 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralist versus Specialist Vision Foundation Models for Ocular Disease and Oculomics
Sep 03, 2025Medical foundation models, pre-trained with large-scale clinical data, demonstrate strong performance in diverse clinically relevant applications. RETFound, trained on nearly one million retinal images, exemplifies this approach in applications with retinal images. However, the emergence of increasingly powerful and multifold larger generalist foundation models such as DINOv2 and DINOv3 raises the question of whether domain-specific pre-training remains essential, and if so, what gap persists. To investigate this, we systematically evaluated the adaptability of DINOv2 and DINOv3 in retinal image applications, compared to two specialist RETFound models, RETFound-MAE and RETFound-DINOv2. We assessed performance on ocular disease detection and systemic disease prediction using two adaptation strategies: fine-tuning and linear probing. Data efficiency and adaptation efficiency were further analysed to characterise trade-offs between predictive performance and computational cost. Our results show that although scaling generalist models yields strong adaptability across diverse tasks, RETFound-DINOv2 consistently outperforms these generalist foundation models in ocular-disease detection and oculomics tasks, demonstrating stronger generalisability and data efficiency. These findings suggest that specialist retinal foundation models remain the most effective choice for clinical applications, while the narrowing gap with generalist foundation models suggests that continued data and model scaling can deliver domain-relevant gains and position them as strong foundations for future medical foundation models.
Is an Ultra Large Natural Image-Based Foundation Model Superior to a Retina-Specific Model for Detecting Ocular and Systemic Diseases?
Feb 10, 2025The advent of foundation models (FMs) is transforming medical domain. In ophthalmology, RETFound, a retina-specific FM pre-trained sequentially on 1.4 million natural images and 1.6 million retinal images, has demonstrated high adaptability across clinical applications. Conversely, DINOv2, a general-purpose vision FM pre-trained on 142 million natural images, has shown promise in non-medical domains. However, its applicability to clinical tasks remains underexplored. To address this, we conducted head-to-head evaluations by fine-tuning RETFound and three DINOv2 models (large, base, small) for ocular disease detection and systemic disease prediction tasks, across eight standardized open-source ocular datasets, as well as the Moorfields AlzEye and the UK Biobank datasets. DINOv2-large model outperformed RETFound in detecting diabetic retinopathy (AUROC=0.850-0.952 vs 0.823-0.944, across three datasets, all P<=0.007) and multi-class eye diseases (AUROC=0.892 vs. 0.846, P<0.001). In glaucoma, DINOv2-base model outperformed RETFound (AUROC=0.958 vs 0.940, P<0.001). Conversely, RETFound achieved superior performance over all DINOv2 models in predicting heart failure, myocardial infarction, and ischaemic stroke (AUROC=0.732-0.796 vs 0.663-0.771, all P<0.001). These trends persisted even with 10% of the fine-tuning data. These findings showcase the distinct scenarios where general-purpose and domain-specific FMs excel, highlighting the importance of aligning FM selection with task-specific requirements to optimise clinical performance.
Block Expanded DINORET: Adapting Natural Domain Foundation Models for Retinal Imaging Without Catastrophic Forgetting
Sep 25, 2024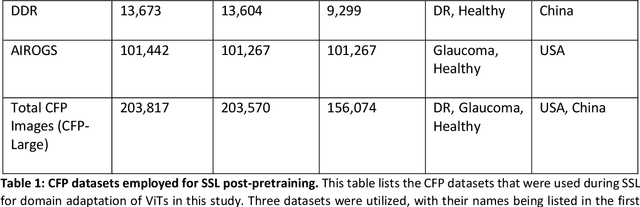
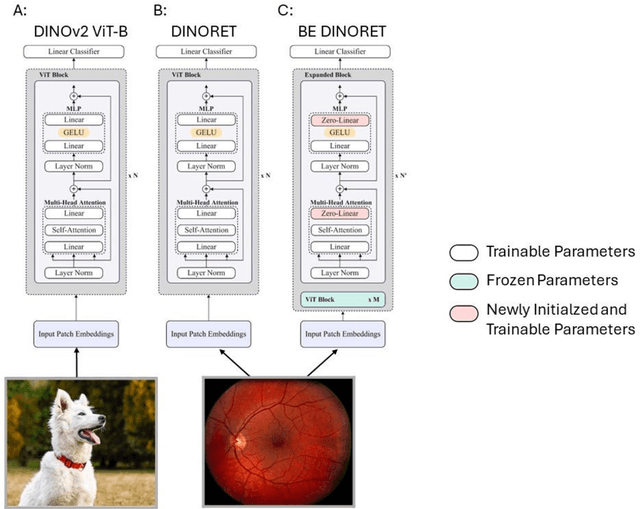
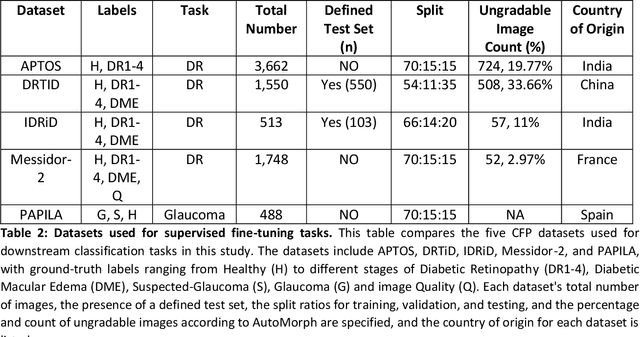
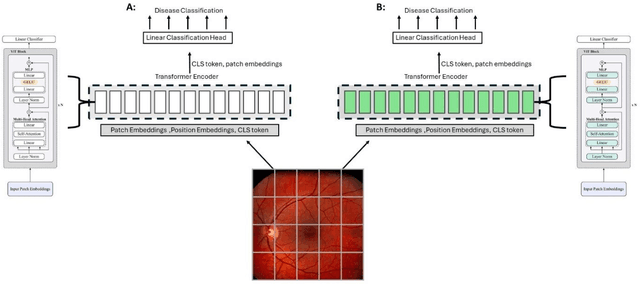
Integrating deep learning into medical imaging is poised to greatly advance diagnostic methods but it faces challenges with generalizability. Foundation models, based on self-supervised learning, address these issues and improve data efficiency. Natural domain foundation models show promise for medical imaging, but systematic research evaluating domain adaptation, especially using self-supervised learning and parameter-efficient fine-tuning, remains underexplored. Additionally, little research addresses the issue of catastrophic forgetting during fine-tuning of foundation models. We adapted the DINOv2 vision transformer for retinal imaging classification tasks using self-supervised learning and generated two novel foundation models termed DINORET and BE DINORET. Publicly available color fundus photographs were employed for model development and subsequent fine-tuning for diabetic retinopathy staging and glaucoma detection. We introduced block expansion as a novel domain adaptation strategy and assessed the models for catastrophic forgetting. Models were benchmarked to RETFound, a state-of-the-art foundation model in ophthalmology. DINORET and BE DINORET demonstrated competitive performance on retinal imaging tasks, with the block expanded model achieving the highest scores on most datasets. Block expansion successfully mitigated catastrophic forgetting. Our few-shot learning studies indicated that DINORET and BE DINORET outperform RETFound in terms of data-efficiency. This study highlights the potential of adapting natural domain vision models to retinal imaging using self-supervised learning and block expansion. BE DINORET offers robust performance without sacrificing previously acquired capabilities. Our findings suggest that these methods could enable healthcare institutions to develop tailored vision models for their patient populations, enhancing global healthcare inclusivity.