 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlock Expanded DINORET: Adapting Natural Domain Foundation Models for Retinal Imaging Without Catastrophic Forgetting
Paper and Code
Sep 25, 2024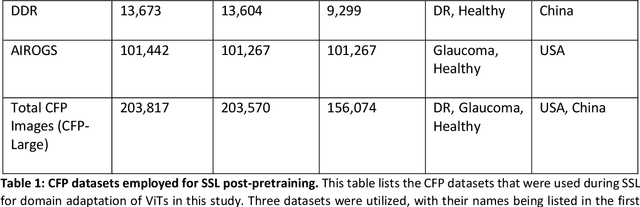
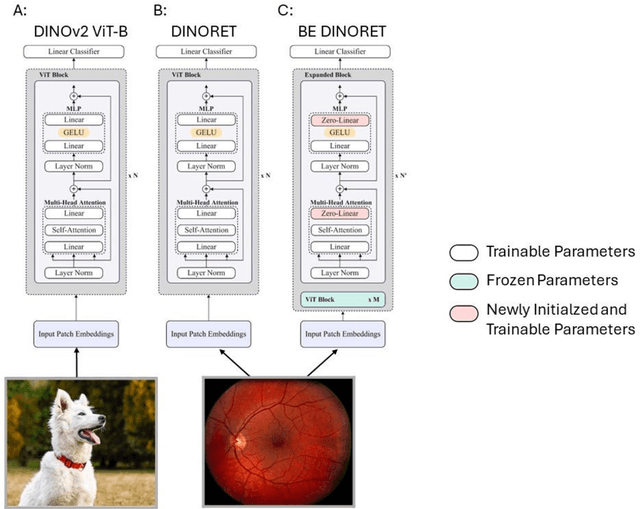
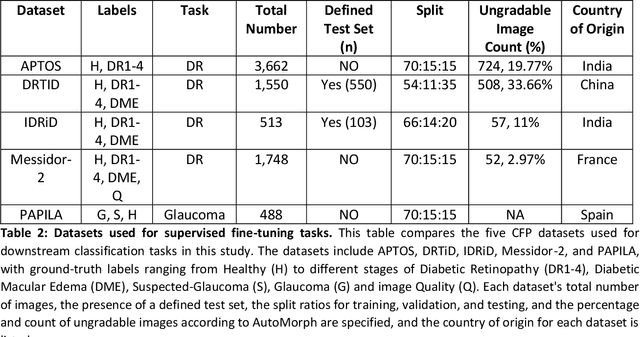
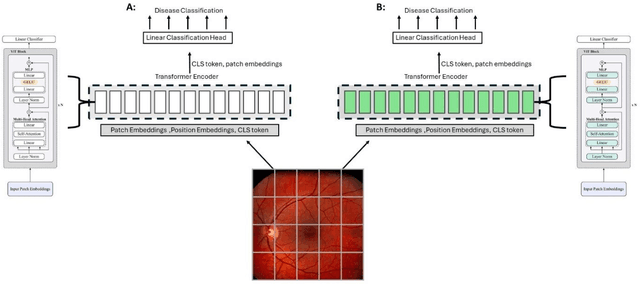
Integrating deep learning into medical imaging is poised to greatly advance diagnostic methods but it faces challenges with generalizability. Foundation models, based on self-supervised learning, address these issues and improve data efficiency. Natural domain foundation models show promise for medical imaging, but systematic research evaluating domain adaptation, especially using self-supervised learning and parameter-efficient fine-tuning, remains underexplored. Additionally, little research addresses the issue of catastrophic forgetting during fine-tuning of foundation models. We adapted the DINOv2 vision transformer for retinal imaging classification tasks using self-supervised learning and generated two novel foundation models termed DINORET and BE DINORET. Publicly available color fundus photographs were employed for model development and subsequent fine-tuning for diabetic retinopathy staging and glaucoma detection. We introduced block expansion as a novel domain adaptation strategy and assessed the models for catastrophic forgetting. Models were benchmarked to RETFound, a state-of-the-art foundation model in ophthalmology. DINORET and BE DINORET demonstrated competitive performance on retinal imaging tasks, with the block expanded model achieving the highest scores on most datasets. Block expansion successfully mitigated catastrophic forgetting. Our few-shot learning studies indicated that DINORET and BE DINORET outperform RETFound in terms of data-efficiency. This study highlights the potential of adapting natural domain vision models to retinal imaging using self-supervised learning and block expansion. BE DINORET offers robust performance without sacrificing previously acquired capabilities. Our findings suggest that these methods could enable healthcare institutions to develop tailored vision models for their patient populations, enhancing global healthcare inclusivity.