 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyllables to Scenes: Literary-Guided Free-Viewpoint 3D Scene Synthesis from Japanese Haiku
Feb 17, 2025In the era of the metaverse, where immersive technologies redefine human experiences, translating abstract literary concepts into navigable 3D environments presents a fundamental challenge in preserving semantic and emotional fidelity. This research introduces HaikuVerse, a novel framework for transforming poetic abstraction into spatial representation, with Japanese Haiku serving as an ideal test case due to its sophisticated encapsulation of profound emotions and imagery within minimal text. While existing text-to-3D methods struggle with nuanced interpretations, we present a literary-guided approach that synergizes traditional poetry analysis with advanced generative technologies. Our framework centers on two key innovations: (1) Hierarchical Literary-Criticism Theory Grounded Parsing (H-LCTGP), which captures both explicit imagery and implicit emotional resonance through structured semantic decomposition, and (2) Progressive Dimensional Synthesis (PDS), a multi-stage pipeline that systematically transforms poetic elements into coherent 3D scenes through sequential diffusion processes, geometric optimization, and real-time enhancement. Extensive experiments demonstrate that HaikuVerse significantly outperforms conventional text-to-3D approaches in both literary fidelity and visual quality, establishing a new paradigm for preserving cultural heritage in immersive digital spaces. Project website at: https://syllables-to-scenes.github.io/
Let Human Sketches Help: Empowering Challenging Image Segmentation Task with Freehand Sketches
Jan 31, 2025



Sketches, with their expressive potential, allow humans to convey the essence of an object through even a rough contour. For the first time, we harness this expressive potential to improve segmentation performance in challenging tasks like camouflaged object detection (COD). Our approach introduces an innovative sketch-guided interactive segmentation framework, allowing users to intuitively annotate objects with freehand sketches (drawing a rough contour of the object) instead of the traditional bounding boxes or points used in classic interactive segmentation models like SAM. We demonstrate that sketch input can significantly improve performance in existing iterative segmentation methods, outperforming text or bounding box annotations. Additionally, we introduce key modifications to network architectures and a novel sketch augmentation technique to fully harness the power of sketch input and further boost segmentation accuracy. Remarkably, our model' s output can be directly used to train other neural networks, achieving results comparable to pixel-by-pixel annotations--while reducing annotation time by up to 120 times, which shows great potential in democratizing the annotation process and enabling model training with less reliance on resource-intensive, laborious pixel-level annotations. We also present KOSCamo+, the first freehand sketch dataset for camouflaged object detection. The dataset, code, and the labeling tool will be open sourced.
Magic3DSketch: Create Colorful 3D Models From Sketch-Based 3D Modeling Guided by Text and Language-Image Pre-Training
Jul 27, 2024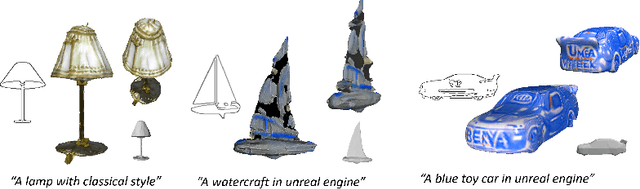
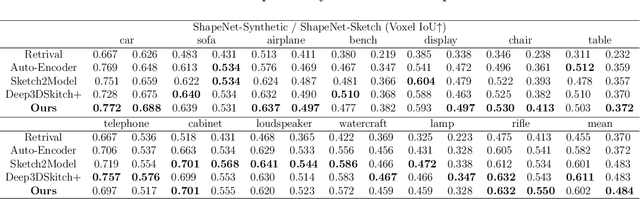
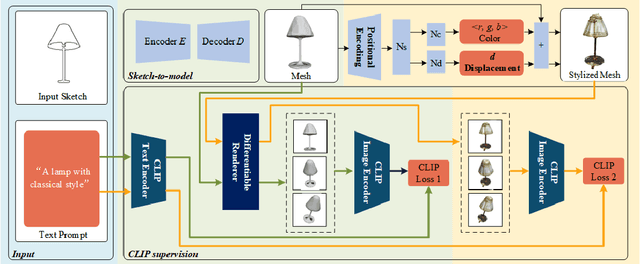
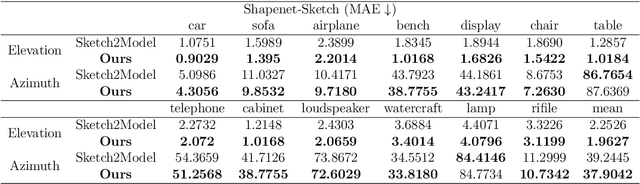
The requirement for 3D content is growing as AR/VR application emerges. At the same time, 3D modelling is only available for skillful experts, because traditional methods like Computer-Aided Design (CAD) are often too labor-intensive and skill-demanding, making it challenging for novice users. Our proposed method, Magic3DSketch, employs a novel technique that encodes sketches to predict a 3D mesh, guided by text descriptions and leveraging external prior knowledge obtained through text and language-image pre-training. The integration of language-image pre-trained neural networks complements the sparse and ambiguous nature of single-view sketch inputs. Our method is also more useful and offers higher degree of controllability compared to existing text-to-3D approaches, according to our user study. Moreover, Magic3DSketch achieves state-of-the-art performance in both synthetic and real dataset with the capability of producing more detailed structures and realistic shapes with the help of text input. Users are also more satisfied with models obtained by Magic3DSketch according to our user study. Additionally, we are also the first, to our knowledge, add color based on text description to the sketch-derived shapes. By combining sketches and text guidance with the help of language-image pretrained models, our Magic3DSketch can allow novice users to create custom 3D models with minimal effort and maximum creative freedom, with the potential to revolutionize future 3D modeling pipelines.