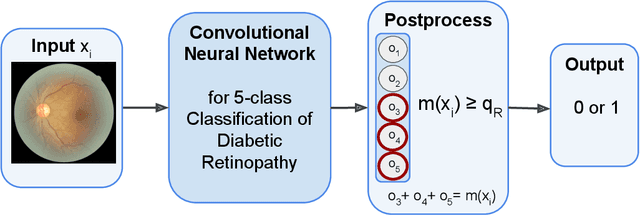
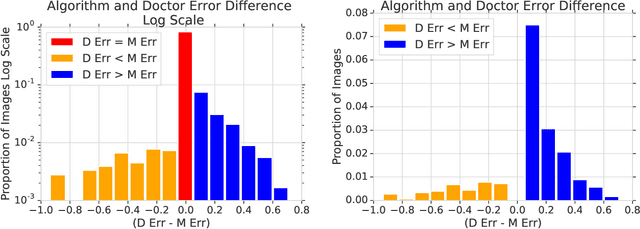
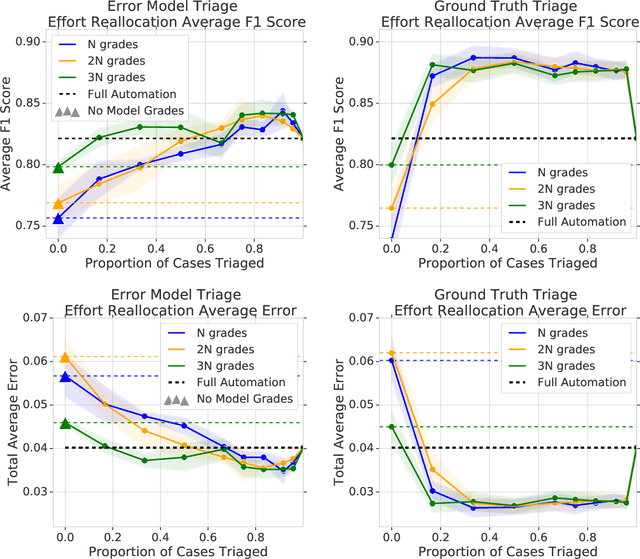
In a wide array of areas, algorithms are matching and surpassing the performance of human experts, leading to consideration of the roles of human judgment and algorithmic prediction in these domains. The discussion around these developments, however, has implicitly equated the specific task of prediction with the general task of automation. We argue here that automation is broader than just a comparison of human versus algorithmic performance on a task; it also involves the decision of which instances of the task to give to the algorithm in the first place. We develop a general framework that poses this latter decision as an optimization problem, and we show how basic heuristics for this optimization problem can lead to performance gains even on heavily-studied applications of AI in medicine. Our framework also serves to highlight how effective automation depends crucially on estimating both algorithmic and human error on an instance-by-instance basis, and our results show how improvements in these error estimation problems can yield significant gains for automation as well.
Direct Uncertainty Prediction for Medical Second Opinions
Sep 13, 2018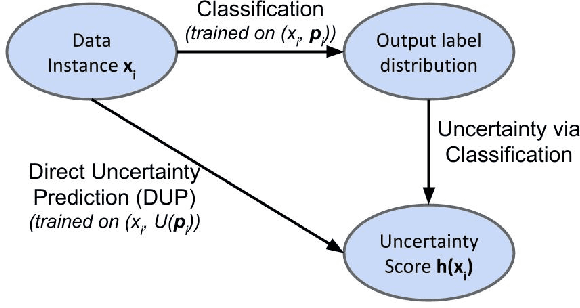

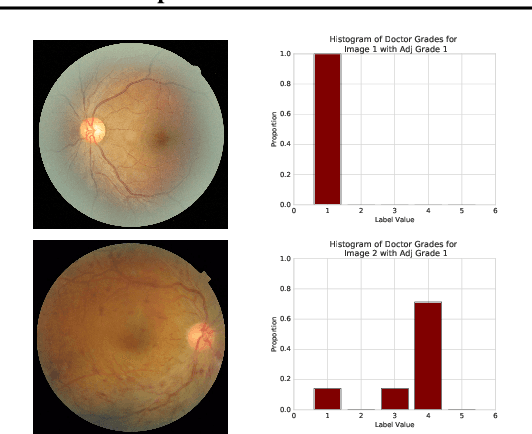

A persistent challenge in the practice of medicine (and machine learning) is the disagreement of highly trained human experts on data instances, such as patient image scans. We study the application of machine learning to predict which instances are likely to give rise to maximal expert disagreement. As necessitated by this, we develop predictors on datasets with noisy and scarce labels. Our central methodological finding is that direct prediction of a scalar uncertainty score performs better than the two-step process of (i) training a classifier (ii) using the classifier outputs to derive an uncertainty score. This is seen in both a synthetic setting whose parameters we can control, and a paradigmatic healthcare application involving multiple labels by medical domain experts. We evaluate these direct uncertainty models on a gold standard adjudicated set, where they accurately predict when an individual expert will disagree with an unknown ground truth. We explore the consequences for using these predictors to identify the need for a medical second opinion and a machine learning data curation application.
Deep learning for predicting refractive error from retinal fundus images
Dec 21, 2017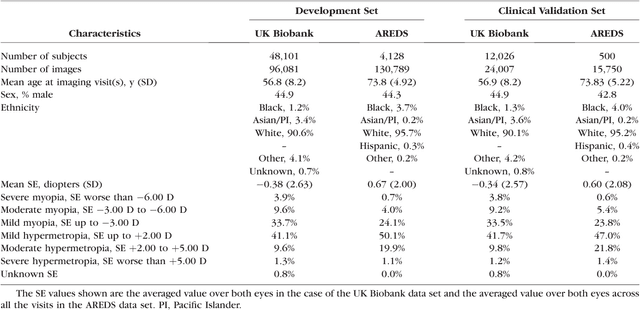
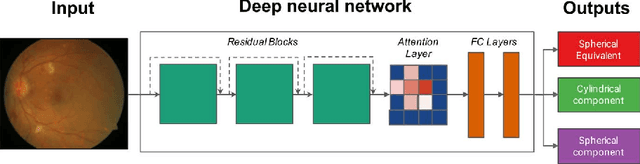
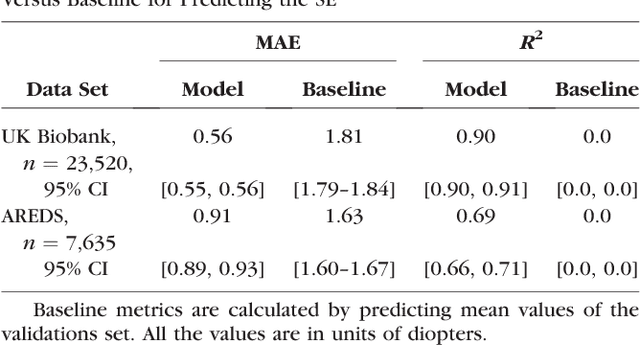
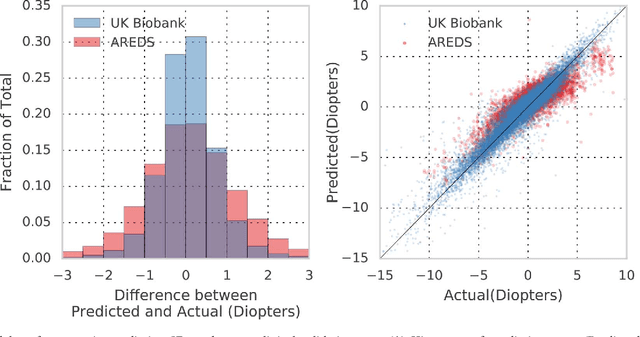
Refractive error, one of the leading cause of visual impairment, can be corrected by simple interventions like prescribing eyeglasses. We trained a deep learning algorithm to predict refractive error from the fundus photographs from participants in the UK Biobank cohort, which were 45 degree field of view images and the AREDS clinical trial, which contained 30 degree field of view images. Our model use the "attention" method to identify features that are correlated with refractive error. Mean absolute error (MAE) of the algorithm's prediction compared to the refractive error obtained in the AREDS and UK Biobank. The resulting algorithm had a MAE of 0.56 diopters (95% CI: 0.55-0.56) for estimating spherical equivalent on the UK Biobank dataset and 0.91 diopters (95% CI: 0.89-0.92) for the AREDS dataset. The baseline expected MAE (obtained by simply predicting the mean of this population) was 1.81 diopters (95% CI: 1.79-1.84) for UK Biobank and 1.63 (95% CI: 1.60-1.67) for AREDS. Attention maps suggested that the foveal region was one of the most important areas used by the algorithm to make this prediction, though other regions also contribute to the prediction. The ability to estimate refractive error with high accuracy from retinal fundus photos has not been previously known and demonstrates that deep learning can be applied to make novel predictions from medical images. Given that several groups have recently shown that it is feasible to obtain retinal fundus photos using mobile phones and inexpensive attachments, this work may be particularly relevant in regions of the world where autorefractors may not be readily available.