 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Binary Preference: Aligning Diffusion Models to Fine-grained Criteria by Decoupling Attributes
Jan 07, 2026Post-training alignment of diffusion models relies on simplified signals, such as scalar rewards or binary preferences. This limits alignment with complex human expertise, which is hierarchical and fine-grained. To address this, we first construct a hierarchical, fine-grained evaluation criteria with domain experts, which decomposes image quality into multiple positive and negative attributes organized in a tree structure. Building on this, we propose a two-stage alignment framework. First, we inject domain knowledge to an auxiliary diffusion model via Supervised Fine-Tuning. Second, we introduce Complex Preference Optimization (CPO) that extends DPO to align the target diffusion to our non-binary, hierarchical criteria. Specifically, we reformulate the alignment problem to simultaneously maximize the probability of positive attributes while minimizing the probability of negative attributes with the auxiliary diffusion. We instantiate our approach in the domain of painting generation and conduct CPO training with an annotated dataset of painting with fine-grained attributes based on our criteria. Extensive experiments demonstrate that CPO significantly enhances generation quality and alignment with expertise, opening new avenues for fine-grained criteria alignment.
Diffusion Distillation With Direct Preference Optimization For Efficient 3D LiDAR Scene Completion
Apr 16, 2025The application of diffusion models in 3D LiDAR scene completion is limited due to diffusion's slow sampling speed. Score distillation accelerates diffusion sampling but with performance degradation, while post-training with direct policy optimization (DPO) boosts performance using preference data. This paper proposes Distillation-DPO, a novel diffusion distillation framework for LiDAR scene completion with preference aligment. First, the student model generates paired completion scenes with different initial noises. Second, using LiDAR scene evaluation metrics as preference, we construct winning and losing sample pairs. Such construction is reasonable, since most LiDAR scene metrics are informative but non-differentiable to be optimized directly. Third, Distillation-DPO optimizes the student model by exploiting the difference in score functions between the teacher and student models on the paired completion scenes. Such procedure is repeated until convergence. Extensive experiments demonstrate that, compared to state-of-the-art LiDAR scene completion diffusion models, Distillation-DPO achieves higher-quality scene completion while accelerating the completion speed by more than 5-fold. Our method is the first to explore adopting preference learning in distillation to the best of our knowledge and provide insights into preference-aligned distillation. Our code is public available on https://github.com/happyw1nd/DistillationDPO.
Syllables to Scenes: Literary-Guided Free-Viewpoint 3D Scene Synthesis from Japanese Haiku
Feb 17, 2025In the era of the metaverse, where immersive technologies redefine human experiences, translating abstract literary concepts into navigable 3D environments presents a fundamental challenge in preserving semantic and emotional fidelity. This research introduces HaikuVerse, a novel framework for transforming poetic abstraction into spatial representation, with Japanese Haiku serving as an ideal test case due to its sophisticated encapsulation of profound emotions and imagery within minimal text. While existing text-to-3D methods struggle with nuanced interpretations, we present a literary-guided approach that synergizes traditional poetry analysis with advanced generative technologies. Our framework centers on two key innovations: (1) Hierarchical Literary-Criticism Theory Grounded Parsing (H-LCTGP), which captures both explicit imagery and implicit emotional resonance through structured semantic decomposition, and (2) Progressive Dimensional Synthesis (PDS), a multi-stage pipeline that systematically transforms poetic elements into coherent 3D scenes through sequential diffusion processes, geometric optimization, and real-time enhancement. Extensive experiments demonstrate that HaikuVerse significantly outperforms conventional text-to-3D approaches in both literary fidelity and visual quality, establishing a new paradigm for preserving cultural heritage in immersive digital spaces. Project website at: https://syllables-to-scenes.github.io/
Let Human Sketches Help: Empowering Challenging Image Segmentation Task with Freehand Sketches
Jan 31, 2025



Sketches, with their expressive potential, allow humans to convey the essence of an object through even a rough contour. For the first time, we harness this expressive potential to improve segmentation performance in challenging tasks like camouflaged object detection (COD). Our approach introduces an innovative sketch-guided interactive segmentation framework, allowing users to intuitively annotate objects with freehand sketches (drawing a rough contour of the object) instead of the traditional bounding boxes or points used in classic interactive segmentation models like SAM. We demonstrate that sketch input can significantly improve performance in existing iterative segmentation methods, outperforming text or bounding box annotations. Additionally, we introduce key modifications to network architectures and a novel sketch augmentation technique to fully harness the power of sketch input and further boost segmentation accuracy. Remarkably, our model' s output can be directly used to train other neural networks, achieving results comparable to pixel-by-pixel annotations--while reducing annotation time by up to 120 times, which shows great potential in democratizing the annotation process and enabling model training with less reliance on resource-intensive, laborious pixel-level annotations. We also present KOSCamo+, the first freehand sketch dataset for camouflaged object detection. The dataset, code, and the labeling tool will be open sourced.
LAION-SG: An Enhanced Large-Scale Dataset for Training Complex Image-Text Models with Structural Annotations
Dec 11, 2024



Recent advances in text-to-image (T2I) generation have shown remarkable success in producing high-quality images from text. However, existing T2I models show decayed performance in compositional image generation involving multiple objects and intricate relationships. We attribute this problem to limitations in existing datasets of image-text pairs, which lack precise inter-object relationship annotations with prompts only. To address this problem, we construct LAION-SG, a large-scale dataset with high-quality structural annotations of scene graphs (SG), which precisely describe attributes and relationships of multiple objects, effectively representing the semantic structure in complex scenes. Based on LAION-SG, we train a new foundation model SDXL-SG to incorporate structural annotation information into the generation process. Extensive experiments show advanced models trained on our LAION-SG boast significant performance improvements in complex scene generation over models on existing datasets. We also introduce CompSG-Bench, a benchmark that evaluates models on compositional image generation, establishing a new standard for this domain.
Distilling Diffusion Models to Efficient 3D LiDAR Scene Completion
Dec 04, 2024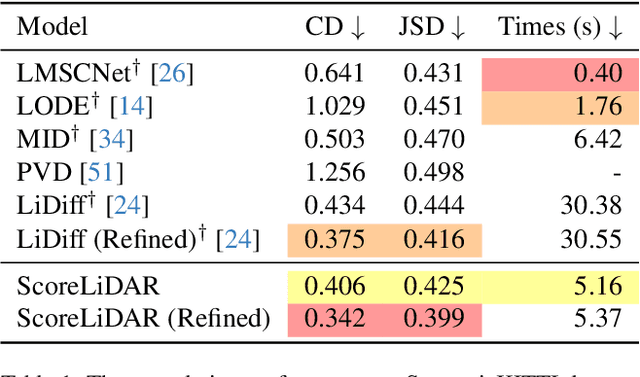
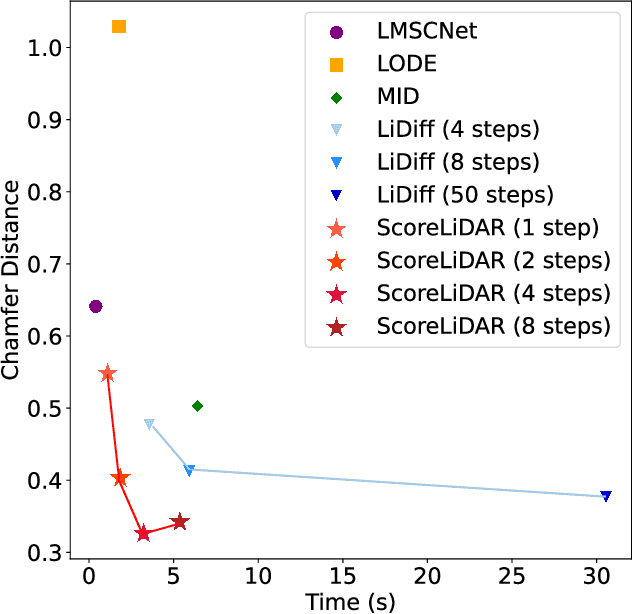
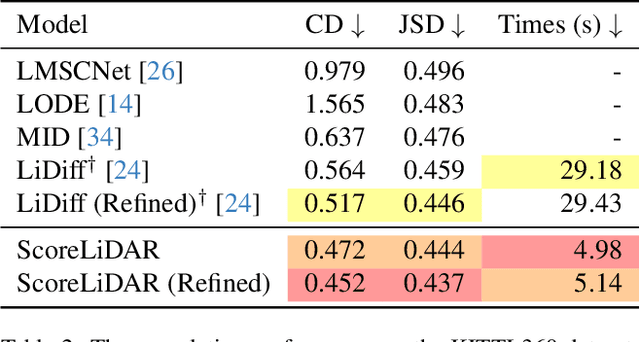
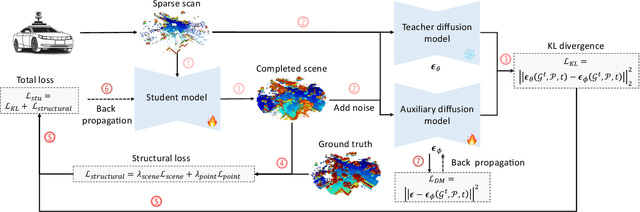
Diffusion models have been applied to 3D LiDAR scene completion due to their strong training stability and high completion quality. However, the slow sampling speed limits the practical application of diffusion-based scene completion models since autonomous vehicles require an efficient perception of surrounding environments. This paper proposes a novel distillation method tailored for 3D LiDAR scene completion models, dubbed $\textbf{ScoreLiDAR}$, which achieves efficient yet high-quality scene completion. ScoreLiDAR enables the distilled model to sample in significantly fewer steps after distillation. To improve completion quality, we also introduce a novel $\textbf{Structural Loss}$, which encourages the distilled model to capture the geometric structure of the 3D LiDAR scene. The loss contains a scene-wise term constraining the holistic structure and a point-wise term constraining the key landmark points and their relative configuration. Extensive experiments demonstrate that ScoreLiDAR significantly accelerates the completion time from 30.55 to 5.37 seconds per frame ($>$5$\times$) on SemanticKITTI and achieves superior performance compared to state-of-the-art 3D LiDAR scene completion models. Our code is publicly available at https://github.com/happyw1nd/ScoreLiDAR.
Img2CAD: Conditioned 3D CAD Model Generation from Single Image with Structured Visual Geometry
Oct 04, 2024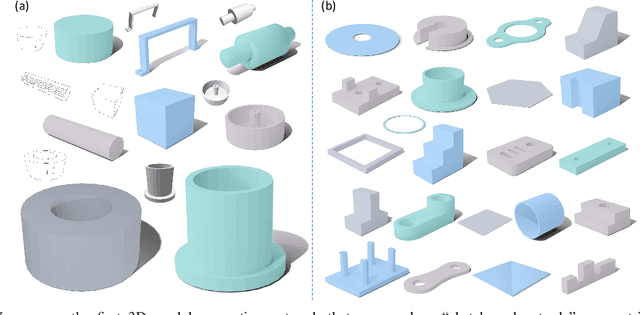
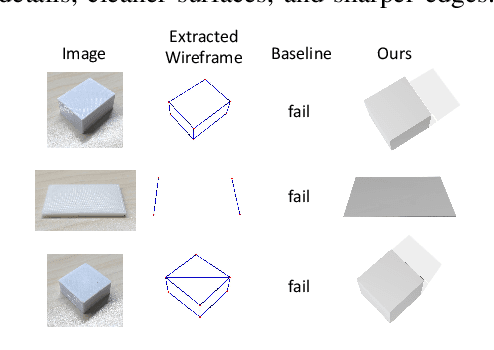


In this paper, we propose Img2CAD, the first approach to our knowledge that uses 2D image inputs to generate CAD models with editable parameters. Unlike existing AI methods for 3D model generation using text or image inputs often rely on mesh-based representations, which are incompatible with CAD tools and lack editability and fine control, Img2CAD enables seamless integration between AI-based 3D reconstruction and CAD software. We have identified an innovative intermediate representation called Structured Visual Geometry (SVG), characterized by vectorized wireframes extracted from objects. This representation significantly enhances the performance of generating conditioned CAD models. Additionally, we introduce two new datasets to further support research in this area: ABC-mono, the largest known dataset comprising over 200,000 3D CAD models with rendered images, and KOCAD, the first dataset featuring real-world captured objects alongside their ground truth CAD models, supporting further research in conditioned CAD model generation.
Distribution Backtracking Builds A Faster Convergence Trajectory for One-step Diffusion Distillation
Aug 28, 2024



Accelerating the sampling speed of diffusion models remains a significant challenge. Recent score distillation methods distill a heavy teacher model into an one-step student generator, which is optimized by calculating the difference between the two score functions on the samples generated by the student model. However, there is a score mismatch issue in the early stage of the distillation process, because existing methods mainly focus on using the endpoint of pre-trained diffusion models as teacher models, overlooking the importance of the convergence trajectory between the student generator and the teacher model. To address this issue, we extend the score distillation process by introducing the entire convergence trajectory of teacher models and propose Distribution Backtracking Distillation (DisBack) for distilling student generators. DisBask is composed of two stages: Degradation Recording and Distribution Backtracking. Degradation Recording is designed to obtain the convergence trajectory of teacher models, which records the degradation path from the trained teacher model to the untrained initial student generator. The degradation path implicitly represents the intermediate distributions of teacher models. Then Distribution Backtracking trains a student generator to backtrack the intermediate distributions for approximating the convergence trajectory of teacher models. Extensive experiments show that DisBack achieves faster and better convergence than the existing distillation method and accomplishes comparable generation performance. Notably, DisBack is easy to implement and can be generalized to existing distillation methods to boost performance. Our code is publicly available on https://github.com/SYZhang0805/DisBack.
SAM2-Adapter: Evaluating & Adapting Segment Anything 2 in Downstream Tasks: Camouflage, Shadow, Medical Image Segmentation, and More
Aug 08, 2024The advent of large models, also known as foundation models, has significantly transformed the AI research landscape, with models like Segment Anything (SAM) achieving notable success in diverse image segmentation scenarios. Despite its advancements, SAM encountered limitations in handling some complex low-level segmentation tasks like camouflaged object and medical imaging. In response, in 2023, we introduced SAM-Adapter, which demonstrated improved performance on these challenging tasks. Now, with the release of Segment Anything 2 (SAM2), a successor with enhanced architecture and a larger training corpus, we reassess these challenges. This paper introduces SAM2-Adapter, the first adapter designed to overcome the persistent limitations observed in SAM2 and achieve new state-of-the-art (SOTA) results in specific downstream tasks including medical image segmentation, camouflaged (concealed) object detection, and shadow detection. SAM2-Adapter builds on the SAM-Adapter's strengths, offering enhanced generalizability and composability for diverse applications. We present extensive experimental results demonstrating SAM2-Adapter's effectiveness. We show the potential and encourage the research community to leverage the SAM2 model with our SAM2-Adapter for achieving superior segmentation outcomes. Code, pre-trained models, and data processing protocols are available at http://tianrun-chen.github.io/SAM-Adaptor/
xLSTM-UNet can be an Effective 2D & 3D Medical Image Segmentation Backbone with Vision-LSTM (ViL) better than its Mamba Counterpart
Jul 02, 2024Convolutional Neural Networks (CNNs) and Vision Transformers (ViT) have been pivotal in biomedical image segmentation, yet their ability to manage long-range dependencies remains constrained by inherent locality and computational overhead. To overcome these challenges, in this technical report, we first propose xLSTM-UNet, a UNet structured deep learning neural network that leverages Vision-LSTM (xLSTM) as its backbone for medical image segmentation. xLSTM is a recently proposed as the successor of Long Short-Term Memory (LSTM) networks and have demonstrated superior performance compared to Transformers and State Space Models (SSMs) like Mamba in Neural Language Processing (NLP) and image classification (as demonstrated in Vision-LSTM, or ViL implementation). Here, xLSTM-UNet we designed extend the success in biomedical image segmentation domain. By integrating the local feature extraction strengths of convolutional layers with the long-range dependency capturing abilities of xLSTM, xLSTM-UNet offers a robust solution for comprehensive image analysis. We validate the efficacy of xLSTM-UNet through experiments. Our findings demonstrate that xLSTM-UNet consistently surpasses the performance of leading CNN-based, Transformer-based, and Mamba-based segmentation networks in multiple datasets in biomedical segmentation including organs in abdomen MRI, instruments in endoscopic images, and cells in microscopic images. With comprehensive experiments performed, this technical report highlights the potential of xLSTM-based architectures in advancing biomedical image analysis in both 2D and 3D. The code, models, and datasets are publicly available at http://tianrun-chen.github.io/xLSTM-UNet/