 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplementation of tangent linear and adjoint models for neural networks based on a compiler library tool
Mar 17, 2026This paper presents TorchNWP, a compilation library tool for the efficient coupling of artificial intelligence components and traditional numerical models. It aims to address the issues of poor cross-language compatibility, insufficient coupling flexibility, and low data transfer efficiency between operational numerical models developed in Fortran and Python-based deep learning frameworks. Based on LibTorch, it optimizes and designs a unified application-layer calling interface, converts deep learning models under the PyTorch framework into a static binary format, and provides C/C++ interfaces. Then, using hybrid Fortran/C/C++ programming, it enables the deployment of deep learning models within numerical models. Integrating TorchNWP into a numerical model only requires compiling it into a callable link library and linking it during the compilation and linking phase to generate the executable. On this basis, tangent linear and adjoint model based on neural networks are implemented at the C/C++ level, which can shield the internal structure of neural network models and simplify the construction process of four-dimensional variational data assimilation systems. Meanwhile, it supports deployment on heterogeneous platforms, is compatible with mainstream neural network models, and enables mapping of different parallel granularities and efficient parallel execution. Using this tool requires minimal code modifications to the original numerical model, thus reducing coupling costs. It can be efficiently integrated into numerical weather prediction models such as CMA-GFS and MCV, and has been applied to the coupling of deep learning-based physical parameterization schemes (e.g., radiation, non-orographic gravity wave drag) and the development of their tangent linear and adjoint models, significantly improving the accuracy and efficiency of numerical weather prediction.
Machine learning based radiative parameterization scheme and its performance in operational reforecast experiments
Jan 20, 2026Radiation is typically the most time-consuming physical process in numerical models. One solution is to use machine learning methods to simulate the radiation process to improve computational efficiency. From an operational standpoint, this study investigates critical limitations inherent to hybrid forecasting frameworks that embed deep neural networks into numerical prediction models, with a specific focus on two fundamental bottlenecks: coupling compatibility and long-term integration stability. A residual convolutional neural network is employed to approximate the Rapid Radiative Transfer Model for General Circulation Models (RRTMG) within the global operational system of China Meteorological Administration. We adopted an offline training and online coupling approach. First, a comprehensive dataset is generated through model simulations, encompassing all atmospheric columns both with and without cloud cover. To ensure the stability of the hybrid model, the dataset is enhanced via experience replay, and additional output constraints based on physical significance are imposed. Meanwhile, a LibTorch-based coupling method is utilized, which is more suitable for real-time operational computations. The hybrid model is capable of performing ten-day integrated forecasts as required. A two-month operational reforecast experiment demonstrates that the machine learning emulator achieves accuracy comparable to that of the traditional physical scheme, while accelerating the computation speed by approximately eightfold.
6DMA-Aided Hybrid Beamforming with Joint Antenna Position and Orientation Optimization
Dec 22, 2024This paper studies a sub-connected six-dimensional movable antenna (6DMA)-aided multi-user communication system. In this system, each sub-array is connected to a dedicated radio frequency chain and collectively moves and rotates as a unit within specific local regions. The movement and rotation capabilities of 6DMAs enhance design flexibility, facilitating the capture of spatial variations for improved communication performance. To fully characterize the effect of antenna position and orientation on wireless channels between the base station (BS) and users, we develop a field-response-based 6DMA channel model to account for the antenna radiation pattern and polarization. We then maximize the sum rate of multiple users, by jointly optimizing the digital and unit-modulus analog beamformers given the transmit power budget as well as the positions and orientations of sub-arrays within given movable and rotatable ranges at the BS. Due to the highly coupled variables, the formulated optimization problem is non-convex and thus challenging to solve. We develop a fractional programming-aided alternating optimization framework that integrates the Lagrange multiplier method, manifold optimization, and gradient descent to solve the problem. Numerical results demonstrate that the proposed 6DMA-aided sub-connected structure achieves a substantial sum-rate improvement over various benchmark schemes with less flexibility in antenna movement and can even outperform fully-digital beamforming systems that employ antenna position or orientation adjustments only. The results also highlight the necessity of considering antenna polarization for optimally adjusting antenna orientation.
Intra-symbol Differential Amplitude Shift Keying-aided Blind Detector for Ambient Backscatter Communication Systems
Aug 16, 2024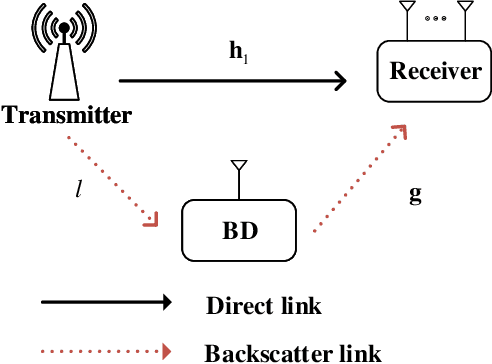
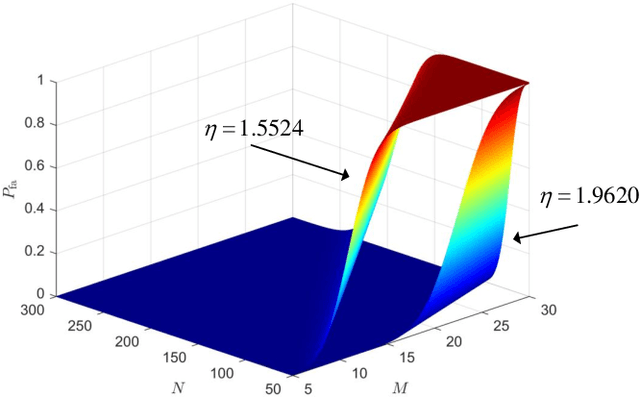
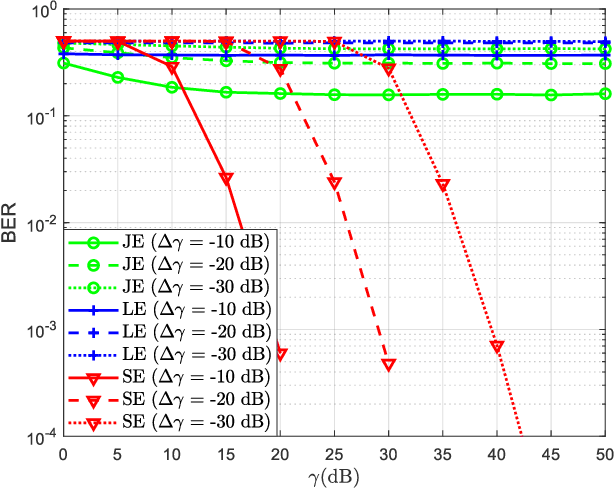
Ambient backscatter communications (AmBC) are a promising technology for addressing the energy consumption challenge in wireless communications through the reflection or absorption of surrounding radio frequency (RF) signals. However, it grapples with the intricacies of ambient RF signal and the round-trip path loss. For traditional detectors, the incorporation of pilot sequences results in a reduction in spectral efficiency. Furthermore, traditional energy-based detectors are inherently susceptible to a notable error floor issue, attributed to the co-channel direct link interference (DLI). Consequently, this paper proposes a blind symbol detector without the prior knowledge of the channel state information, signal variance, and noise variance. By leveraging the intra-symbol differential amplitude shift keying (IDASK) scheme, this detector effectively redirects the majority of the DLI energy towards the largest eigenvalue of the received sample covariance matrix, thereby utilizing the second largest eigenvalue for efficient symbol detection. In addition, this paper conducts theoretical performance analyses of the proposed detector in terms of the false alarm probability, missed detection probability, and the bit-error rate (BER) lower bound. Simulation results demonstrate that the proposed blind detector exhibits a significant enhancement in symbol detection performance compared to its traditional counterparts.
Enhanced Self-supervised Learning for Multi-modality MRI Segmentation and Classification: A Novel Approach Avoiding Model Collapse
Jul 15, 2024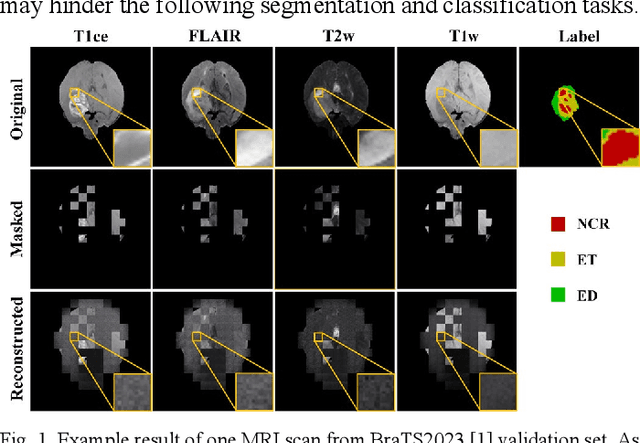
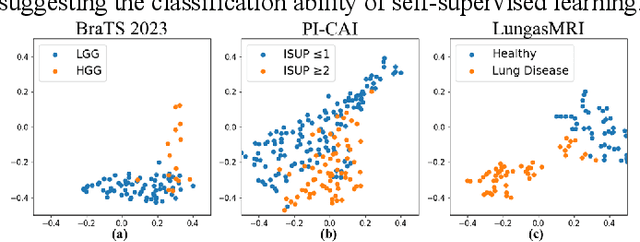
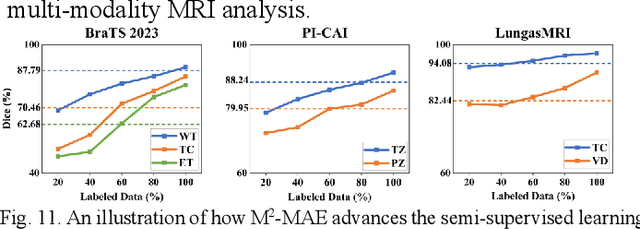
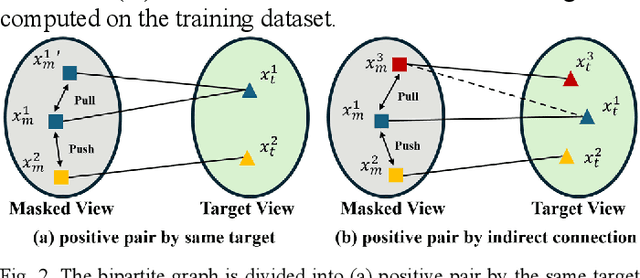
Multi-modality magnetic resonance imaging (MRI) can provide complementary information for computer-aided diagnosis. Traditional deep learning algorithms are suitable for identifying specific anatomical structures segmenting lesions and classifying diseases with magnetic resonance images. However, manual labels are limited due to high expense, which hinders further improvement of model accuracy. Self-supervised learning (SSL) can effectively learn feature representations from unlabeled data by pre-training and is demonstrated to be effective in natural image analysis. Most SSL methods ignore the similarity of multi-modality MRI, leading to model collapse. This limits the efficiency of pre-training, causing low accuracy in downstream segmentation and classification tasks. To solve this challenge, we establish and validate a multi-modality MRI masked autoencoder consisting of hybrid mask pattern (HMP) and pyramid barlow twin (PBT) module for SSL on multi-modality MRI analysis. The HMP concatenates three masking steps forcing the SSL to learn the semantic connections of multi-modality images by reconstructing the masking patches. We have proved that the proposed HMP can avoid model collapse. The PBT module exploits the pyramidal hierarchy of the network to construct barlow twin loss between masked and original views, aligning the semantic representations of image patches at different vision scales in latent space. Experiments on BraTS2023, PI-CAI, and lung gas MRI datasets further demonstrate the superiority of our framework over the state-of-the-art. The performance of the segmentation and classification is substantially enhanced, supporting the accurate detection of small lesion areas. The code is available at https://github.com/LinxuanHan/M2-MAE.
Movable Antenna-Aided Hybrid Beamforming for Multi-User Communications
Apr 01, 2024In this correspondence, we propose a movable antenna (MA)-aided multi-user hybrid beamforming scheme with a sub-connected structure, where multiple movable sub-arrays can independently change their positions within different local regions. To maximize the system sum rate, we jointly optimize the digital beamformer, analog beamformer, and positions of subarrays, under the constraints of unit modulus, finite movable regions, and power budget. Due to the non-concave/non-convex objective function/constraints, as well as the highly coupled variables, the formulated problem is challenging to solve. By employing fractional programming, we develop an alternating optimization framework to solve the problem via a combination of Lagrange multipliers, penalty method, and gradient descent. Numerical results reveal that the proposed MA-aided hybrid beamforming scheme significantly improves the sum rate compared to its fixed-position antenna (FPA) counterpart. Moreover, with sufficiently large movable regions, the proposed scheme with sub-connected MA arrays even outperforms the fully-connected FPA array.
Near-Field Wideband Secure Communications: An Analog Beamfocusing Approach
Nov 29, 2023



In the rapidly advancing landscape of 6G, characterized by ultra-high-speed wideband transmission in millimeter-wave and terahertz bands, our paper addresses the pivotal task of enhancing physical layer security (PLS) within near-field wideband communications. We introduce true-time delayer (TTD)-incorporated analog beamfocusing techniques designed to address the interplay between near-field propagation and wideband beamsplit, an uncharted domain in existing literature. Our approach to maximizing secrecy rates involves formulating an optimization problem for joint power allocation and analog beamformer design, employing a two-stage process encompassing a semi-digital solution and analog approximation. This problem is efficiently solved through a combination of alternating optimization, fractional programming, and block successive upper-bound minimization techniques. Additionally, we present a low-complexity beamsplit-aware beamfocusing strategy, capitalizing on geometric insights from near-field wideband propagation, which can also serve as a robust initial value for the optimization-based approach. Numerical results substantiate the efficacy of the proposed methods, clearly demonstrating their superiority over TTD-free approaches in fortifying wideband PLS, as well as the advantageous secrecy energy efficiency achieved by leveraging low-cost analog devices.
Encoding Enhanced Complex CNN for Accurate and Highly Accelerated MRI
Jun 21, 2023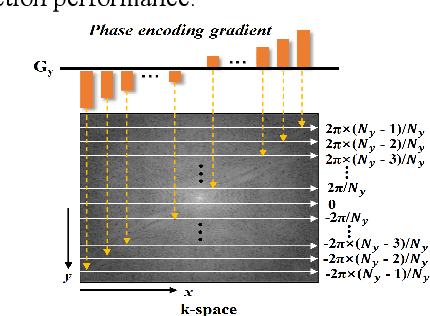
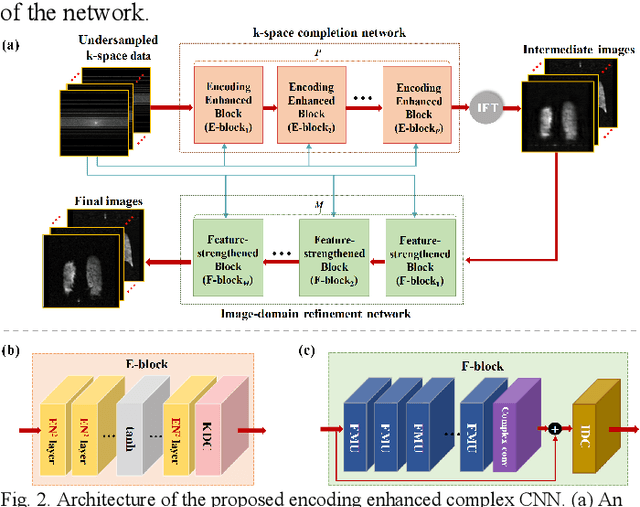
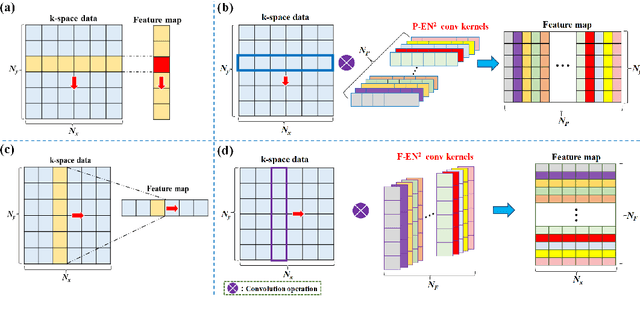
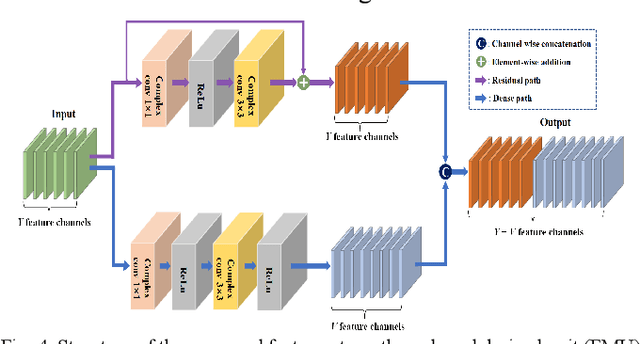
Magnetic resonance imaging (MRI) using hyperpolarized noble gases provides a way to visualize the structure and function of human lung, but the long imaging time limits its broad research and clinical applications. Deep learning has demonstrated great potential for accelerating MRI by reconstructing images from undersampled data. However, most existing deep conventional neural networks (CNN) directly apply square convolution to k-space data without considering the inherent properties of k-space sampling, limiting k-space learning efficiency and image reconstruction quality. In this work, we propose an encoding enhanced (EN2) complex CNN for highly undersampled pulmonary MRI reconstruction. EN2 employs convolution along either the frequency or phase-encoding direction, resembling the mechanisms of k-space sampling, to maximize the utilization of the encoding correlation and integrity within a row or column of k-space. We also employ complex convolution to learn rich representations from the complex k-space data. In addition, we develop a feature-strengthened modularized unit to further boost the reconstruction performance. Experiments demonstrate that our approach can accurately reconstruct hyperpolarized 129Xe and 1H lung MRI from 6-fold undersampled k-space data and provide lung function measurements with minimal biases compared with fully-sampled image. These results demonstrate the effectiveness of the proposed algorithmic components and indicate that the proposed approach could be used for accelerated pulmonary MRI in research and clinical lung disease patient care.
UAV-Enabled Cooperative Jamming for Covert Communications
Jan 19, 2021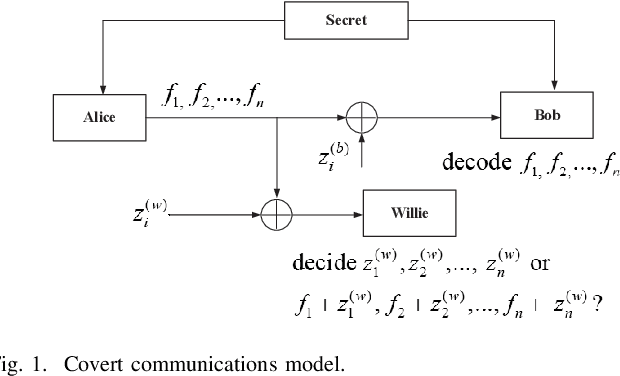
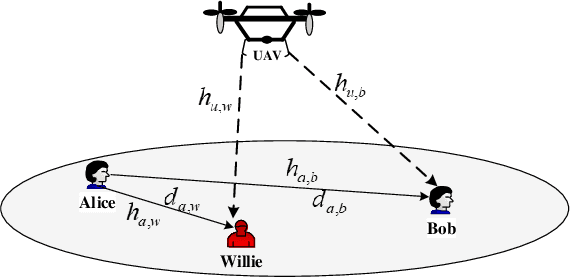
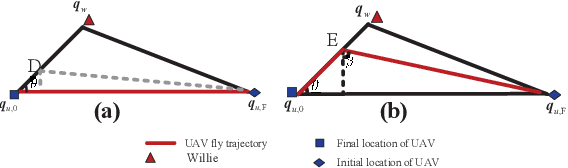
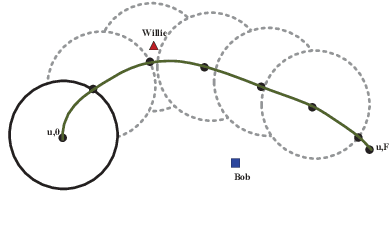
In this paper a novel unmanned aerial vehicle aided (UAV) cooperative jamming scheme is proposed for covert communications. We first analyze the detection performance of the system to obtain the minimum error detection probability of the eavesdropper and then determine the transmission rate as the objective function by analyzing the transmission outage probability of the communication. The problem formulate is non-convex that is difficult to solve. To solve this, two efficient algorithms are proposed for general signal to interference plus noise ratio (SINR) and high SINR, respectively. The first algorithm applying the block coordinate descent (BCD) to decompose the problem into two subproblems and then solve them by successive convex approximation (SCA). For the second algorithm, we use a geometric method(GM) based on the Apollonius of Sphere to solve the optimization problem. The proposed scheme can enhance the covert performance significantly. Simulations verify that the proposed joint design can enhance the covert transmission rate of the considered system as compared to the benchmark schemes.
Forecasting Future Humphrey Visual Fields Using Deep Learning
Apr 02, 2018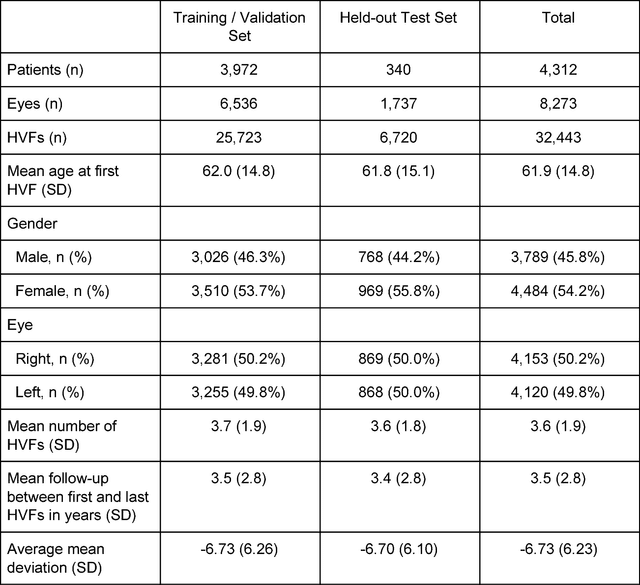
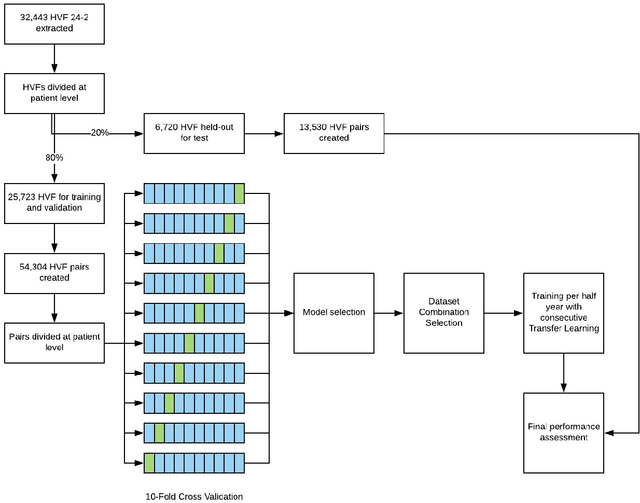

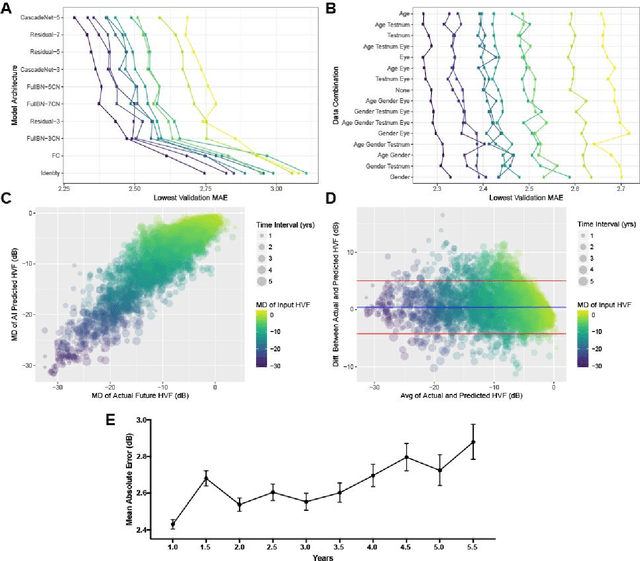
Purpose: To determine if deep learning networks could be trained to forecast a future 24-2 Humphrey Visual Field (HVF). Participants: All patients who obtained a HVF 24-2 at the University of Washington. Methods: All datapoints from consecutive 24-2 HVFs from 1998 to 2018 were extracted from a University of Washington database. Ten-fold cross validation with a held out test set was used to develop the three main phases of model development: model architecture selection, dataset combination selection, and time-interval model training with transfer learning, to train a deep learning artificial neural network capable of generating a point-wise visual field prediction. Results: More than 1.7 million perimetry points were extracted to the hundredth decibel from 32,443 24-2 HVFs. The best performing model with 20 million trainable parameters, CascadeNet-5, was selected. The overall MAE for the test set was 2.47 dB (95% CI: 2.45 dB to 2.48 dB). The 100 fully trained models were able to successfully predict progressive field loss in glaucomatous eyes up to 5.5 years in the future with a correlation of 0.92 between the MD of predicted and actual future HVF (p < 2.2 x 10 -16 ) and an average difference of 0.41 dB. Conclusions: Using unfiltered real-world datasets, deep learning networks show an impressive ability to not only learn spatio-temporal HVF changes but also to generate predictions for future HVFs up to 5.5 years, given only a single HVF.