 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMargin-Based Transfer Bounds for Meta Learning with Deep Feature Embedding
Dec 02, 2020
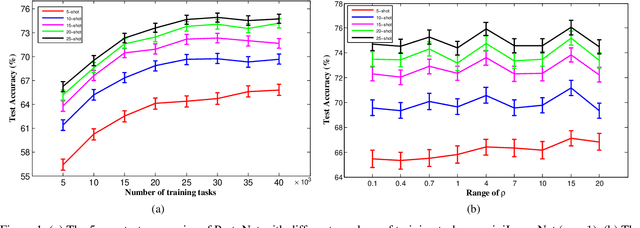

By transferring knowledge learned from seen/previous tasks, meta learning aims to generalize well to unseen/future tasks. Existing meta-learning approaches have shown promising empirical performance on various multiclass classification problems, but few provide theoretical analysis on the classifiers' generalization ability on future tasks. In this paper, under the assumption that all classification tasks are sampled from the same meta-distribution, we leverage margin theory and statistical learning theory to establish three margin-based transfer bounds for meta-learning based multiclass classification (MLMC). These bounds reveal that the expected error of a given classification algorithm for a future task can be estimated with the average empirical error on a finite number of previous tasks, uniformly over a class of preprocessing feature maps/deep neural networks (i.e. deep feature embeddings). To validate these bounds, instead of the commonly-used cross-entropy loss, a multi-margin loss is employed to train a number of representative MLMC models. Experiments on three benchmarks show that these margin-based models still achieve competitive performance, validating the practical value of our margin-based theoretical analysis.
Domain-Adaptive Few-Shot Learning
Mar 19, 2020
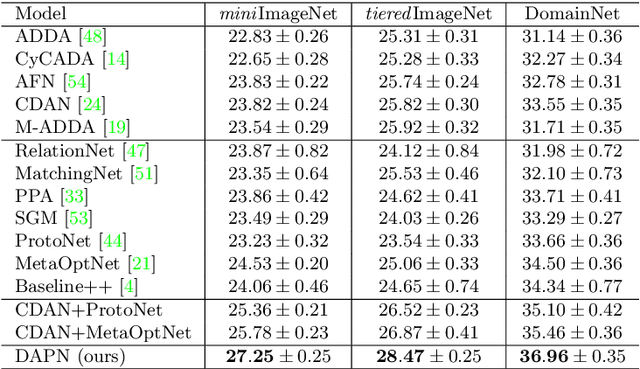

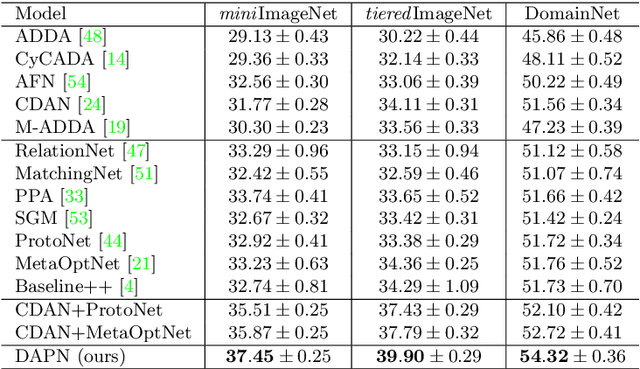
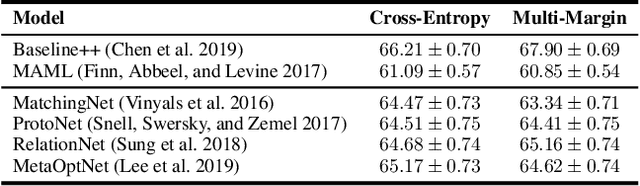
Existing few-shot learning (FSL) methods make the implicit assumption that the few target class samples are from the same domain as the source class samples. However, in practice this assumption is often invalid -- the target classes could come from a different domain. This poses an additional challenge of domain adaptation (DA) with few training samples. In this paper, the problem of domain-adaptive few-shot learning (DA-FSL) is tackled, which requires solving FSL and DA in a unified framework. To this end, we propose a novel domain-adversarial prototypical network (DAPN) model. It is designed to address a specific challenge in DA-FSL: the DA objective means that the source and target data distributions need to be aligned, typically through a shared domain-adaptive feature embedding space; but the FSL objective dictates that the target domain per class distribution must be different from that of any source domain class, meaning aligning the distributions across domains may harm the FSL performance. How to achieve global domain distribution alignment whilst maintaining source/target per-class discriminativeness thus becomes the key. Our solution is to explicitly enhance the source/target per-class separation before domain-adaptive feature embedding learning in the DAPN, in order to alleviate the negative effect of domain alignment on FSL. Extensive experiments show that our DAPN outperforms the state-of-the-art FSL and DA models, as well as their na\"ive combinations. The code is available at https://github.com/dingmyu/DAPN.
Few-Shot Learning as Domain Adaptation: Algorithm and Analysis
Feb 12, 2020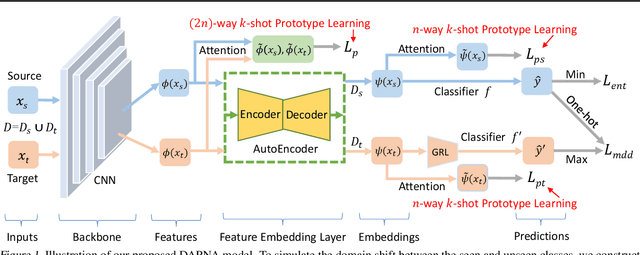
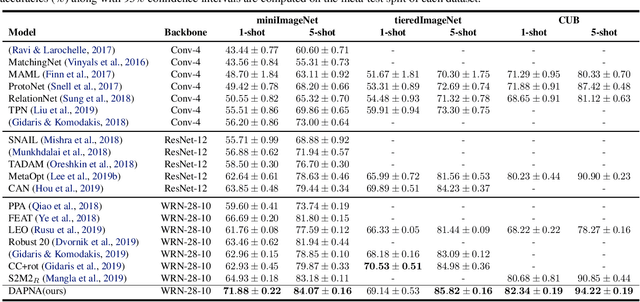
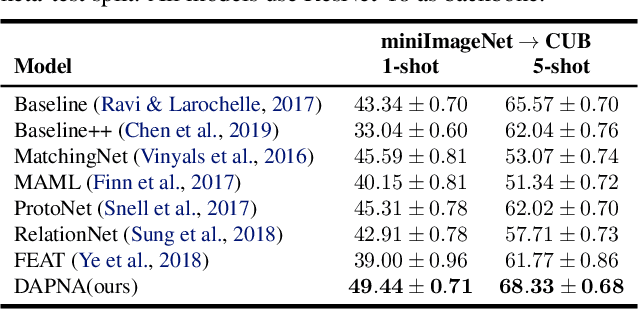
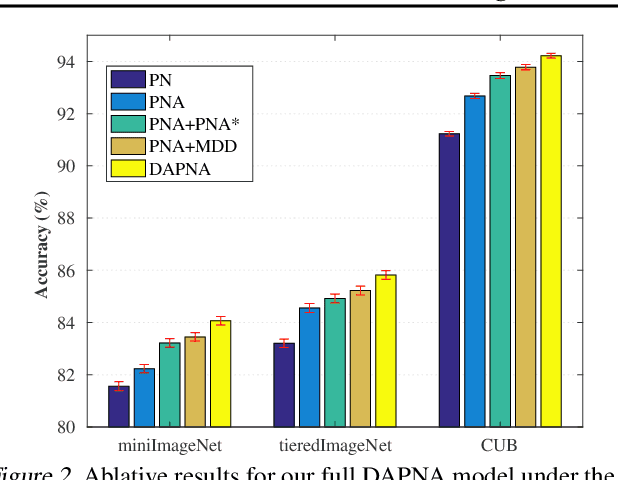
To recognize the unseen classes with only few samples, few-shot learning (FSL) uses prior knowledge learned from the seen classes. A major challenge for FSL is that the distribution of the unseen classes is different from that of those seen, resulting in poor generalization even when a model is meta-trained on the seen classes. This class-difference-caused distribution shift can be considered as a special case of domain shift. In this paper, for the first time, we propose a domain adaptation prototypical network with attention (DAPNA) to explicitly tackle such a domain shift problem in a meta-learning framework. Specifically, armed with a set transformer based attention module, we construct each episode with two sub-episodes without class overlap on the seen classes to simulate the domain shift between the seen and unseen classes. To align the feature distributions of the two sub-episodes with limited training samples, a feature transfer network is employed together with a margin disparity discrepancy (MDD) loss. Importantly, theoretical analysis is provided to give the learning bound of our DAPNA. Extensive experiments show that our DAPNA outperforms the state-of-the-art FSL alternatives, often by significant margins.
Zero-Shot Learning with Sparse Attribute Propagation
Dec 11, 2018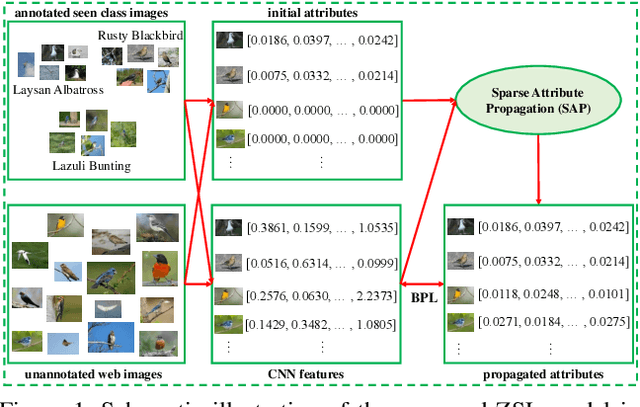
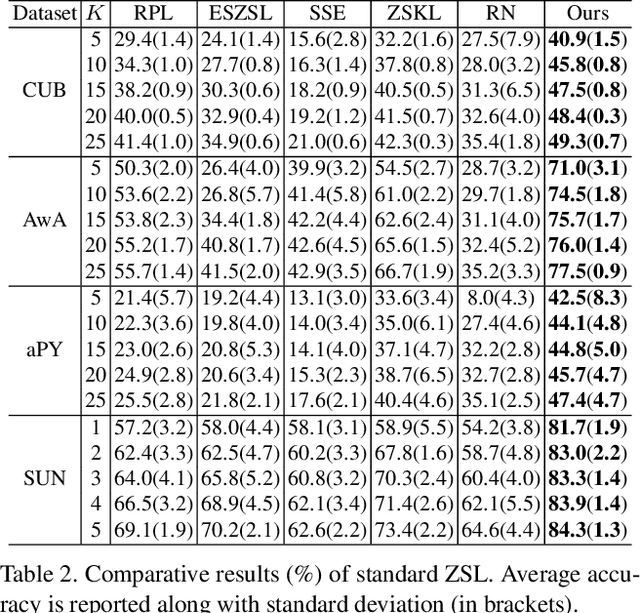

Zero-shot learning (ZSL) aims to recognize a set of unseen classes without any training images. The standard approach to ZSL requires a semantic descriptor for each class/instance, with attribute vector being the most widely used. Attribute annotation is expensive; it thus severely limits the scalability of ZSL. In this paper, we define a new ZSL setting where only a few images are annotated with attributes from each seen class. This is clearly more challenging yet more realistic than the conventional ZSL setting. To overcome the attribute sparsity under our new ZSL setting, we propose a novel inductive ZSL model termed sparse attribute propagation (SAP) by propagating attribute annotations to more unannotated images using sparse coding. This is followed by learning bidirectional projections between features and attributes for ZSL. An efficient solver is provided, together with rigorous theoretic algorithm analysis. With our SAP, we show that a ZSL training dataset can now be augmented by the abundant web images returned by image search engine, to further improve the model performance. Moreover, the general applicability of SAP is demonstrated on solving the social image annotation (SIA) problem. Extensive experiments show that our model achieves superior performance on both ZSL and SIA.
Zero and Few Shot Learning with Semantic Feature Synthesis and Competitive Learning
Oct 19, 2018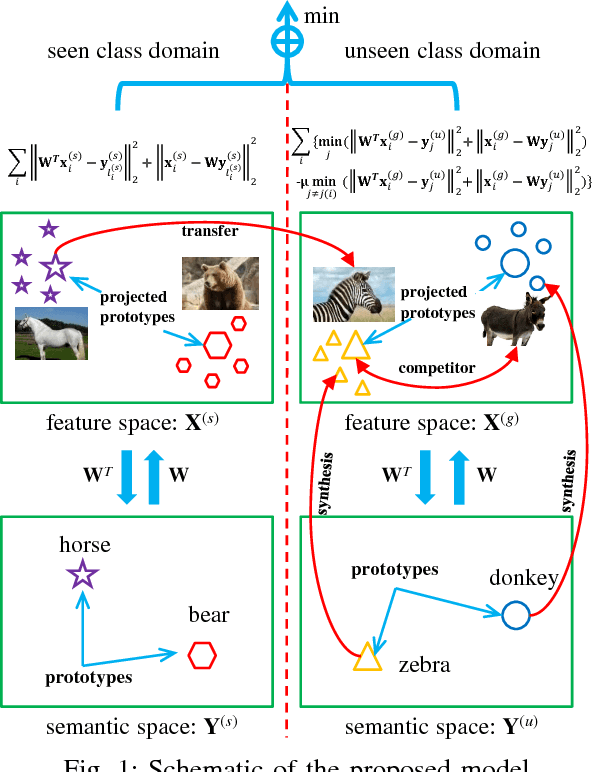
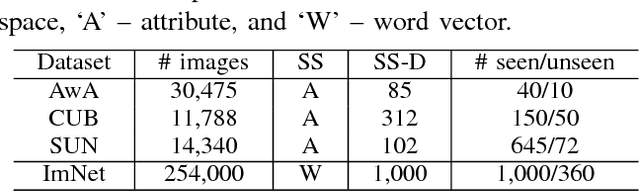
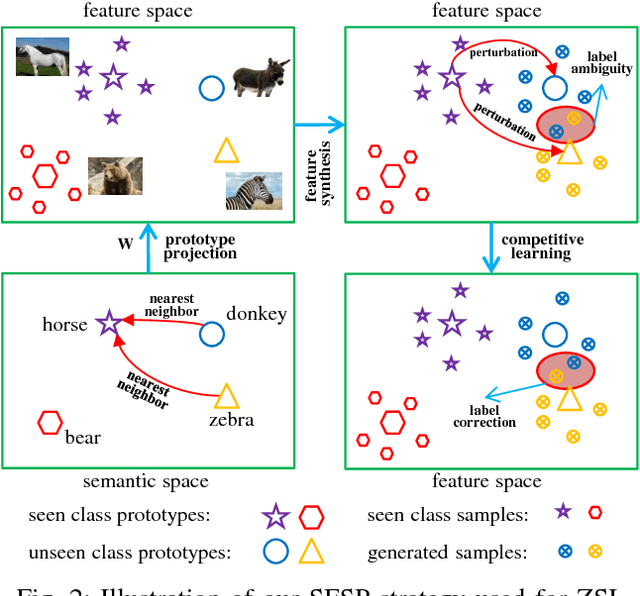
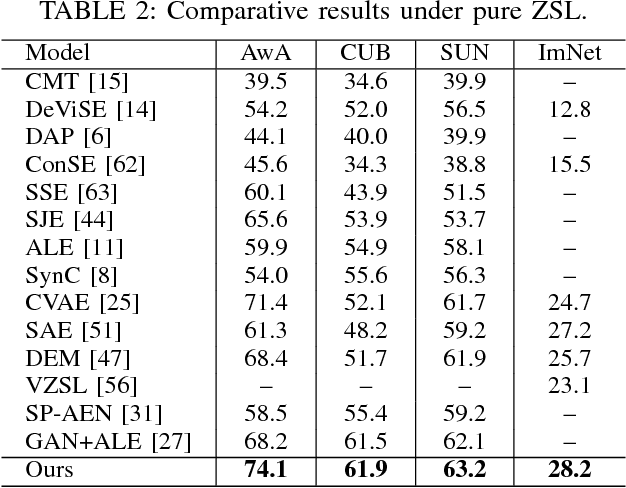
Zero-shot learning (ZSL) is made possible by learning a projection function between a feature space and a semantic space (e.g.,~an attribute space). Key to ZSL is thus to learn a projection that is robust against the often large domain gap between the seen and unseen class domains. In this work, this is achieved by unseen class data synthesis and robust projection function learning. Specifically, a novel semantic data synthesis strategy is proposed, by which semantic class prototypes (e.g., attribute vectors) are used to simply perturb seen class data for generating unseen class ones. As in any data synthesis/hallucination approach, there are ambiguities and uncertainties on how well the synthesised data can capture the targeted unseen class data distribution. To cope with this, the second contribution of this work is a novel projection learning model termed competitive bidirectional projection learning (BPL) designed to best utilise the ambiguous synthesised data. Specifically, we assume that each synthesised data point can belong to any unseen class; and the most likely two class candidates are exploited to learn a robust projection function in a competitive fashion. As a third contribution, we show that the proposed ZSL model can be easily extended to few-shot learning (FSL) by again exploiting semantic (class prototype guided) feature synthesis and competitive BPL. Extensive experiments show that our model achieves the state-of-the-art results on both problems.
Transferrable Feature and Projection Learning with Class Hierarchy for Zero-Shot Learning
Oct 19, 2018
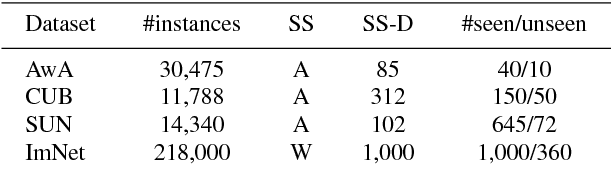
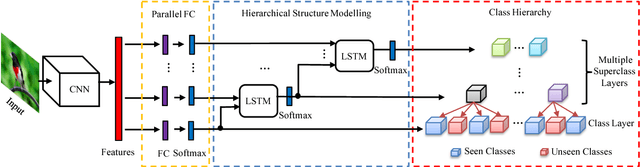
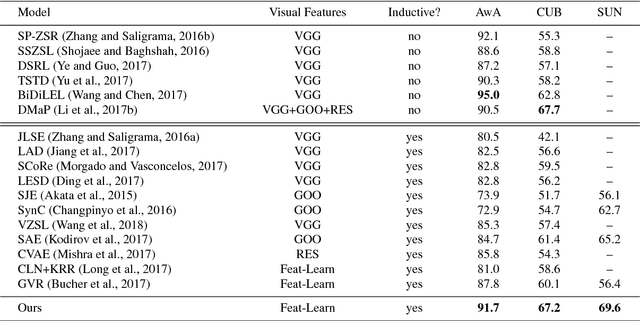
Zero-shot learning (ZSL) aims to transfer knowledge from seen classes to unseen ones so that the latter can be recognised without any training samples. This is made possible by learning a projection function between a feature space and a semantic space (e.g. attribute space). Considering the seen and unseen classes as two domains, a big domain gap often exists which challenges ZSL. Inspired by the fact that an unseen class is not exactly `unseen' if it belongs to the same superclass as a seen class, we propose a novel inductive ZSL model that leverages superclasses as the bridge between seen and unseen classes to narrow the domain gap. Specifically, we first build a class hierarchy of multiple superclass layers and a single class layer, where the superclasses are automatically generated by data-driven clustering over the semantic representations of all seen and unseen class names. We then exploit the superclasses from the class hierarchy to tackle the domain gap challenge in two aspects: deep feature learning and projection function learning. First, to narrow the domain gap in the feature space, we integrate a recurrent neural network (RNN) defined with the superclasses into a convolutional neural network (CNN), in order to enforce the superclass hierarchy. Second, to further learn a transferrable projection function for ZSL, a novel projection function learning method is proposed by exploiting the superclasses to align the two domains. Importantly, our transferrable feature and projection learning methods can be easily extended to a closely related task -- few-shot learning (FSL). Extensive experiments show that the proposed model significantly outperforms the state-of-the-art alternatives in both ZSL and FSL tasks.
Domain-Invariant Projection Learning for Zero-Shot Recognition
Oct 19, 2018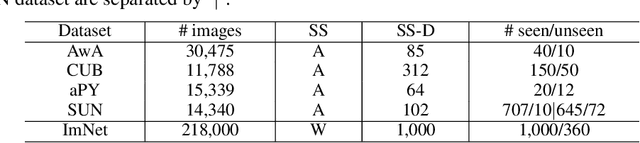
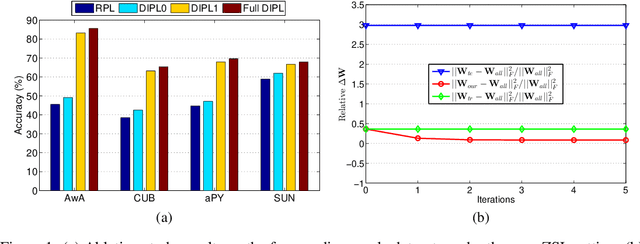
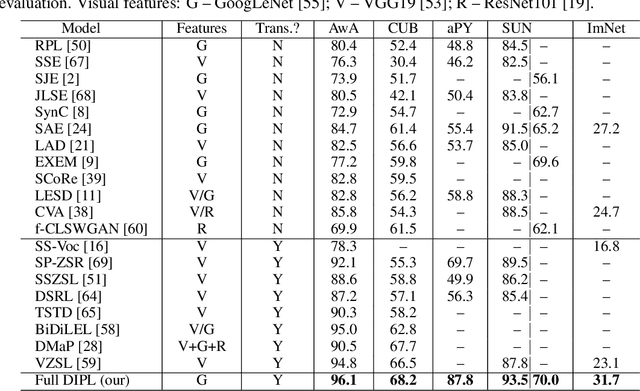
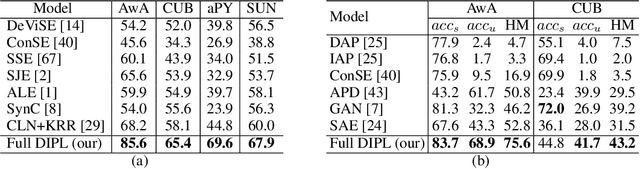
Zero-shot learning (ZSL) aims to recognize unseen object classes without any training samples, which can be regarded as a form of transfer learning from seen classes to unseen ones. This is made possible by learning a projection between a feature space and a semantic space (e.g. attribute space). Key to ZSL is thus to learn a projection function that is robust against the often large domain gap between the seen and unseen classes. In this paper, we propose a novel ZSL model termed domain-invariant projection learning (DIPL). Our model has two novel components: (1) A domain-invariant feature self-reconstruction task is introduced to the seen/unseen class data, resulting in a simple linear formulation that casts ZSL into a min-min optimization problem. Solving the problem is non-trivial, and a novel iterative algorithm is formulated as the solver, with rigorous theoretic algorithm analysis provided. (2) To further align the two domains via the learned projection, shared semantic structure among seen and unseen classes is explored via forming superclasses in the semantic space. Extensive experiments show that our model outperforms the state-of-the-art alternatives by significant margins.