 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMean Flow Distillation: Robust and Stable Distillation for Flow Matching Models
Jun 09, 2026Flow Matching models have demonstrated strong performance across a wide range of generative tasks. However, their reliance on ODE-based iterative sampling incurs substantial computational overhead in inference, which limits their applicability in real-time scenes. While distillation is a promising solution, existing approaches largely borrow from diffusion-based score matching, often failing to exploit the intrinsic geometric structure of flows and suffering from training instability, high variance, and degraded generation quality. In this paper, we propose Mean Flow Distillation (MFD), a novel distillation framework tailored for flow matching models. We theoretically demonstrate that MFD acts as a temporal low-pass filter, effectively suppressing the high-frequency optimization noise inherent in variational score distillation (VSD) while ensuring global trajectory consistency. We further prove the Mean Flow Matching Theorem, establishing that matching expected average velocities is sufficient for strict distribution alignment. Empirically, on challenging tasks of high-dimensional manifolds including 4D occupancy forecasting and text-to-image generation, MFD achieves state-of-the-art performance, enabling high-fidelity single-step generation.
LLM enhanced graph inference for long-term disease progression modelling
Nov 14, 2025Understanding the interactions between biomarkers among brain regions during neurodegenerative disease is essential for unravelling the mechanisms underlying disease progression. For example, pathophysiological models of Alzheimer's Disease (AD) typically describe how variables, such as regional levels of toxic proteins, interact spatiotemporally within a dynamical system driven by an underlying biological substrate, often based on brain connectivity. However, current methods grossly oversimplify the complex relationship between brain connectivity by assuming a single-modality brain connectome as the disease-spreading substrate. This leads to inaccurate predictions of pathology spread, especially during the long-term progression period. Meanhwile, other methods of learning such a graph in a purely data-driven way face the identifiability issue due to lack of proper constraint. We thus present a novel framework that uses Large Language Models (LLMs) as expert guides on the interaction of regional variables to enhance learning of disease progression from irregularly sampled longitudinal patient data. By leveraging LLMs' ability to synthesize multi-modal relationships and incorporate diverse disease-driving mechanisms, our method simultaneously optimizes 1) the construction of long-term disease trajectories from individual-level observations and 2) the biologically-constrained graph structure that captures interactions among brain regions with better identifiability. We demonstrate the new approach by estimating the pathology propagation using tau-PET imaging data from an Alzheimer's disease cohort. The new framework demonstrates superior prediction accuracy and interpretability compared to traditional approaches while revealing additional disease-driving factors beyond conventional connectivity measures.
BSGS: Bi-stage 3D Gaussian Splatting for Camera Motion Deblurring
Oct 14, 20253D Gaussian Splatting has exhibited remarkable capabilities in 3D scene reconstruction.However, reconstructing high-quality 3D scenes from motion-blurred images caused by camera motion poses a significant challenge.The performance of existing 3DGS-based deblurring methods are limited due to their inherent mechanisms, such as extreme dependence on the accuracy of camera poses and inability to effectively control erroneous Gaussian primitives densification caused by motion blur.To solve these problems, we introduce a novel framework, Bi-Stage 3D Gaussian Splatting, to accurately reconstruct 3D scenes from motion-blurred images.BSGS contains two stages. First, Camera Pose Refinement roughly optimizes camera poses to reduce motion-induced distortions. Second, with fixed rough camera poses, Global RigidTransformation further corrects motion-induced blur distortions.To alleviate multi-subframe gradient conflicts, we propose a subframe gradient aggregation strategy to optimize both stages.Furthermore, a space-time bi-stage optimization strategy is introduced to dynamically adjust primitive densification thresholds and prevent premature noisy Gaussian generation in blurred regions. Comprehensive experiments verify the effectiveness of our proposed deblurring method and show its superiority over the state of the arts.
A Stage-Aware Mixture of Experts Framework for Neurodegenerative Disease Progression Modelling
Aug 09, 2025The long-term progression of neurodegenerative diseases is commonly conceptualized as a spatiotemporal diffusion process that consists of a graph diffusion process across the structural brain connectome and a localized reaction process within brain regions. However, modeling this progression remains challenging due to 1) the scarcity of longitudinal data obtained through irregular and infrequent subject visits and 2) the complex interplay of pathological mechanisms across brain regions and disease stages, where traditional models assume fixed mechanisms throughout disease progression. To address these limitations, we propose a novel stage-aware Mixture of Experts (MoE) framework that explicitly models how different contributing mechanisms dominate at different disease stages through time-dependent expert weighting.Data-wise, we utilize an iterative dual optimization method to properly estimate the temporal position of individual observations, constructing a co hort-level progression trajectory from irregular snapshots. Model-wise, we enhance the spatial component with an inhomogeneous graph neural diffusion model (IGND) that allows diffusivity to vary based on node states and time, providing more flexible representations of brain networks. We also introduce a localized neural reaction module to capture complex dynamics beyond standard processes.The resulting IGND-MoE model dynamically integrates these components across temporal states, offering a principled way to understand how stage-specific pathological mechanisms contribute to progression. The stage-wise weights yield novel clinical insights that align with literature, suggesting that graph-related processes are more influential at early stages, while other unknown physical processes become dominant later on.
Diffusion Distillation With Direct Preference Optimization For Efficient 3D LiDAR Scene Completion
Apr 16, 2025The application of diffusion models in 3D LiDAR scene completion is limited due to diffusion's slow sampling speed. Score distillation accelerates diffusion sampling but with performance degradation, while post-training with direct policy optimization (DPO) boosts performance using preference data. This paper proposes Distillation-DPO, a novel diffusion distillation framework for LiDAR scene completion with preference aligment. First, the student model generates paired completion scenes with different initial noises. Second, using LiDAR scene evaluation metrics as preference, we construct winning and losing sample pairs. Such construction is reasonable, since most LiDAR scene metrics are informative but non-differentiable to be optimized directly. Third, Distillation-DPO optimizes the student model by exploiting the difference in score functions between the teacher and student models on the paired completion scenes. Such procedure is repeated until convergence. Extensive experiments demonstrate that, compared to state-of-the-art LiDAR scene completion diffusion models, Distillation-DPO achieves higher-quality scene completion while accelerating the completion speed by more than 5-fold. Our method is the first to explore adopting preference learning in distillation to the best of our knowledge and provide insights into preference-aligned distillation. Our code is public available on https://github.com/happyw1nd/DistillationDPO.
4D VQ-GAN: Synthesising Medical Scans at Any Time Point for Personalised Disease Progression Modelling of Idiopathic Pulmonary Fibrosis
Feb 08, 2025Understanding the progression trajectories of diseases is crucial for early diagnosis and effective treatment planning. This is especially vital for life-threatening conditions such as Idiopathic Pulmonary Fibrosis (IPF), a chronic, progressive lung disease with a prognosis comparable to many cancers. Computed tomography (CT) imaging has been established as a reliable diagnostic tool for IPF. Accurately predicting future CT scans of early-stage IPF patients can aid in developing better treatment strategies, thereby improving survival outcomes. In this paper, we propose 4D Vector Quantised Generative Adversarial Networks (4D-VQ-GAN), a model capable of generating realistic CT volumes of IPF patients at any time point. The model is trained using a two-stage approach. In the first stage, a 3D-VQ-GAN is trained to reconstruct CT volumes. In the second stage, a Neural Ordinary Differential Equation (ODE) based temporal model is trained to capture the temporal dynamics of the quantised embeddings generated by the encoder in the first stage. We evaluate different configurations of our model for generating longitudinal CT scans and compare the results against ground truth data, both quantitatively and qualitatively. For validation, we conduct survival analysis using imaging biomarkers derived from generated CT scans and achieve a C-index comparable to that of biomarkers derived from the real CT scans. The survival analysis results demonstrate the potential clinical utility inherent to generated longitudinal CT scans, showing that they can reliably predict survival outcomes.
Distilling Diffusion Models to Efficient 3D LiDAR Scene Completion
Dec 04, 2024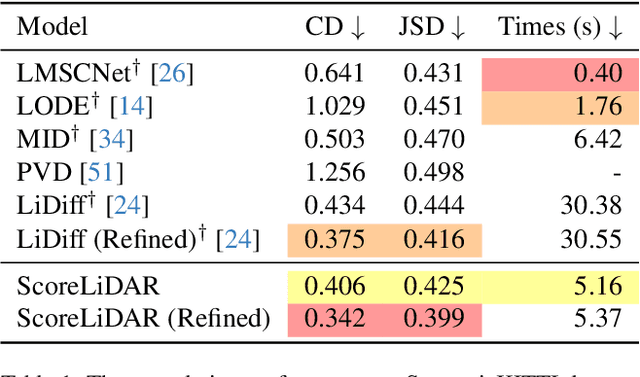
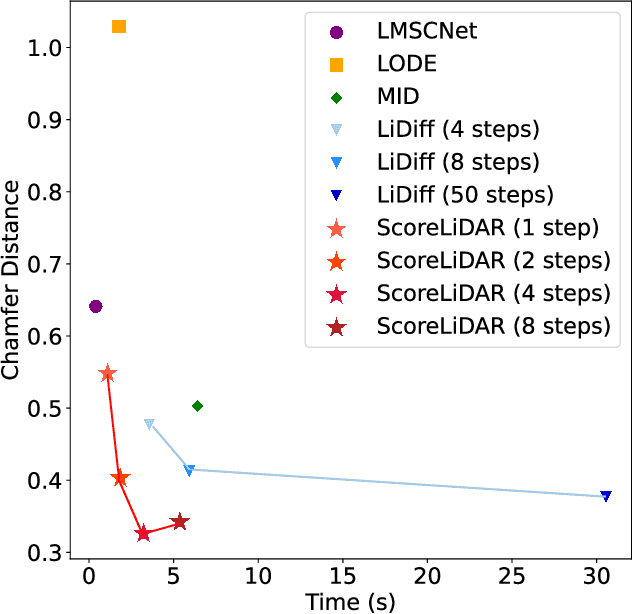
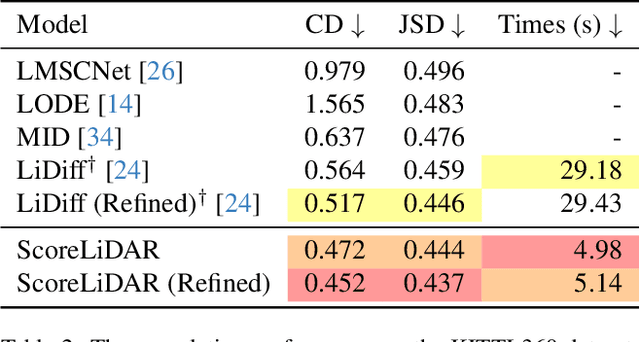
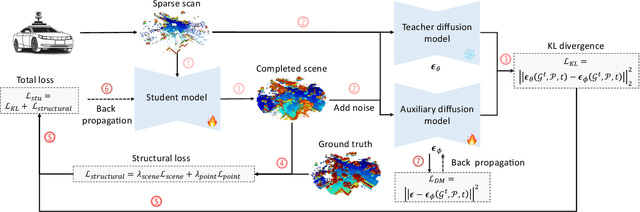
Diffusion models have been applied to 3D LiDAR scene completion due to their strong training stability and high completion quality. However, the slow sampling speed limits the practical application of diffusion-based scene completion models since autonomous vehicles require an efficient perception of surrounding environments. This paper proposes a novel distillation method tailored for 3D LiDAR scene completion models, dubbed $\textbf{ScoreLiDAR}$, which achieves efficient yet high-quality scene completion. ScoreLiDAR enables the distilled model to sample in significantly fewer steps after distillation. To improve completion quality, we also introduce a novel $\textbf{Structural Loss}$, which encourages the distilled model to capture the geometric structure of the 3D LiDAR scene. The loss contains a scene-wise term constraining the holistic structure and a point-wise term constraining the key landmark points and their relative configuration. Extensive experiments demonstrate that ScoreLiDAR significantly accelerates the completion time from 30.55 to 5.37 seconds per frame ($>$5$\times$) on SemanticKITTI and achieves superior performance compared to state-of-the-art 3D LiDAR scene completion models. Our code is publicly available at https://github.com/happyw1nd/ScoreLiDAR.
Distribution Backtracking Builds A Faster Convergence Trajectory for One-step Diffusion Distillation
Aug 28, 2024



Accelerating the sampling speed of diffusion models remains a significant challenge. Recent score distillation methods distill a heavy teacher model into an one-step student generator, which is optimized by calculating the difference between the two score functions on the samples generated by the student model. However, there is a score mismatch issue in the early stage of the distillation process, because existing methods mainly focus on using the endpoint of pre-trained diffusion models as teacher models, overlooking the importance of the convergence trajectory between the student generator and the teacher model. To address this issue, we extend the score distillation process by introducing the entire convergence trajectory of teacher models and propose Distribution Backtracking Distillation (DisBack) for distilling student generators. DisBask is composed of two stages: Degradation Recording and Distribution Backtracking. Degradation Recording is designed to obtain the convergence trajectory of teacher models, which records the degradation path from the trained teacher model to the untrained initial student generator. The degradation path implicitly represents the intermediate distributions of teacher models. Then Distribution Backtracking trains a student generator to backtrack the intermediate distributions for approximating the convergence trajectory of teacher models. Extensive experiments show that DisBack achieves faster and better convergence than the existing distillation method and accomplishes comparable generation performance. Notably, DisBack is easy to implement and can be generalized to existing distillation methods to boost performance. Our code is publicly available on https://github.com/SYZhang0805/DisBack.
CenTime: Event-Conditional Modelling of Censoring in Survival Analysis
Sep 15, 2023Survival analysis is a valuable tool for estimating the time until specific events, such as death or cancer recurrence, based on baseline observations. This is particularly useful in healthcare to prognostically predict clinically important events based on patient data. However, existing approaches often have limitations; some focus only on ranking patients by survivability, neglecting to estimate the actual event time, while others treat the problem as a classification task, ignoring the inherent time-ordered structure of the events. Furthermore, the effective utilization of censored samples - training data points where the exact event time is unknown - is essential for improving the predictive accuracy of the model. In this paper, we introduce CenTime, a novel approach to survival analysis that directly estimates the time to event. Our method features an innovative event-conditional censoring mechanism that performs robustly even when uncensored data is scarce. We demonstrate that our approach forms a consistent estimator for the event model parameters, even in the absence of uncensored data. Furthermore, CenTime is easily integrated with deep learning models with no restrictions on batch size or the number of uncensored samples. We compare our approach with standard survival analysis methods, including the Cox proportional-hazard model and DeepHit. Our results indicate that CenTime offers state-of-the-art performance in predicting time-to-death while maintaining comparable ranking performance. Our implementation is publicly available at https://github.com/ahmedhshahin/CenTime.
A data-centric deep learning approach to airway segmentation
Jul 29, 2023The morphology and distribution of airway tree abnormalities enables diagnosis and disease characterisation across a variety of chronic respiratory conditions. In this regard, airway segmentation plays a critical role in the production of the outline of the entire airway tree to enable estimation of disease extent and severity. In this study, we propose a data-centric deep learning technique to segment the airway tree. The proposed technique utilises interpolation and image split to improve data usefulness and quality. Then, an ensemble learning strategy is implemented to aggregate the segmented airway trees at different scales. In terms of segmentation performance (dice similarity coefficient), our method outperforms the baseline model by 2.5% on average when a combined loss is used. Further, our proposed technique has a low GPU usage and high flexibility enabling it to be deployed on any 2D deep learning model.