 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralist versus Specialist Vision Foundation Models for Ocular Disease and Oculomics
Sep 03, 2025Medical foundation models, pre-trained with large-scale clinical data, demonstrate strong performance in diverse clinically relevant applications. RETFound, trained on nearly one million retinal images, exemplifies this approach in applications with retinal images. However, the emergence of increasingly powerful and multifold larger generalist foundation models such as DINOv2 and DINOv3 raises the question of whether domain-specific pre-training remains essential, and if so, what gap persists. To investigate this, we systematically evaluated the adaptability of DINOv2 and DINOv3 in retinal image applications, compared to two specialist RETFound models, RETFound-MAE and RETFound-DINOv2. We assessed performance on ocular disease detection and systemic disease prediction using two adaptation strategies: fine-tuning and linear probing. Data efficiency and adaptation efficiency were further analysed to characterise trade-offs between predictive performance and computational cost. Our results show that although scaling generalist models yields strong adaptability across diverse tasks, RETFound-DINOv2 consistently outperforms these generalist foundation models in ocular-disease detection and oculomics tasks, demonstrating stronger generalisability and data efficiency. These findings suggest that specialist retinal foundation models remain the most effective choice for clinical applications, while the narrowing gap with generalist foundation models suggests that continued data and model scaling can deliver domain-relevant gains and position them as strong foundations for future medical foundation models.
Benchmarking Next-Generation Reasoning-Focused Large Language Models in Ophthalmology: A Head-to-Head Evaluation on 5,888 Items
Apr 15, 2025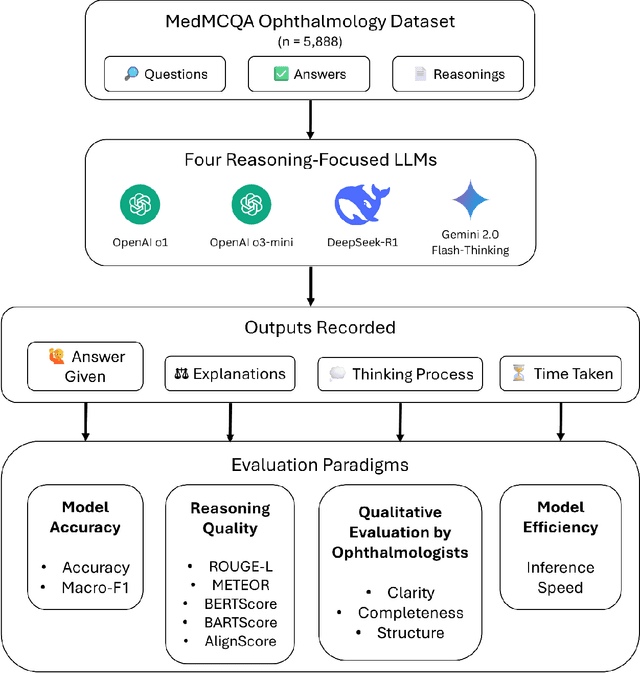
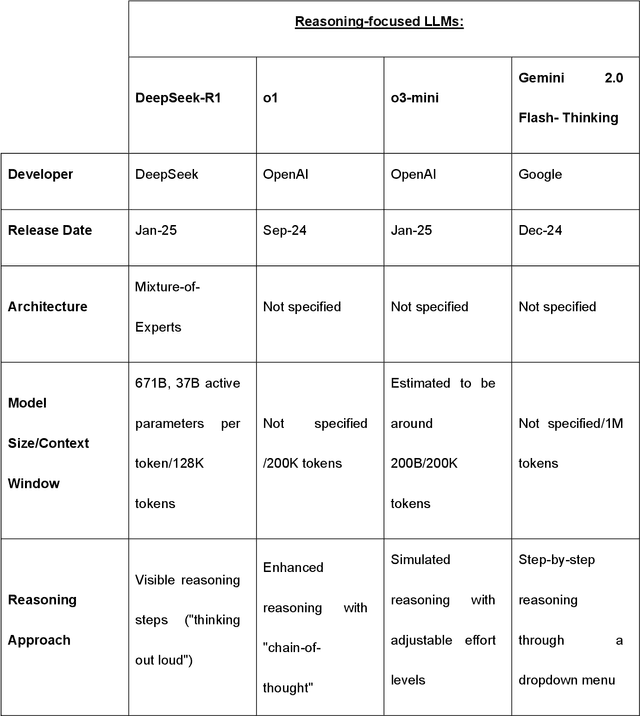
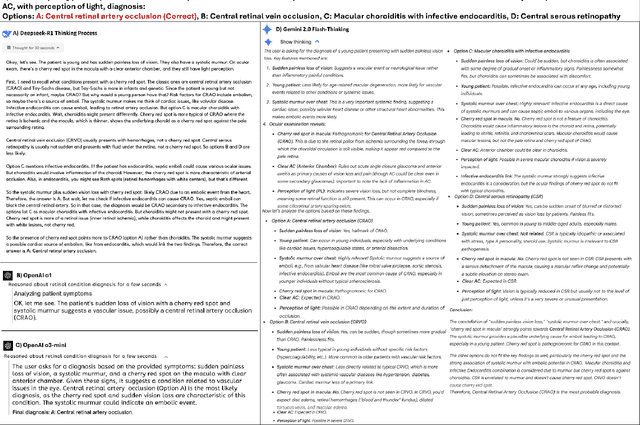
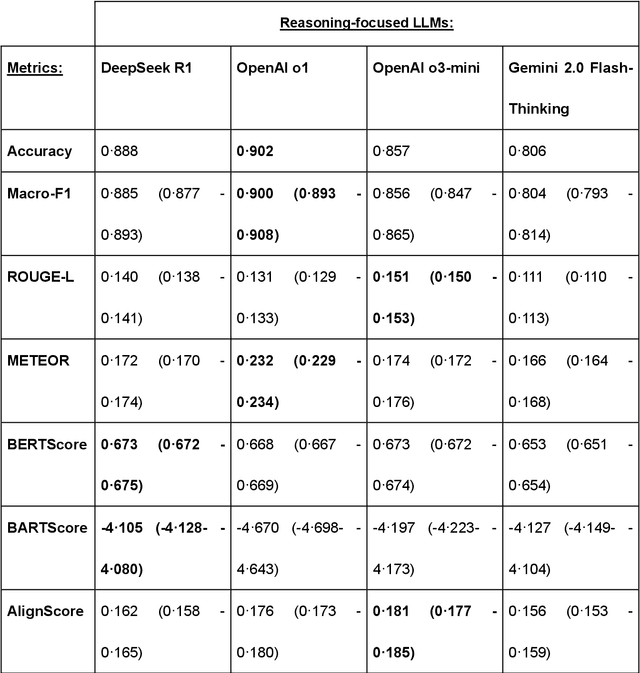
Recent advances in reasoning-focused large language models (LLMs) mark a shift from general LLMs toward models designed for complex decision-making, a crucial aspect in medicine. However, their performance in specialized domains like ophthalmology remains underexplored. This study comprehensively evaluated and compared the accuracy and reasoning capabilities of four newly developed reasoning-focused LLMs, namely DeepSeek-R1, OpenAI o1, o3-mini, and Gemini 2.0 Flash-Thinking. Each model was assessed using 5,888 multiple-choice ophthalmology exam questions from the MedMCQA dataset in zero-shot setting. Quantitative evaluation included accuracy, Macro-F1, and five text-generation metrics (ROUGE-L, METEOR, BERTScore, BARTScore, and AlignScore), computed against ground-truth reasonings. Average inference time was recorded for a subset of 100 randomly selected questions. Additionally, two board-certified ophthalmologists qualitatively assessed clarity, completeness, and reasoning structure of responses to differential diagnosis questions.O1 (0.902) and DeepSeek-R1 (0.888) achieved the highest accuracy, with o1 also leading in Macro-F1 (0.900). The performance of models across the text-generation metrics varied: O3-mini excelled in ROUGE-L (0.151), o1 in METEOR (0.232), DeepSeek-R1 and o3-mini tied for BERTScore (0.673), DeepSeek-R1 (-4.105) and Gemini 2.0 Flash-Thinking (-4.127) performed best in BARTScore, while o3-mini (0.181) and o1 (0.176) led AlignScore. Inference time across the models varied, with DeepSeek-R1 being slowest (40.4 seconds) and Gemini 2.0 Flash-Thinking fastest (6.7 seconds). Qualitative evaluation revealed that DeepSeek-R1 and Gemini 2.0 Flash-Thinking tended to provide detailed and comprehensive intermediate reasoning, whereas o1 and o3-mini displayed concise and summarized justifications.
Is an Ultra Large Natural Image-Based Foundation Model Superior to a Retina-Specific Model for Detecting Ocular and Systemic Diseases?
Feb 10, 2025The advent of foundation models (FMs) is transforming medical domain. In ophthalmology, RETFound, a retina-specific FM pre-trained sequentially on 1.4 million natural images and 1.6 million retinal images, has demonstrated high adaptability across clinical applications. Conversely, DINOv2, a general-purpose vision FM pre-trained on 142 million natural images, has shown promise in non-medical domains. However, its applicability to clinical tasks remains underexplored. To address this, we conducted head-to-head evaluations by fine-tuning RETFound and three DINOv2 models (large, base, small) for ocular disease detection and systemic disease prediction tasks, across eight standardized open-source ocular datasets, as well as the Moorfields AlzEye and the UK Biobank datasets. DINOv2-large model outperformed RETFound in detecting diabetic retinopathy (AUROC=0.850-0.952 vs 0.823-0.944, across three datasets, all P<=0.007) and multi-class eye diseases (AUROC=0.892 vs. 0.846, P<0.001). In glaucoma, DINOv2-base model outperformed RETFound (AUROC=0.958 vs 0.940, P<0.001). Conversely, RETFound achieved superior performance over all DINOv2 models in predicting heart failure, myocardial infarction, and ischaemic stroke (AUROC=0.732-0.796 vs 0.663-0.771, all P<0.001). These trends persisted even with 10% of the fine-tuning data. These findings showcase the distinct scenarios where general-purpose and domain-specific FMs excel, highlighting the importance of aligning FM selection with task-specific requirements to optimise clinical performance.
Are Traditional Deep Learning Model Approaches as Effective as a Retinal-Specific Foundation Model for Ocular and Systemic Disease Detection?
Jan 21, 2025Background: RETFound, a self-supervised, retina-specific foundation model (FM), showed potential in downstream applications. However, its comparative performance with traditional deep learning (DL) models remains incompletely understood. This study aimed to evaluate RETFound against three ImageNet-pretrained supervised DL models (ResNet50, ViT-base, SwinV2) in detecting ocular and systemic diseases. Methods: We fine-tuned/trained RETFound and three DL models on full datasets, 50%, 20%, and fixed sample sizes (400, 200, 100 images, with half comprising disease cases; for each DR severity class, 100 and 50 cases were used. Fine-tuned models were tested internally using the SEED (53,090 images) and APTOS-2019 (3,672 images) datasets and externally validated on population-based (BES, CIEMS, SP2, UKBB) and open-source datasets (ODIR-5k, PAPILA, GAMMA, IDRiD, MESSIDOR-2). Model performance was compared using area under the receiver operating characteristic curve (AUC) and Z-tests with Bonferroni correction (P<0.05/3). Interpretation: Traditional DL models are mostly comparable to RETFound for ocular disease detection with large datasets. However, RETFound is superior in systemic disease detection with smaller datasets. These findings offer valuable insights into the respective merits and limitation of traditional models and FMs.
COVID-19 Monitoring System using Social Distancing and Face Mask Detection on Surveillance video datasets
Oct 08, 2021
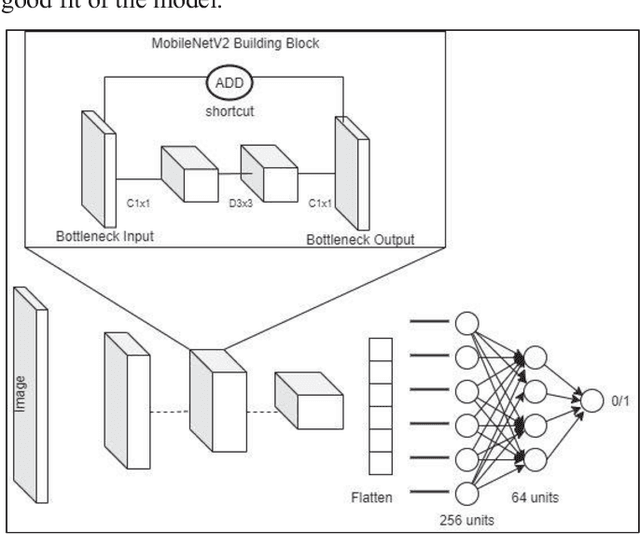


In the current times, the fear and danger of COVID-19 virus still stands large. Manual monitoring of social distancing norms is impractical with a large population moving about and with insufficient task force and resources to administer them. There is a need for a lightweight, robust and 24X7 video-monitoring system that automates this process. This paper proposes a comprehensive and effective solution to perform person detection, social distancing violation detection, face detection and face mask classification using object detection, clustering and Convolution Neural Network (CNN) based binary classifier. For this, YOLOv3, Density-based spatial clustering of applications with noise (DBSCAN), Dual Shot Face Detector (DSFD) and MobileNetV2 based binary classifier have been employed on surveillance video datasets. This paper also provides a comparative study of different face detection and face mask classification models. Finally, a video dataset labelling method is proposed along with the labelled video dataset to compensate for the lack of dataset in the community and is used for evaluation of the system. The system performance is evaluated in terms of accuracy, F1 score as well as the prediction time, which has to be low for practical applicability. The system performs with an accuracy of 91.2% and F1 score of 90.79% on the labelled video dataset and has an average prediction time of 7.12 seconds for 78 frames of a video.