 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurator: Efficient Vector Search with Low-Selectivity Filters
Jan 07, 2026Embedding-based dense retrieval has become the cornerstone of many critical applications, where approximate nearest neighbor search (ANNS) queries are often combined with filters on labels such as dates and price ranges. Graph-based indexes achieve state-of-the-art performance on unfiltered ANNS but encounter connectivity breakdown on low-selectivity filtered queries, where qualifying vectors become sparse and the graph structure among them fragments. Recent research proposes specialized graph indexes that address this issue by expanding graph degree, which incurs prohibitively high construction costs. Given these inherent limitations of graph-based methods, we argue for a dual-index architecture and present Curator, a partition-based index that complements existing graph-based approaches for low-selectivity filtered ANNS. Curator builds specialized indexes for different labels within a shared clustering tree, where each index adapts to the distribution of its qualifying vectors to ensure efficient search while sharing structure to minimize memory overhead. The system also supports incremental updates and handles arbitrary complex predicates beyond single-label filters by efficiently constructing temporary indexes on the fly. Our evaluation demonstrates that integrating Curator with state-of-the-art graph indexes reduces low-selectivity query latency by up to 20.9x compared to pre-filtering fallback, while increasing construction time and memory footprint by only 5.5% and 4.3%, respectively.
PaVeRL-SQL: Text-to-SQL via Partial-Match Rewards and Verbal Reinforcement Learning
Sep 08, 2025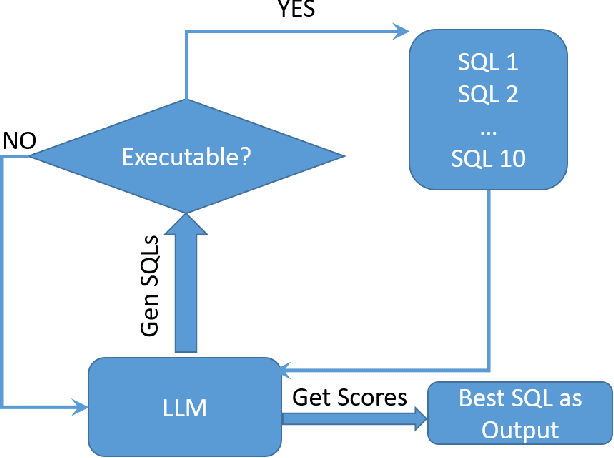
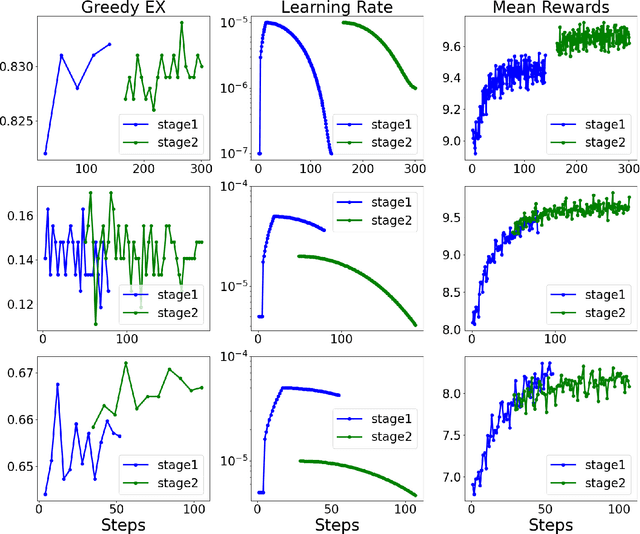
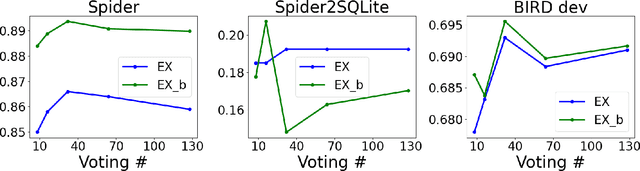
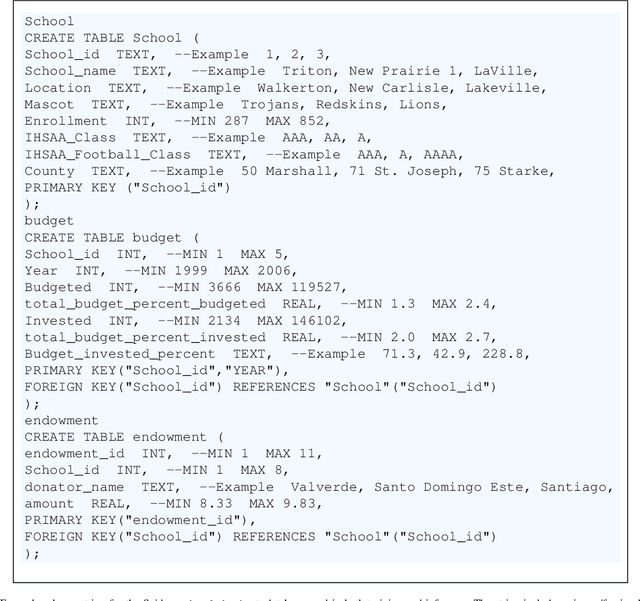
Text-to-SQL models allow users to interact with a database more easily by generating executable SQL statements from natural-language questions. Despite recent successes on simpler databases and questions, current Text-to-SQL methods still suffer from low execution accuracy on industry-scale databases and complex questions involving domain-specific business logic. We present \emph{PaVeRL-SQL}, a framework that combines \emph{Partial-Match Rewards} and \emph{Verbal Reinforcement Learning} to drive self-improvement in reasoning language models (RLMs) for Text-to-SQL. To handle practical use cases, we adopt two pipelines: (1) a newly designed in-context learning framework with group self-evaluation (verbal-RL), using capable open- and closed-source large language models (LLMs) as backbones; and (2) a chain-of-thought (CoT) RL pipeline with a small backbone model (OmniSQL-7B) trained with a specially designed reward function and two-stage RL. These pipelines achieve state-of-the-art (SOTA) results on popular Text-to-SQL benchmarks -- Spider, Spider 2.0, and BIRD. For the industrial-level Spider2.0-SQLite benchmark, the verbal-RL pipeline achieves an execution accuracy 7.4\% higher than SOTA, and the CoT pipeline is 1.4\% higher. RL training with mixed SQL dialects yields strong, threefold gains, particularly for dialects with limited training data. Overall, \emph{PaVeRL-SQL} delivers reliable, SOTA Text-to-SQL under realistic industrial constraints. The code is available at https://github.com/PaVeRL-SQL/PaVeRL-SQL.
Let Human Sketches Help: Empowering Challenging Image Segmentation Task with Freehand Sketches
Jan 31, 2025



Sketches, with their expressive potential, allow humans to convey the essence of an object through even a rough contour. For the first time, we harness this expressive potential to improve segmentation performance in challenging tasks like camouflaged object detection (COD). Our approach introduces an innovative sketch-guided interactive segmentation framework, allowing users to intuitively annotate objects with freehand sketches (drawing a rough contour of the object) instead of the traditional bounding boxes or points used in classic interactive segmentation models like SAM. We demonstrate that sketch input can significantly improve performance in existing iterative segmentation methods, outperforming text or bounding box annotations. Additionally, we introduce key modifications to network architectures and a novel sketch augmentation technique to fully harness the power of sketch input and further boost segmentation accuracy. Remarkably, our model' s output can be directly used to train other neural networks, achieving results comparable to pixel-by-pixel annotations--while reducing annotation time by up to 120 times, which shows great potential in democratizing the annotation process and enabling model training with less reliance on resource-intensive, laborious pixel-level annotations. We also present KOSCamo+, the first freehand sketch dataset for camouflaged object detection. The dataset, code, and the labeling tool will be open sourced.
Bayesian Active Learning for Semantic Segmentation
Aug 03, 2024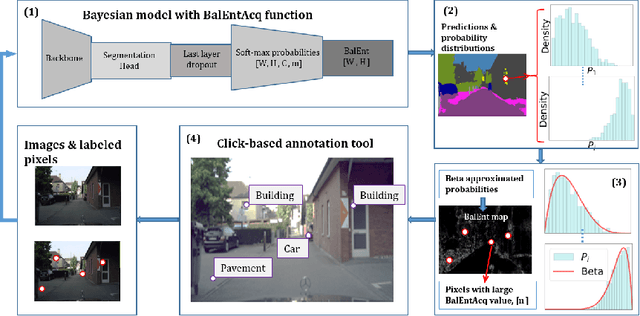



Fully supervised training of semantic segmentation models is costly and challenging because each pixel within an image needs to be labeled. Therefore, the sparse pixel-level annotation methods have been introduced to train models with a subset of pixels within each image. We introduce a Bayesian active learning framework based on sparse pixel-level annotation that utilizes a pixel-level Bayesian uncertainty measure based on Balanced Entropy (BalEnt) [84]. BalEnt captures the information between the models' predicted marginalized probability distribution and the pixel labels. BalEnt has linear scalability with a closed analytical form and can be calculated independently per pixel without relational computations with other pixels. We train our proposed active learning framework for Cityscapes, Camvid, ADE20K and VOC2012 benchmark datasets and show that it reaches supervised levels of mIoU using only a fraction of labeled pixels while outperforming the previous state-of-the-art active learning models with a large margin.
Improving Instruction Following in Language Models through Proxy-Based Uncertainty Estimation
May 10, 2024



Assessing response quality to instructions in language models is vital but challenging due to the complexity of human language across different contexts. This complexity often results in ambiguous or inconsistent interpretations, making accurate assessment difficult. To address this issue, we propose a novel Uncertainty-aware Reward Model (URM) that introduces a robust uncertainty estimation for the quality of paired responses based on Bayesian approximation. Trained with preference datasets, our uncertainty-enabled proxy not only scores rewards for responses but also evaluates their inherent uncertainty. Empirical results demonstrate significant benefits of incorporating the proposed proxy into language model training. Our method boosts the instruction following capability of language models by refining data curation for training and improving policy optimization objectives, thereby surpassing existing methods by a large margin on benchmarks such as Vicuna and MT-bench. These findings highlight that our proposed approach substantially advances language model training and paves a new way of harnessing uncertainty within language models.
RESMatch: Referring Expression Segmentation in a Semi-Supervised Manner
Feb 11, 2024Referring expression segmentation (RES), a task that involves localizing specific instance-level objects based on free-form linguistic descriptions, has emerged as a crucial frontier in human-AI interaction. It demands an intricate understanding of both visual and textual contexts and often requires extensive training data. This paper introduces RESMatch, the first semi-supervised learning (SSL) approach for RES, aimed at reducing reliance on exhaustive data annotation. Extensive validation on multiple RES datasets demonstrates that RESMatch significantly outperforms baseline approaches, establishing a new state-of-the-art. Although existing SSL techniques are effective in image segmentation, we find that they fall short in RES. Facing the challenges including the comprehension of free-form linguistic descriptions and the variability in object attributes, RESMatch introduces a trifecta of adaptations: revised strong perturbation, text augmentation, and adjustments for pseudo-label quality and strong-weak supervision. This pioneering work lays the groundwork for future research in semi-supervised learning for referring expression segmentation.
Curator: Efficient Indexing for Multi-Tenant Vector Databases
Jan 13, 2024Vector databases have emerged as key enablers for bridging intelligent applications with unstructured data, providing generic search and management support for embedding vectors extracted from the raw unstructured data. As multiple data users can share the same database infrastructure, multi-tenancy support for vector databases is increasingly desirable. This hinges on an efficient filtered search operation, i.e., only querying the vectors accessible to a particular tenant. Multi-tenancy in vector databases is currently achieved by building either a single, shared index among all tenants, or a per-tenant index. The former optimizes for memory efficiency at the expense of search performance, while the latter does the opposite. Instead, this paper presents Curator, an in-memory vector index design tailored for multi-tenant queries that simultaneously achieves the two conflicting goals, low memory overhead and high performance for queries, vector insertion, and deletion. Curator indexes each tenant's vectors with a tenant-specific clustering tree and encodes these trees compactly as sub-trees of a shared clustering tree. Each tenant's clustering tree adapts dynamically to its unique vector distribution, while maintaining a low per-tenant memory footprint. Our evaluation, based on two widely used data sets, confirms that Curator delivers search performance on par with per-tenant indexing, while maintaining memory consumption at the same level as metadata filtering on a single, shared index.