 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Foundation Models for Clinical Data
Apr 05, 2026Healthcare foundation models have largely followed paradigms from natural language processing and computer vision, emphasizing large scale pretraining and deterministic representations over heterogeneous clinical data. However, clinical observations are inherently incomplete, reflecting sparse, irregular, and modality dependent measurements of an underlying physiologic state. In this work, we propose a framework for uncertainty aware foundation modeling that represents each patient not as a point embedding, but as a distribution over plausible latent states. By learning set valued representations and enforcing consistency across partial views of the same patient, the model captures what is invariantly inferable while explicitly encoding epistemic uncertainty. We integrate this formulation with multimodal encoders and scalable self supervised objectives, combining reconstruction, contrastive alignment, and distributional regularization. Across diverse clinical tasks, our approach improves predictive performance, robustness under missing data, and uncertainty calibration relative to strong baselines. These results suggest that modeling what is not observed rather than only what is constitutes a critical inductive bias for healthcare foundation models.
ActiveFreq: Integrating Active Learning and Frequency Domain Analysis for Interactive Segmentation
Mar 12, 2026Interactive segmentation is commonly used in medical image analysis to obtain precise, pixel-level labeling, typically involving iterative user input to correct mislabeled regions. However, existing approaches often fail to fully utilize user knowledge from interactive inputs and achieve comprehensive feature extraction. Specifically, these methods tend to treat all mislabeled regions equally, selecting them randomly for refinement without evaluating each region's potential impact on segmentation quality. Additionally, most models rely solely on spatial domain features, overlooking frequency domain information that could enhance feature extraction and improve performance. To address these limitations, we propose ActiveFreq, a novel interactive segmentation framework that integrates active learning and frequency domain analysis to minimize human intervention while achieving high-quality labeling. ActiveFreq introduces AcSelect, an autonomous module that prioritizes the most informative mislabeled regions, ensuring maximum performance gain from each click. Moreover, we develop FreqFormer, a segmentation backbone incorporating a Fourier transform module to map features from the spatial to the frequency domain, enabling richer feature extraction. Evaluations on the ISIC-2017 and OAI-ZIB datasets demonstrate that ActiveFreq achieves high performance with reduced user interaction, achieving 3.74 NoC@90 on ISIC-2017 and 9.27 NoC@90 on OAI-ZIB, with 23.5% and 12.8% improvements over previous best results, respectively. Under minimal input conditions, such as two clicks, ActiveFreq reaches mIoU scores of 85.29% and 75.76% on ISIC-2017 and OAI-ZIB, highlighting its efficiency and accuracy in interactive medical segmentation.
* 16 pages, 8 figures, published in Knowledge-Based Systems
PlayWrite: A Multimodal System for AI Supported Narrative Co-Authoring Through Play in XR
Mar 02, 2026Current AI writing tools, which rely on text prompts, poorly support the spatial and interactive nature of storytelling where ideas emerge from direct manipulation and play. We present PlayWrite, a mixed-reality system where users author stories by directly manipulating virtual characters and props. A multi-agent AI pipeline interprets these actions into Intent Frames -structured narrative beats visualized as rearrangeable story marbles on a timeline. A large language model then transforms the user's assembled sequence into a final narrative. A user study (N=13) with writers from varying domains found that PlayWrite fosters a highly improvisational and playful process. Users treated the AI as a collaborative partner, using its unexpected responses to spark new ideas and overcome creative blocks. PlayWrite demonstrates an approach for co-creative systems that move beyond text to embrace direct manipulation and play as core interaction modalities.
Global Regulation and Excitation via Attention Tuning for Stereo Matching
Sep 19, 2025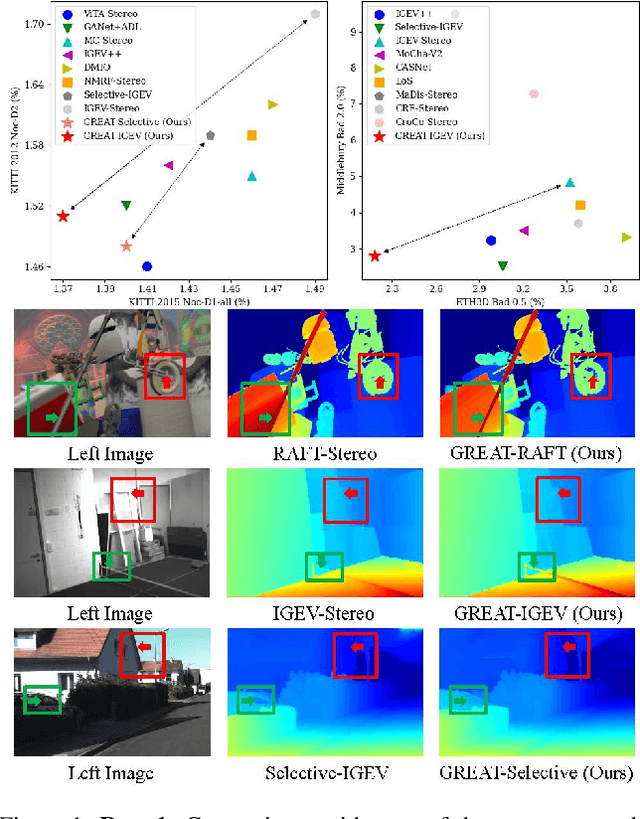
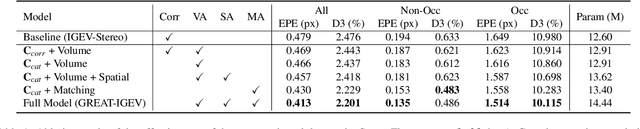
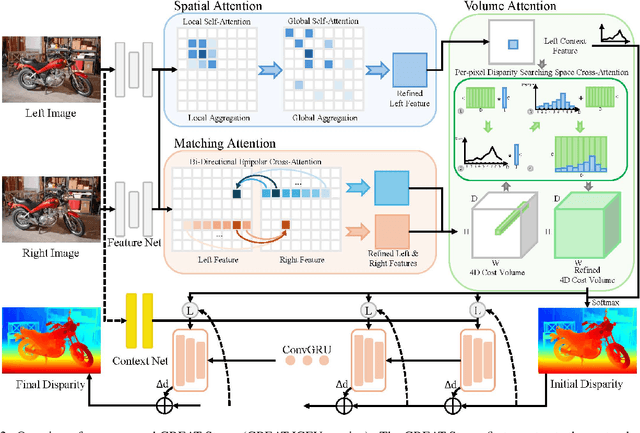
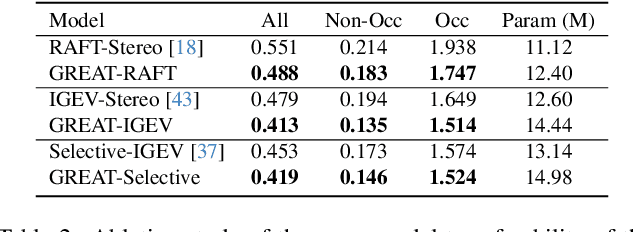
Stereo matching achieves significant progress with iterative algorithms like RAFT-Stereo and IGEV-Stereo. However, these methods struggle in ill-posed regions with occlusions, textureless, or repetitive patterns, due to a lack of global context and geometric information for effective iterative refinement. To enable the existing iterative approaches to incorporate global context, we propose the Global Regulation and Excitation via Attention Tuning (GREAT) framework which encompasses three attention modules. Specifically, Spatial Attention (SA) captures the global context within the spatial dimension, Matching Attention (MA) extracts global context along epipolar lines, and Volume Attention (VA) works in conjunction with SA and MA to construct a more robust cost-volume excited by global context and geometric details. To verify the universality and effectiveness of this framework, we integrate it into several representative iterative stereo-matching methods and validate it through extensive experiments, collectively denoted as GREAT-Stereo. This framework demonstrates superior performance in challenging ill-posed regions. Applied to IGEV-Stereo, among all published methods, our GREAT-IGEV ranks first on the Scene Flow test set, KITTI 2015, and ETH3D leaderboards, and achieves second on the Middlebury benchmark. Code is available at https://github.com/JarvisLee0423/GREAT-Stereo.
Exploring Generalized Gait Recognition: Reducing Redundancy and Noise within Indoor and Outdoor Datasets
May 21, 2025Generalized gait recognition, which aims to achieve robust performance across diverse domains, remains a challenging problem due to severe domain shifts in viewpoints, appearances, and environments. While mixed-dataset training is widely used to enhance generalization, it introduces new obstacles including inter-dataset optimization conflicts and redundant or noisy samples, both of which hinder effective representation learning. To address these challenges, we propose a unified framework that systematically improves cross-domain gait recognition. First, we design a disentangled triplet loss that isolates supervision signals across datasets, mitigating gradient conflicts during optimization. Second, we introduce a targeted dataset distillation strategy that filters out the least informative 20\% of training samples based on feature redundancy and prediction uncertainty, enhancing data efficiency. Extensive experiments on CASIA-B, OU-MVLP, Gait3D, and GREW demonstrate that our method significantly improves cross-dataset recognition for both GaitBase and DeepGaitV2 backbones, without sacrificing source-domain accuracy. Code will be released at https://github.com/li1er3/Generalized_Gait.
WhatELSE: Shaping Narrative Spaces at Configurable Level of Abstraction for AI-bridged Interactive Storytelling
Feb 25, 2025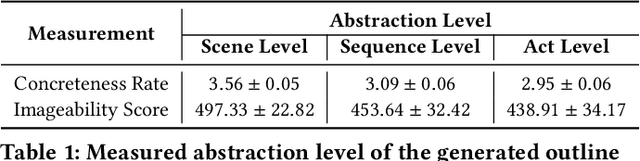
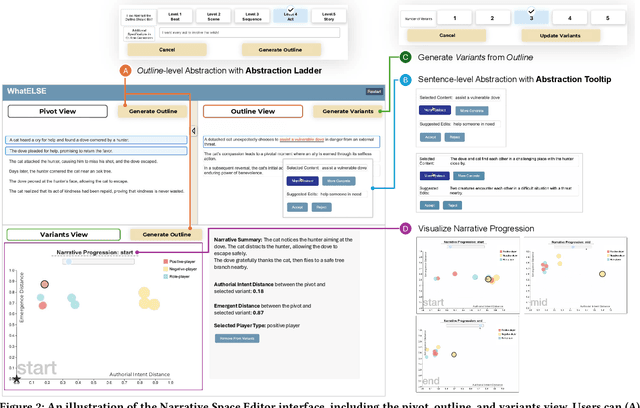

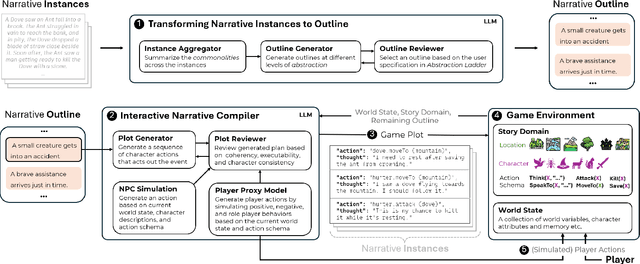
Generative AI significantly enhances player agency in interactive narratives (IN) by enabling just-in-time content generation that adapts to player actions. While delegating generation to AI makes IN more interactive, it becomes challenging for authors to control the space of possible narratives - within which the final story experienced by the player emerges from their interaction with AI. In this paper, we present WhatELSE, an AI-bridged IN authoring system that creates narrative possibility spaces from example stories. WhatELSE provides three views (narrative pivot, outline, and variants) to help authors understand the narrative space and corresponding tools leveraging linguistic abstraction to control the boundaries of the narrative space. Taking innovative LLM-based narrative planning approaches, WhatELSE further unfolds the narrative space into executable game events. Through a user study (N=12) and technical evaluations, we found that WhatELSE enables authors to perceive and edit the narrative space and generates engaging interactive narratives at play-time.
Enhanced Photovoltaic Power Forecasting: An iTransformer and LSTM-Based Model Integrating Temporal and Covariate Interactions
Dec 03, 2024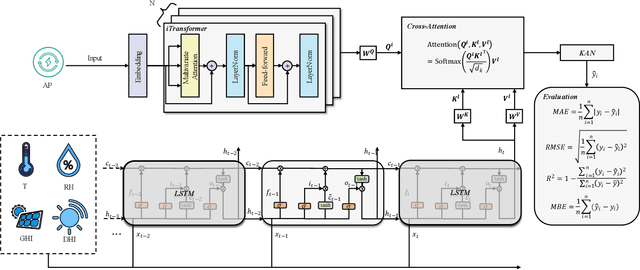
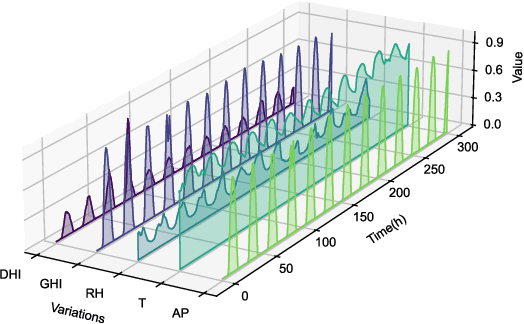
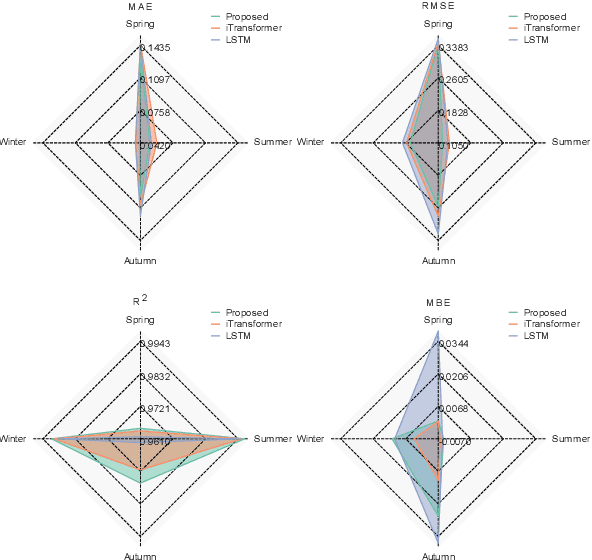

Accurate photovoltaic (PV) power forecasting is critical for integrating renewable energy sources into the grid, optimizing real-time energy management, and ensuring energy reliability amidst increasing demand. However, existing models often struggle with effectively capturing the complex relationships between target variables and covariates, as well as the interactions between temporal dynamics and multivariate data, leading to suboptimal forecasting accuracy. To address these challenges, we propose a novel model architecture that leverages the iTransformer for feature extraction from target variables and employs long short-term memory (LSTM) to extract features from covariates. A cross-attention mechanism is integrated to fuse the outputs of both models, followed by a Kolmogorov-Arnold network (KAN) mapping for enhanced representation. The effectiveness of the proposed model is validated using publicly available datasets from Australia, with experiments conducted across four seasons. Results demonstrate that the proposed model effectively capture seasonal variations in PV power generation and improve forecasting accuracy.
Pseudo Dataset Generation for Out-of-Domain Multi-Camera View Recommendation
Oct 17, 2024



Multi-camera systems are indispensable in movies, TV shows, and other media. Selecting the appropriate camera at every timestamp has a decisive impact on production quality and audience preferences. Learning-based view recommendation frameworks can assist professionals in decision-making. However, they often struggle outside of their training domains. The scarcity of labeled multi-camera view recommendation datasets exacerbates the issue. Based on the insight that many videos are edited from the original multi-camera videos, we propose transforming regular videos into pseudo-labeled multi-camera view recommendation datasets. Promisingly, by training the model on pseudo-labeled datasets stemming from videos in the target domain, we achieve a 68% relative improvement in the model's accuracy in the target domain and bridge the accuracy gap between in-domain and never-before-seen domains.
StoryVerse: Towards Co-authoring Dynamic Plot with LLM-based Character Simulation via Narrative Planning
May 17, 2024


Automated plot generation for games enhances the player's experience by providing rich and immersive narrative experience that adapts to the player's actions. Traditional approaches adopt a symbolic narrative planning method which limits the scale and complexity of the generated plot by requiring extensive knowledge engineering work. Recent advancements use Large Language Models (LLMs) to drive the behavior of virtual characters, allowing plots to emerge from interactions between characters and their environments. However, the emergent nature of such decentralized plot generation makes it difficult for authors to direct plot progression. We propose a novel plot creation workflow that mediates between a writer's authorial intent and the emergent behaviors from LLM-driven character simulation, through a novel authorial structure called "abstract acts". The writers define high-level plot outlines that are later transformed into concrete character action sequences via an LLM-based narrative planning process, based on the game world state. The process creates "living stories" that dynamically adapt to various game world states, resulting in narratives co-created by the author, character simulation, and player. We present StoryVerse as a proof-of-concept system to demonstrate this plot creation workflow. We showcase the versatility of our approach with examples in different stories and game environments.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.