 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeoculomix: Hierarchical Sampling for Retinal-Based Systemic Disease Prediction
Jan 16, 2026Oculomics - the concept of predicting systemic diseases, such as cardiovascular disease and dementia, through retinal imaging - has advanced rapidly due to the data efficiency of transformer-based foundation models like RETFound. Image-level mixed sample data augmentations, such as CutMix and MixUp, are frequently used for training transformers, yet these techniques perturb patient-specific attributes, such as medical comorbidity and clinical factors, since they only account for images and labels. To address this limitation, we propose a hierarchical sampling strategy, Oculomix, for mixed sample augmentations. Our method is based on two clinical priors. First (exam level), images acquired from the same patient at the same time point share the same attributes. Second (patient level), images acquired from the same patient at different time points have a soft temporal trend, as morbidity generally increases over time. Guided by these priors, our method constrains the mixing space to the patient and exam levels to better preserve patient-specific characteristics and leverages their hierarchical relationships. The proposed method is validated using ViT models on a five-year prediction of major adverse cardiovascular events (MACE) in a large ethnically diverse population (Alzeye). We show that Oculomix consistently outperforms image-level CutMix and MixUp by up to 3% in AUROC, demonstrating the necessity and value of the proposed method in oculomics.
Native Intelligence Emerges from Large-Scale Clinical Practice: A Retinal Foundation Model with Deployment Efficiency
Dec 16, 2025Current retinal foundation models remain constrained by curated research datasets that lack authentic clinical context, and require extensive task-specific optimization for each application, limiting their deployment efficiency in low-resource settings. Here, we show that these barriers can be overcome by building clinical native intelligence directly from real-world medical practice. Our key insight is that large-scale telemedicine programs, where expert centers provide remote consultations across distributed facilities, represent a natural reservoir for learning clinical image interpretation. We present ReVision, a retinal foundation model that learns from the natural alignment between 485,980 color fundus photographs and their corresponding diagnostic reports, accumulated through a decade-long telemedicine program spanning 162 medical institutions across China. Through extensive evaluation across 27 ophthalmic benchmarks, we demonstrate that ReVison enables deployment efficiency with minimal local resources. Without any task-specific training, ReVision achieves zero-shot disease detection with an average AUROC of 0.946 across 12 public benchmarks and 0.952 on 3 independent clinical cohorts. When minimal adaptation is feasible, ReVision matches extensively fine-tuned alternatives while requiring orders of magnitude fewer trainable parameters and labeled examples. The learned representations also transfer effectively to new clinical sites, imaging domains, imaging modalities, and systemic health prediction tasks. In a prospective reader study with 33 ophthalmologists, ReVision's zero-shot assistance improved diagnostic accuracy by 14.8% across all experience levels. These results demonstrate that clinical native intelligence can be directly extracted from clinical archives without any further annotation to build medical AI systems suited to various low-resource settings.
Generalist versus Specialist Vision Foundation Models for Ocular Disease and Oculomics
Sep 03, 2025Medical foundation models, pre-trained with large-scale clinical data, demonstrate strong performance in diverse clinically relevant applications. RETFound, trained on nearly one million retinal images, exemplifies this approach in applications with retinal images. However, the emergence of increasingly powerful and multifold larger generalist foundation models such as DINOv2 and DINOv3 raises the question of whether domain-specific pre-training remains essential, and if so, what gap persists. To investigate this, we systematically evaluated the adaptability of DINOv2 and DINOv3 in retinal image applications, compared to two specialist RETFound models, RETFound-MAE and RETFound-DINOv2. We assessed performance on ocular disease detection and systemic disease prediction using two adaptation strategies: fine-tuning and linear probing. Data efficiency and adaptation efficiency were further analysed to characterise trade-offs between predictive performance and computational cost. Our results show that although scaling generalist models yields strong adaptability across diverse tasks, RETFound-DINOv2 consistently outperforms these generalist foundation models in ocular-disease detection and oculomics tasks, demonstrating stronger generalisability and data efficiency. These findings suggest that specialist retinal foundation models remain the most effective choice for clinical applications, while the narrowing gap with generalist foundation models suggests that continued data and model scaling can deliver domain-relevant gains and position them as strong foundations for future medical foundation models.
Is an Ultra Large Natural Image-Based Foundation Model Superior to a Retina-Specific Model for Detecting Ocular and Systemic Diseases?
Feb 10, 2025The advent of foundation models (FMs) is transforming medical domain. In ophthalmology, RETFound, a retina-specific FM pre-trained sequentially on 1.4 million natural images and 1.6 million retinal images, has demonstrated high adaptability across clinical applications. Conversely, DINOv2, a general-purpose vision FM pre-trained on 142 million natural images, has shown promise in non-medical domains. However, its applicability to clinical tasks remains underexplored. To address this, we conducted head-to-head evaluations by fine-tuning RETFound and three DINOv2 models (large, base, small) for ocular disease detection and systemic disease prediction tasks, across eight standardized open-source ocular datasets, as well as the Moorfields AlzEye and the UK Biobank datasets. DINOv2-large model outperformed RETFound in detecting diabetic retinopathy (AUROC=0.850-0.952 vs 0.823-0.944, across three datasets, all P<=0.007) and multi-class eye diseases (AUROC=0.892 vs. 0.846, P<0.001). In glaucoma, DINOv2-base model outperformed RETFound (AUROC=0.958 vs 0.940, P<0.001). Conversely, RETFound achieved superior performance over all DINOv2 models in predicting heart failure, myocardial infarction, and ischaemic stroke (AUROC=0.732-0.796 vs 0.663-0.771, all P<0.001). These trends persisted even with 10% of the fine-tuning data. These findings showcase the distinct scenarios where general-purpose and domain-specific FMs excel, highlighting the importance of aligning FM selection with task-specific requirements to optimise clinical performance.
Are Traditional Deep Learning Model Approaches as Effective as a Retinal-Specific Foundation Model for Ocular and Systemic Disease Detection?
Jan 21, 2025Background: RETFound, a self-supervised, retina-specific foundation model (FM), showed potential in downstream applications. However, its comparative performance with traditional deep learning (DL) models remains incompletely understood. This study aimed to evaluate RETFound against three ImageNet-pretrained supervised DL models (ResNet50, ViT-base, SwinV2) in detecting ocular and systemic diseases. Methods: We fine-tuned/trained RETFound and three DL models on full datasets, 50%, 20%, and fixed sample sizes (400, 200, 100 images, with half comprising disease cases; for each DR severity class, 100 and 50 cases were used. Fine-tuned models were tested internally using the SEED (53,090 images) and APTOS-2019 (3,672 images) datasets and externally validated on population-based (BES, CIEMS, SP2, UKBB) and open-source datasets (ODIR-5k, PAPILA, GAMMA, IDRiD, MESSIDOR-2). Model performance was compared using area under the receiver operating characteristic curve (AUC) and Z-tests with Bonferroni correction (P<0.05/3). Interpretation: Traditional DL models are mostly comparable to RETFound for ocular disease detection with large datasets. However, RETFound is superior in systemic disease detection with smaller datasets. These findings offer valuable insights into the respective merits and limitation of traditional models and FMs.
Block Expanded DINORET: Adapting Natural Domain Foundation Models for Retinal Imaging Without Catastrophic Forgetting
Sep 25, 2024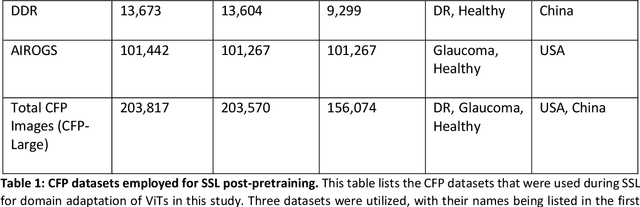
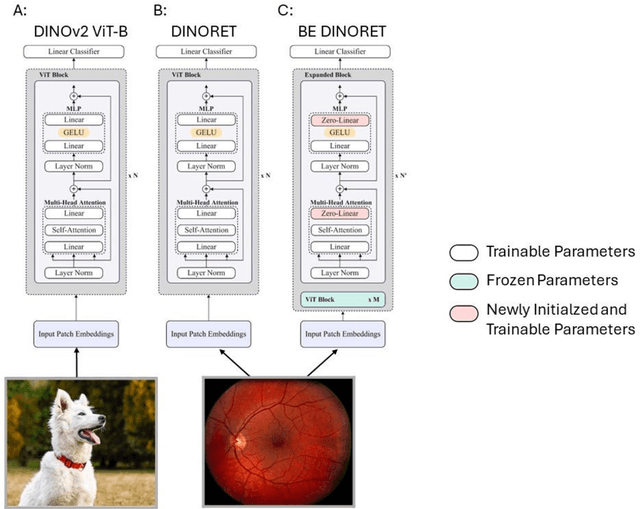
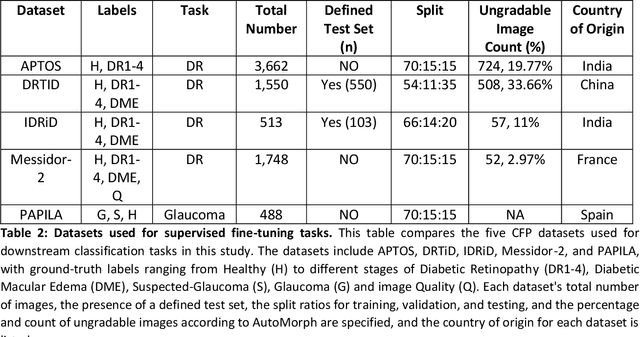
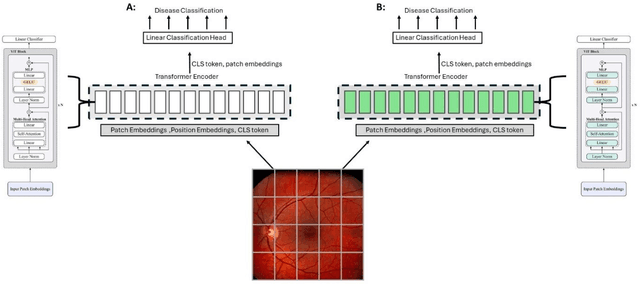
Integrating deep learning into medical imaging is poised to greatly advance diagnostic methods but it faces challenges with generalizability. Foundation models, based on self-supervised learning, address these issues and improve data efficiency. Natural domain foundation models show promise for medical imaging, but systematic research evaluating domain adaptation, especially using self-supervised learning and parameter-efficient fine-tuning, remains underexplored. Additionally, little research addresses the issue of catastrophic forgetting during fine-tuning of foundation models. We adapted the DINOv2 vision transformer for retinal imaging classification tasks using self-supervised learning and generated two novel foundation models termed DINORET and BE DINORET. Publicly available color fundus photographs were employed for model development and subsequent fine-tuning for diabetic retinopathy staging and glaucoma detection. We introduced block expansion as a novel domain adaptation strategy and assessed the models for catastrophic forgetting. Models were benchmarked to RETFound, a state-of-the-art foundation model in ophthalmology. DINORET and BE DINORET demonstrated competitive performance on retinal imaging tasks, with the block expanded model achieving the highest scores on most datasets. Block expansion successfully mitigated catastrophic forgetting. Our few-shot learning studies indicated that DINORET and BE DINORET outperform RETFound in terms of data-efficiency. This study highlights the potential of adapting natural domain vision models to retinal imaging using self-supervised learning and block expansion. BE DINORET offers robust performance without sacrificing previously acquired capabilities. Our findings suggest that these methods could enable healthcare institutions to develop tailored vision models for their patient populations, enhancing global healthcare inclusivity.
Common and Rare Fundus Diseases Identification Using Vision-Language Foundation Model with Knowledge of Over 400 Diseases
Jun 13, 2024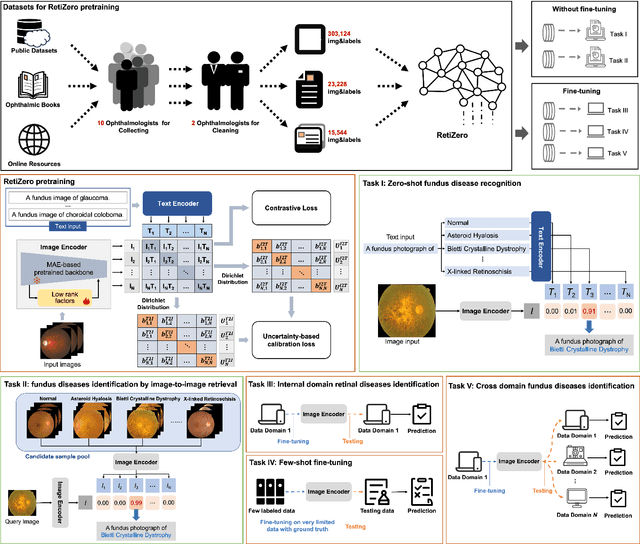
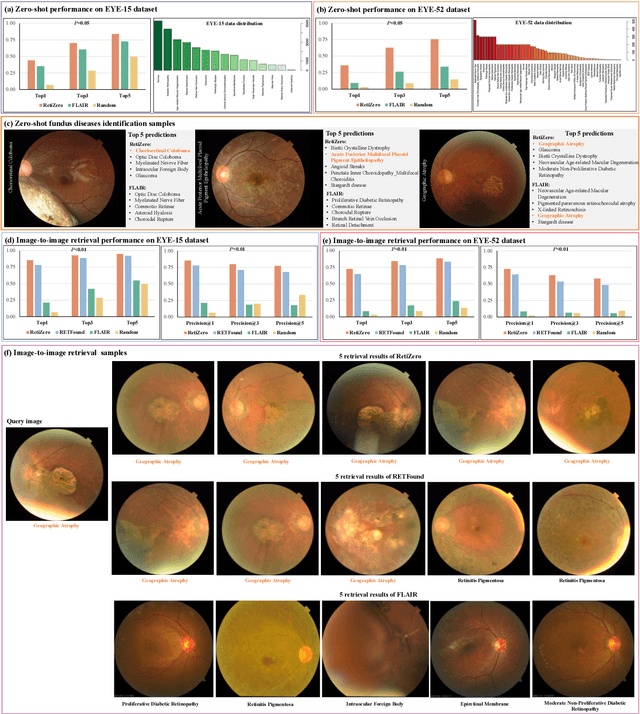
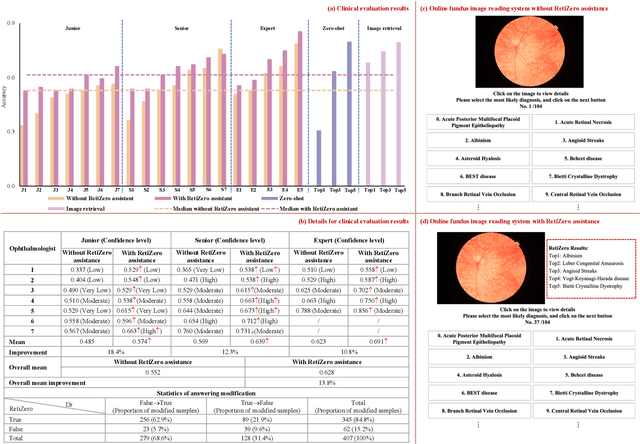
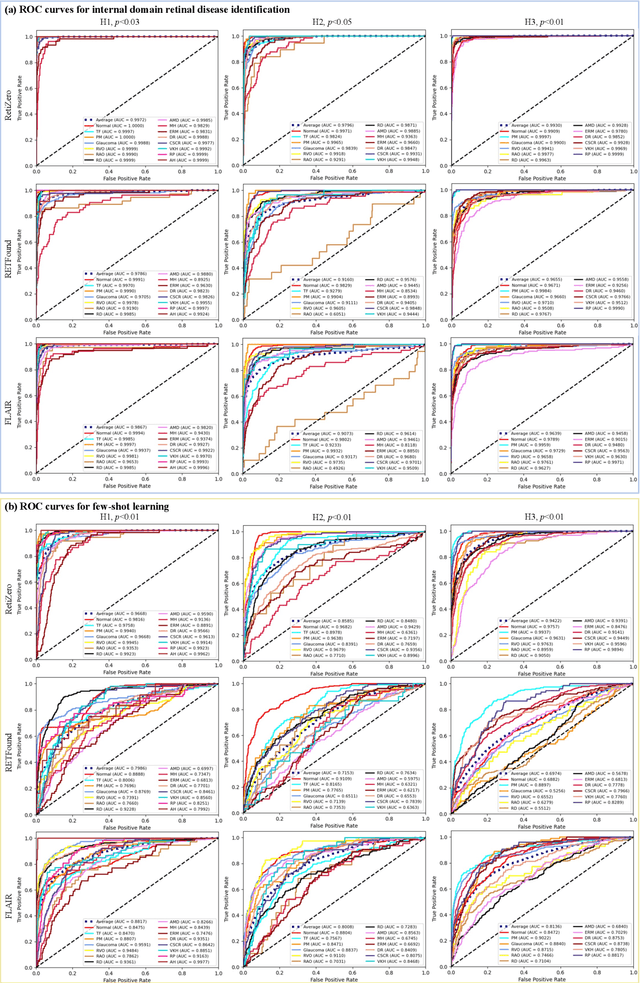
The current retinal artificial intelligence models were trained using data with a limited category of diseases and limited knowledge. In this paper, we present a retinal vision-language foundation model (RetiZero) with knowledge of over 400 fundus diseases. Specifically, we collected 341,896 fundus images paired with text descriptions from 29 publicly available datasets, 180 ophthalmic books, and online resources, encompassing over 400 fundus diseases across multiple countries and ethnicities. RetiZero achieved outstanding performance across various downstream tasks, including zero-shot retinal disease recognition, image-to-image retrieval, internal domain and cross-domain retinal disease classification, and few-shot fine-tuning. Specially, in the zero-shot scenario, RetiZero achieved a Top5 score of 0.8430 and 0.7561 on 15 and 52 fundus diseases respectively. In the image-retrieval task, RetiZero achieved a Top5 score of 0.9500 and 0.8860 on 15 and 52 retinal diseases respectively. Furthermore, clinical evaluations by ophthalmology experts from different countries demonstrate that RetiZero can achieve performance comparable to experienced ophthalmologists using zero-shot and image retrieval methods without requiring model retraining. These capabilities of retinal disease identification strengthen our RetiZero foundation model in clinical implementation.
VAFO-Loss: VAscular Feature Optimised Loss Function for Retinal Artery/Vein Segmentation
Mar 12, 2022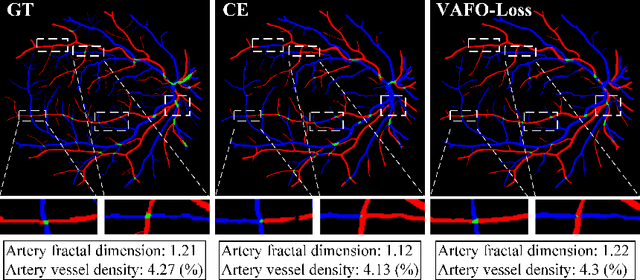
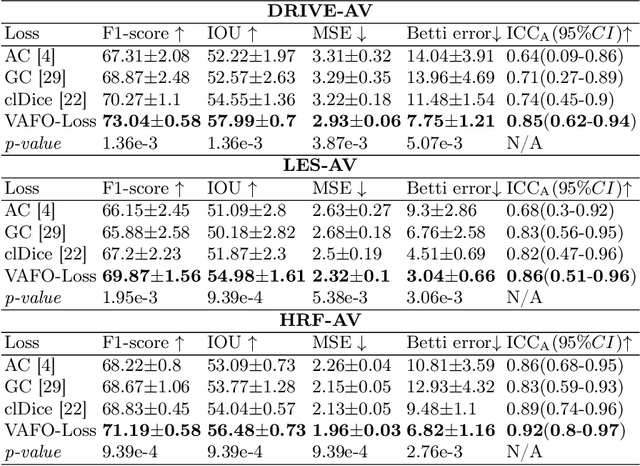
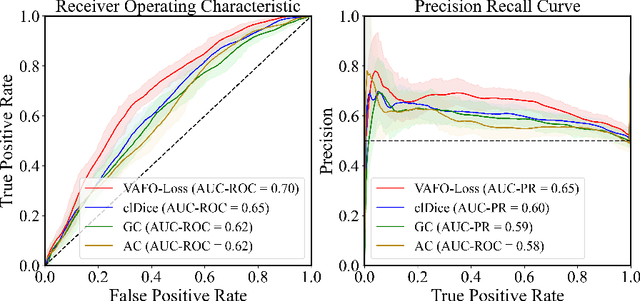
Estimating clinically-relevant vascular features following vessel segmentation is a standard pipeline for retinal vessel analysis, which provides potential ocular biomarkers for both ophthalmic disease and systemic disease. In this work, we integrate these clinical features into a novel vascular feature optimised loss function (VAFO-Loss), in order to regularise networks to produce segmentation maps, with which more accurate vascular features can be derived. Two common vascular features, vessel density and fractal dimension, are identified to be sensitive to intra-segment misclassification, which is a well-recognised problem in multi-class artery/vein segmentation particularly hindering the estimation of these vascular features. Thus we encode these two features into VAFO-Loss. We first show that incorporating our end-to-end VAFO-Loss in standard segmentation networks indeed improves vascular feature estimation, yielding quantitative improvement in stroke incidence prediction, a clinical downstream task. We also report a technically interesting finding that the trained segmentation network, albeit biased by the feature optimised loss VAFO-Loss, shows statistically significant improvement in segmentation metrics, compared to those trained with other state-of-the-art segmentation losses.
Forecasting Future Humphrey Visual Fields Using Deep Learning
Apr 02, 2018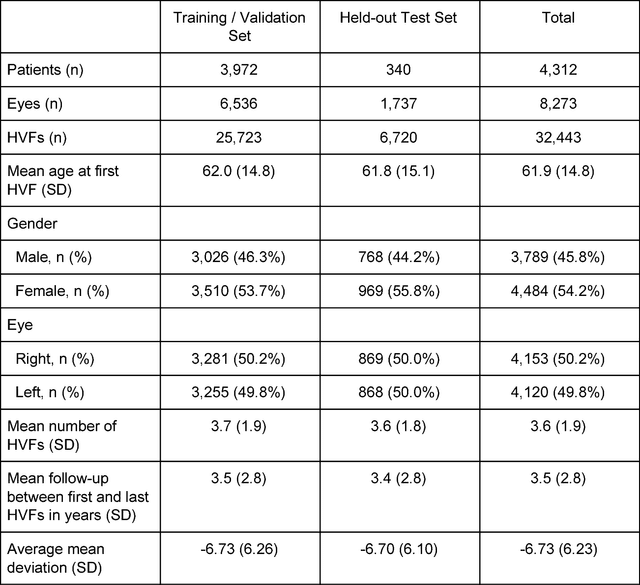
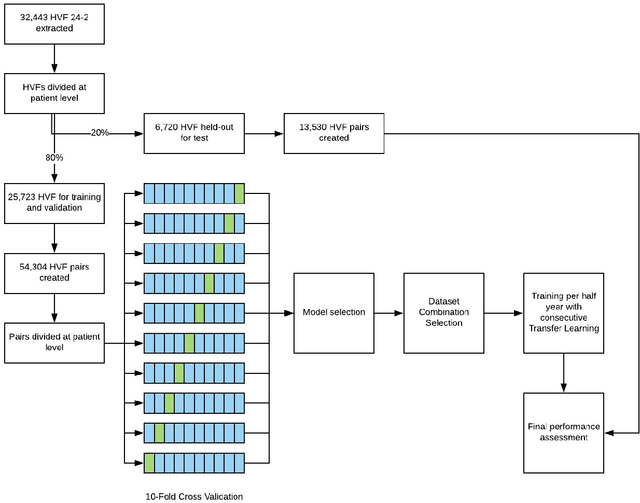

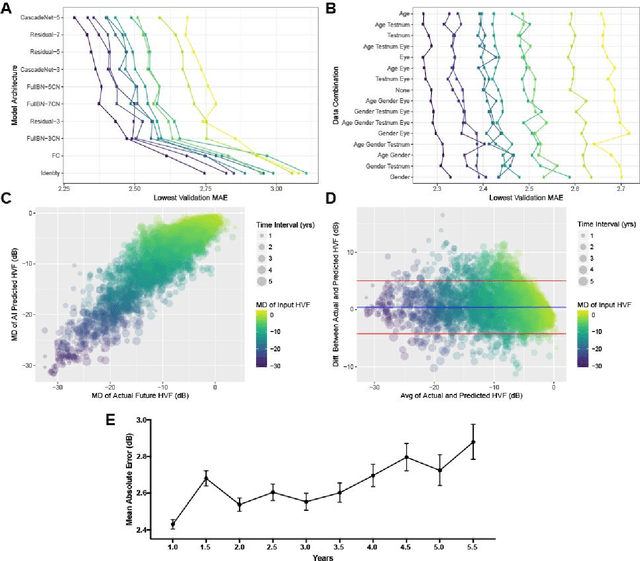
Purpose: To determine if deep learning networks could be trained to forecast a future 24-2 Humphrey Visual Field (HVF). Participants: All patients who obtained a HVF 24-2 at the University of Washington. Methods: All datapoints from consecutive 24-2 HVFs from 1998 to 2018 were extracted from a University of Washington database. Ten-fold cross validation with a held out test set was used to develop the three main phases of model development: model architecture selection, dataset combination selection, and time-interval model training with transfer learning, to train a deep learning artificial neural network capable of generating a point-wise visual field prediction. Results: More than 1.7 million perimetry points were extracted to the hundredth decibel from 32,443 24-2 HVFs. The best performing model with 20 million trainable parameters, CascadeNet-5, was selected. The overall MAE for the test set was 2.47 dB (95% CI: 2.45 dB to 2.48 dB). The 100 fully trained models were able to successfully predict progressive field loss in glaucomatous eyes up to 5.5 years in the future with a correlation of 0.92 between the MD of predicted and actual future HVF (p < 2.2 x 10 -16 ) and an average difference of 0.41 dB. Conclusions: Using unfiltered real-world datasets, deep learning networks show an impressive ability to not only learn spatio-temporal HVF changes but also to generate predictions for future HVFs up to 5.5 years, given only a single HVF.
Deep learning for predicting refractive error from retinal fundus images
Dec 21, 2017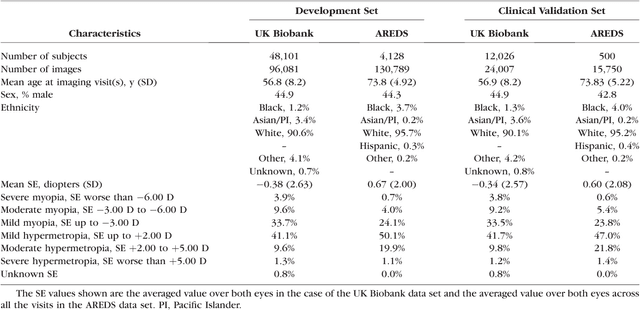
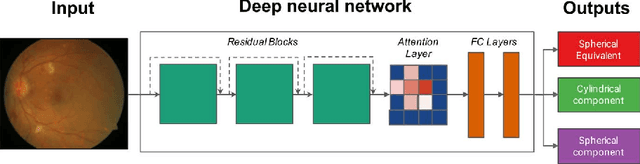
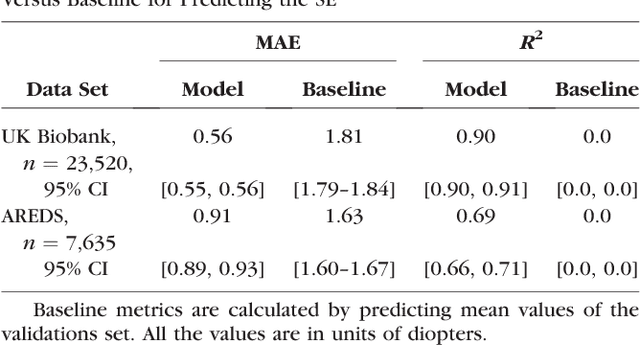
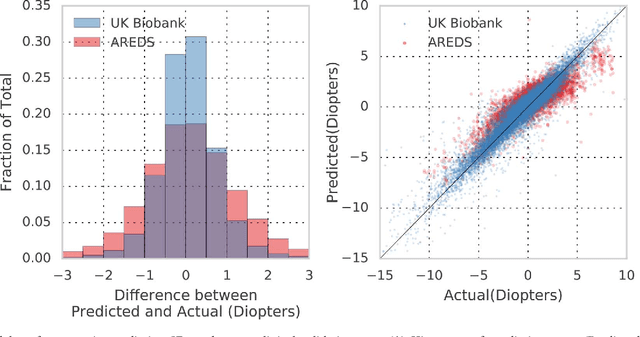
Refractive error, one of the leading cause of visual impairment, can be corrected by simple interventions like prescribing eyeglasses. We trained a deep learning algorithm to predict refractive error from the fundus photographs from participants in the UK Biobank cohort, which were 45 degree field of view images and the AREDS clinical trial, which contained 30 degree field of view images. Our model use the "attention" method to identify features that are correlated with refractive error. Mean absolute error (MAE) of the algorithm's prediction compared to the refractive error obtained in the AREDS and UK Biobank. The resulting algorithm had a MAE of 0.56 diopters (95% CI: 0.55-0.56) for estimating spherical equivalent on the UK Biobank dataset and 0.91 diopters (95% CI: 0.89-0.92) for the AREDS dataset. The baseline expected MAE (obtained by simply predicting the mean of this population) was 1.81 diopters (95% CI: 1.79-1.84) for UK Biobank and 1.63 (95% CI: 1.60-1.67) for AREDS. Attention maps suggested that the foveal region was one of the most important areas used by the algorithm to make this prediction, though other regions also contribute to the prediction. The ability to estimate refractive error with high accuracy from retinal fundus photos has not been previously known and demonstrates that deep learning can be applied to make novel predictions from medical images. Given that several groups have recently shown that it is feasible to obtain retinal fundus photos using mobile phones and inexpensive attachments, this work may be particularly relevant in regions of the world where autorefractors may not be readily available.