 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaVeRL-SQL: Text-to-SQL via Partial-Match Rewards and Verbal Reinforcement Learning
Sep 08, 2025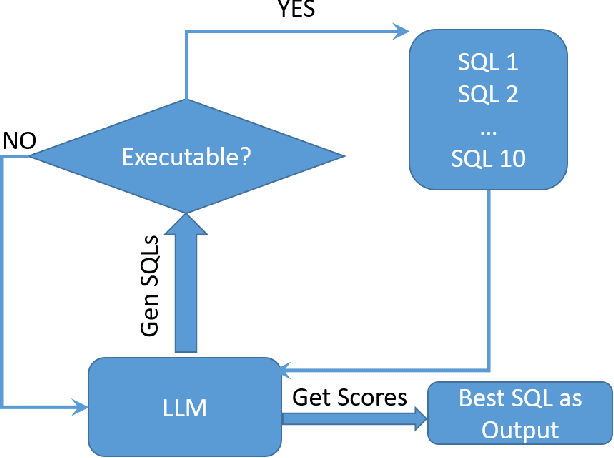
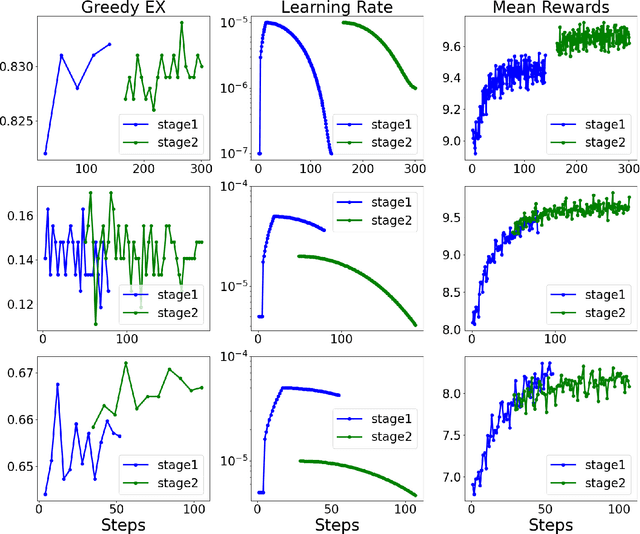
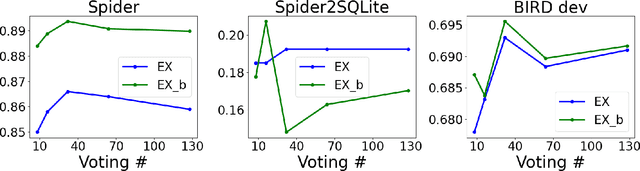
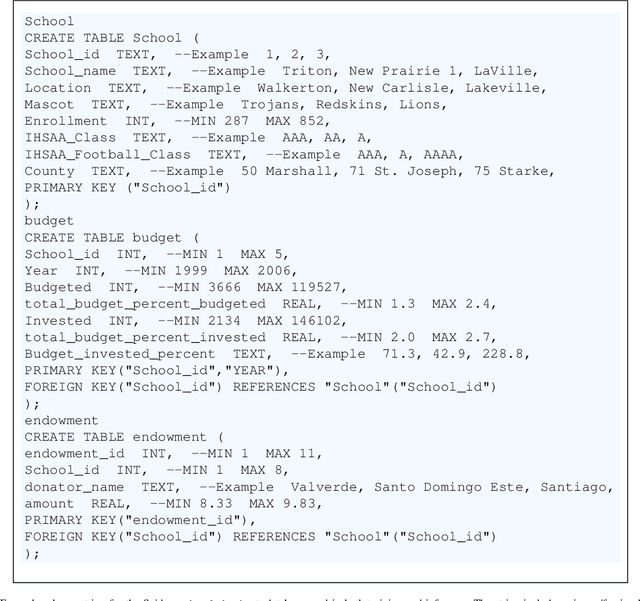
Text-to-SQL models allow users to interact with a database more easily by generating executable SQL statements from natural-language questions. Despite recent successes on simpler databases and questions, current Text-to-SQL methods still suffer from low execution accuracy on industry-scale databases and complex questions involving domain-specific business logic. We present \emph{PaVeRL-SQL}, a framework that combines \emph{Partial-Match Rewards} and \emph{Verbal Reinforcement Learning} to drive self-improvement in reasoning language models (RLMs) for Text-to-SQL. To handle practical use cases, we adopt two pipelines: (1) a newly designed in-context learning framework with group self-evaluation (verbal-RL), using capable open- and closed-source large language models (LLMs) as backbones; and (2) a chain-of-thought (CoT) RL pipeline with a small backbone model (OmniSQL-7B) trained with a specially designed reward function and two-stage RL. These pipelines achieve state-of-the-art (SOTA) results on popular Text-to-SQL benchmarks -- Spider, Spider 2.0, and BIRD. For the industrial-level Spider2.0-SQLite benchmark, the verbal-RL pipeline achieves an execution accuracy 7.4\% higher than SOTA, and the CoT pipeline is 1.4\% higher. RL training with mixed SQL dialects yields strong, threefold gains, particularly for dialects with limited training data. Overall, \emph{PaVeRL-SQL} delivers reliable, SOTA Text-to-SQL under realistic industrial constraints. The code is available at https://github.com/PaVeRL-SQL/PaVeRL-SQL.
ViewPCL: a point cloud based active learning method for multi-view segmentation
Jun 16, 2025We propose a novel active learning framework for multi-view semantic segmentation. This framework relies on a new score that measures the discrepancy between point cloud distributions generated from the extra geometrical information derived from the model's prediction across different views. Our approach results in a data efficient and explainable active learning method. The source code is available at https://github.com/chilai235/viewpclAL.
Bayesian Active Learning for Semantic Segmentation
Aug 03, 2024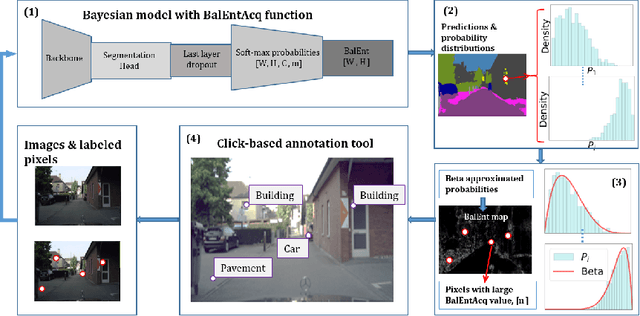



Fully supervised training of semantic segmentation models is costly and challenging because each pixel within an image needs to be labeled. Therefore, the sparse pixel-level annotation methods have been introduced to train models with a subset of pixels within each image. We introduce a Bayesian active learning framework based on sparse pixel-level annotation that utilizes a pixel-level Bayesian uncertainty measure based on Balanced Entropy (BalEnt) [84]. BalEnt captures the information between the models' predicted marginalized probability distribution and the pixel labels. BalEnt has linear scalability with a closed analytical form and can be calculated independently per pixel without relational computations with other pixels. We train our proposed active learning framework for Cityscapes, Camvid, ADE20K and VOC2012 benchmark datasets and show that it reaches supervised levels of mIoU using only a fraction of labeled pixels while outperforming the previous state-of-the-art active learning models with a large margin.
Improving Instruction Following in Language Models through Proxy-Based Uncertainty Estimation
May 10, 2024



Assessing response quality to instructions in language models is vital but challenging due to the complexity of human language across different contexts. This complexity often results in ambiguous or inconsistent interpretations, making accurate assessment difficult. To address this issue, we propose a novel Uncertainty-aware Reward Model (URM) that introduces a robust uncertainty estimation for the quality of paired responses based on Bayesian approximation. Trained with preference datasets, our uncertainty-enabled proxy not only scores rewards for responses but also evaluates their inherent uncertainty. Empirical results demonstrate significant benefits of incorporating the proposed proxy into language model training. Our method boosts the instruction following capability of language models by refining data curation for training and improving policy optimization objectives, thereby surpassing existing methods by a large margin on benchmarks such as Vicuna and MT-bench. These findings highlight that our proposed approach substantially advances language model training and paves a new way of harnessing uncertainty within language models.
Self-Supervised Contrastive Representation Learning for 3D Mesh Segmentation
Aug 08, 2022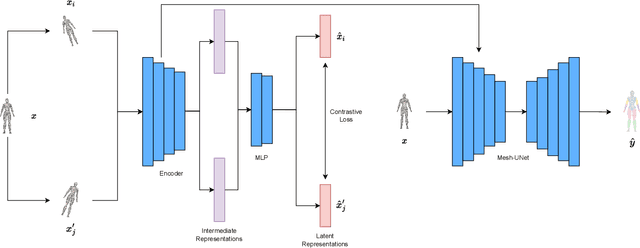
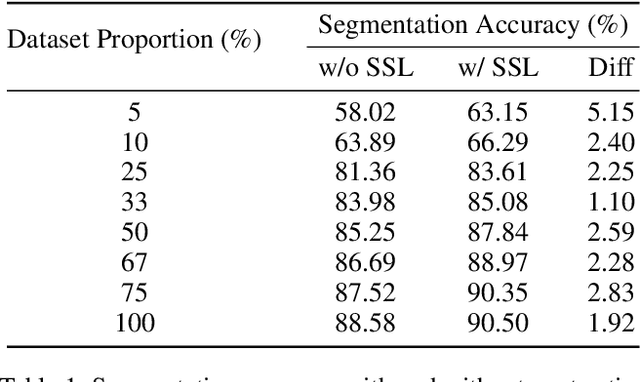
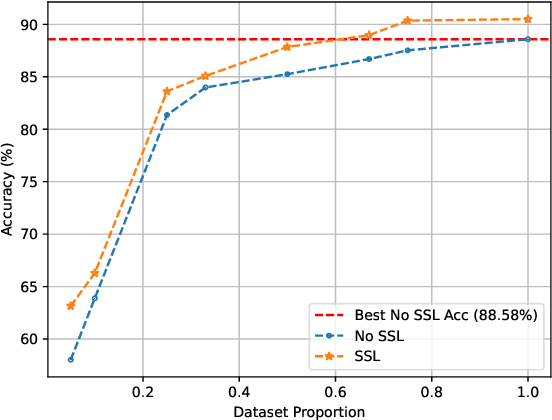
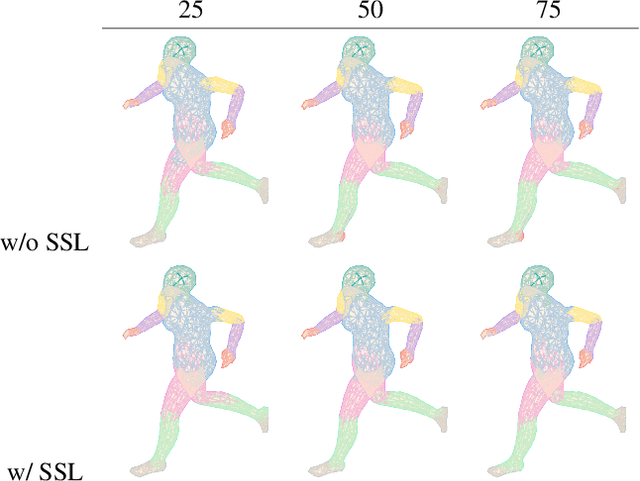
3D deep learning is a growing field of interest due to the vast amount of information stored in 3D formats. Triangular meshes are an efficient representation for irregular, non-uniform 3D objects. However, meshes are often challenging to annotate due to their high geometrical complexity. Specifically, creating segmentation masks for meshes is tedious and time-consuming. Therefore, it is desirable to train segmentation networks with limited-labeled data. Self-supervised learning (SSL), a form of unsupervised representation learning, is a growing alternative to fully-supervised learning which can decrease the burden of supervision for training. We propose SSL-MeshCNN, a self-supervised contrastive learning method for pre-training CNNs for mesh segmentation. We take inspiration from traditional contrastive learning frameworks to design a novel contrastive learning algorithm specifically for meshes. Our preliminary experiments show promising results in reducing the heavy labeled data requirement needed for mesh segmentation by at least 33%.
PatchNet: Unsupervised Object Discovery based on Patch Embedding
Jun 16, 2021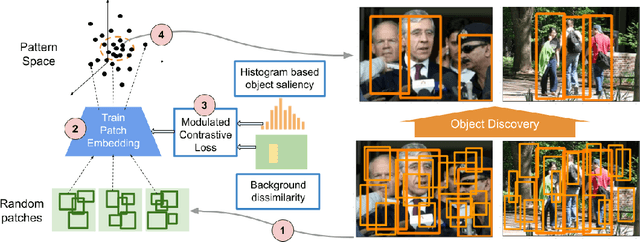
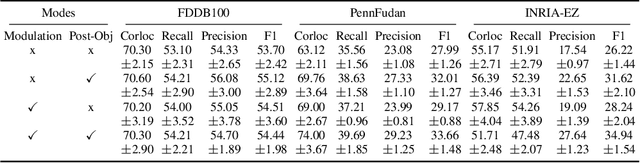
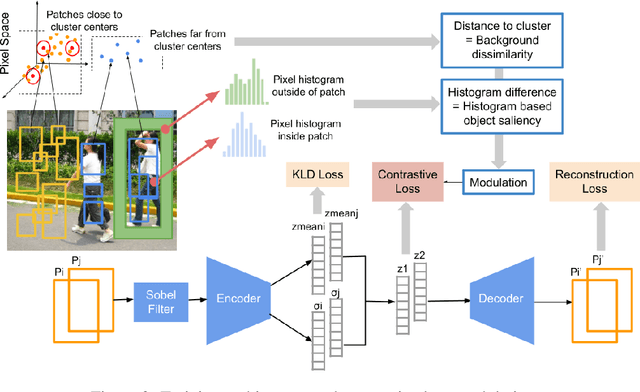
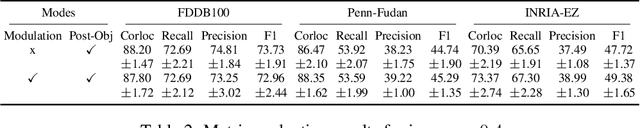
We demonstrate that frequently appearing objects can be discovered by training randomly sampled patches from a small number of images (100 to 200) by self-supervision. Key to this approach is the pattern space, a latent space of patterns that represents all possible sub-images of the given image data. The distance structure in the pattern space captures the co-occurrence of patterns due to the frequent objects. The pattern space embedding is learned by minimizing the contrastive loss between randomly generated adjacent patches. To prevent the embedding from learning the background, we modulate the contrastive loss by color-based object saliency and background dissimilarity. The learned distance structure serves as object memory, and the frequent objects are simply discovered by clustering the pattern vectors from the random patches sampled for inference. Our image representation based on image patches naturally handles the position and scale invariance property that is crucial to multi-object discovery. The method has been proven surprisingly effective, and successfully applied to finding multiple human faces and bodies from natural images.
Highly Efficient Representation and Active Learning Framework for Imbalanced Data and its Application to COVID-19 X-Ray Classification
Feb 25, 2021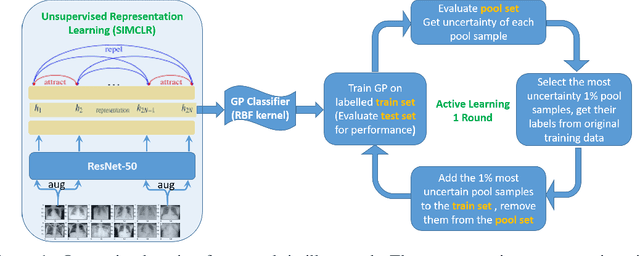
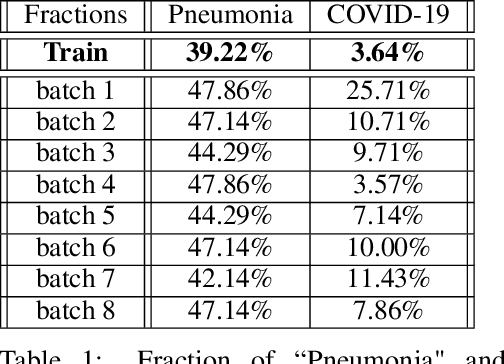
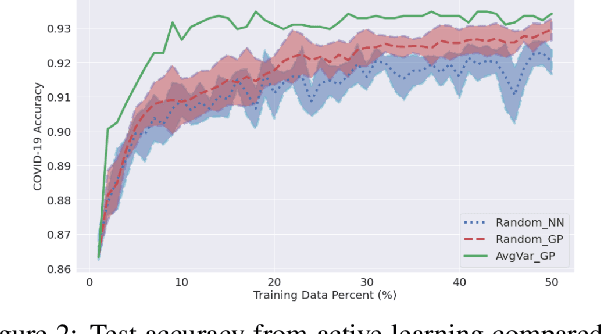

We propose a highly data-efficient classification and active learning framework for classifying chest X-rays. It is based on (1) unsupervised representation learning of a CNN (Convolutional Neural Network) and (2) the GP (Gaussian Process) method. The unsupervised representation learning employs self-supervision that does not require class labels, and the learned features are proven to achieve label-efficient classification. GP is a kernel-based Bayesian approach that also leads to data-efficient predictions with the added benefit of estimating each decision's uncertainty. Our novel framework combines these two elements in sequence to achieve highly data and label efficient classifications. Moreover, both elements are less sensitive to the prevalent and challenging class imbalance issue, thanks to the (1) feature learned without labels and (2) the Bayesian nature of GP. The GP-provided uncertainty estimates enable active learning by ranking samples based on the uncertainty and selectively labeling samples showing higher uncertainty. We apply this novel combination to the data-deficient and severely imbalanced case of COVID-19 chest X-ray classification. We demonstrate that only $\sim 10\%$ of the labeled data is needed to reach the accuracy from training all available labels. Its application to the COVID-19 data in a fully supervised classification scenario shows that our model, with a generic ResNet backbone, outperforms (COVID-19 case by 4\%) the state-of-the-art model with a highly tuned architecture. Our model architecture and proposed framework are general and straightforward to apply to a broader class of datasets, with expected success.